更多优质内容
请关注公众号
请关注公众号

redis集群的故障转移
A. 故障发现
redis集群通过ping/pong消息实现故障发现(redis集群本身自己带有故障转移功能,不需要sentinel),分为主观下线和客观下线。
主观下线:某个节点认为另一个节点不可用
流程:
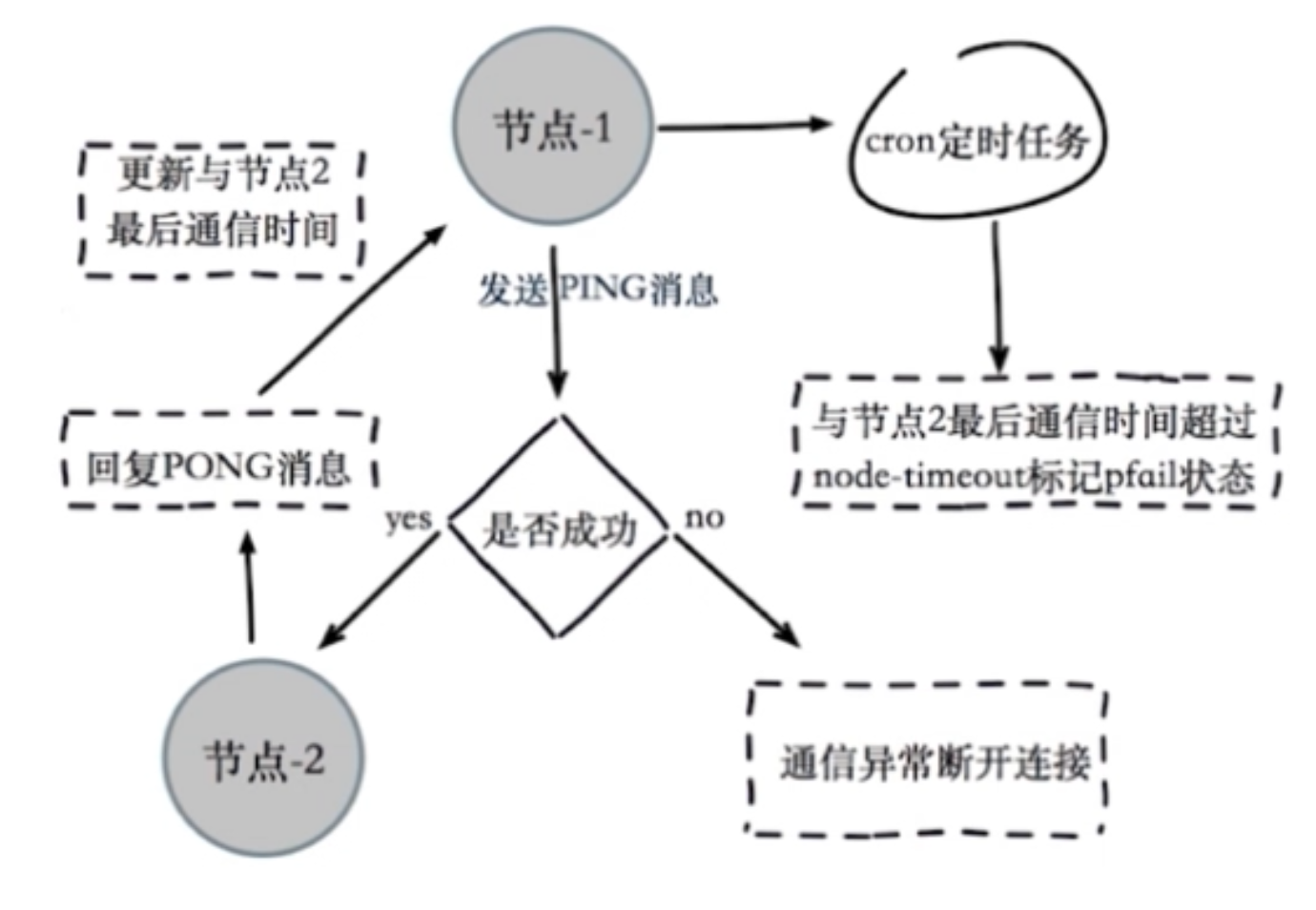
节点A会通过定时任务1每隔一段时间发送ping消息给节点B,节点B接收成功后,会回复一个pong消息给节点A。
节点A接收到pong消息后,会记录与节点B的最后通信时间。
如果节点B挂掉,节点A也会发ping消息给节点B,只是节点B无法恢复pong消息。
除此之外,还有另一个定时任务2,该定时任务会检查此时时间点距离与节点B的最后通信时间有多久,如果这个时间超过了node-timeout这个时间,那么节点1会对节点2标记pfail状态,即节点A认为节点B主观下线。
客观下线:
.png)
当半数以上持有槽的主节点(从节点不算)都标记某节点主观下线即为客观下线。
此时,会通知集群内所有节点标记故障节点为客观下线状态;并且通知故障节点的从节点触发故障转移流程。
B. 故障恢复
从节点执行 slaveof no one 变为主节点
系统执行 clusterDelSlot 撤销故障节点负责的槽,执行 clusterAddSlot 将这些槽分配给从节点
该从节点向集群广播自己的pong消息,表明自己已经替换了故障节点。
C. 故障转移
现在在已经打开了6台节点(3主3从),并且已经分配好了槽的基础上:
I. 查看一下任意一个主节点的pid
cat redis_7000.pid # 查看7000节点的pid
或者
ps -aux | grep redis
II. 先写一个脚本往集群里面写入数据
# coding=utf-8
from rediscluster import RedisCluster
from time import sleep
startup_nodes = [{'host':"127.0.0.1", "port":7000}]
rc = RedisCluster(startup_nodes=startup_nodes, decode_responses=True)
print("连接成功")
print(rc.connection_pool.nodes.nodes)
with open('missed_key.txt', 'a') as f:
for i in range(100):
try: # 默认写入redis
key = "test" + str(i)
rc.set(key, key)
print("Key:" + key + " has been saved")
except BaseException as e: # 如果有节点宕机,则将key暂时写入文件
print(e)
f.write(key + "\n")
print("Key:" + key + " fail")
sleep(0.3)
rc.close() # 关闭连接
III. 运行上面的python脚本,执行kill -9 pid,杀死7000这台主节点。
结果如下:
连接成功
{'127.0.0.1:7005': {'host': '127.0.0.1', 'port': 7005, 'name': '127.0.0.1:7005', 'server_type': 'master'}, '127.0.0.1:7001': {'host': '127.0.0.1', 'port': 7001, 'name': '127.0.0.1:7001', 'server_type': 'slave'}, '127.0.0.1:7002': {'host': '127.0.0.1', 'port': 7002, 'name': '127.0.0.1:7002', 'server_type': 'master'}, '127.0.0.1:7003': {'host': '127.0.0.1', 'port': 7003, 'name': '127.0.0.1:7003', 'server_type': 'slave'}, '127.0.0.1:7004': {'host': '127.0.0.1', 'port': 7004, 'name': '127.0.0.1:7004', 'server_type': 'master'}, '127.0.0.1:7000': {'host': '127.0.0.1', 'port': 7000, 'name': '127.0.0.1:7000', 'server_type': 'slave'}}
Key:test17 has been saved
Key:test18 has been saved
Key:test19 has been saved
Key:test20 has been saved
Key:test21 has been saved
Key:test22 has been saved
Key:test23 has been saved
TTL exhausted. # 此时我将7000主节点进程杀死
Key:test24 fail
Key:test25 has been saved
Key:test26 has been saved
Key:test27 has been saved
TTL exhausted.
Key:test28 fail
Key:test29 has been saved
Key:test30 has been saved
Key:test31 has been saved
Key:test32 has been saved
TTL exhausted.
Key:test33 fail
Key:test34 has been saved # 此时7000的从节点7003已经顶替7000,完成故障转移
Key:test35 has been saved
Key:test36 has been saved
Key:test37 has been saved
Key:test38 has been saved
Key:test39 has been saved
Key:test40 has been saved
Key:test41 has been saved
Key:test42 has been saved
Key:test43 has been saved
执行
redis-cli -p 7001 cluster nodes
观察各个节点的主从关系,发现7001从从节点变为主节点。
================================
redis集群常见问题
1.集群完整性
集群完整性是指这个参数:
cluster-require-full-coverage
默认为yes,之前我设置的为no
如果为yes,那么只要有1个节点发生故障,则整个集群都会被下线。此时往集群中写入数据的时候,会提示:
(error) CLUSTERDOWN The cluster is down
但是在现实中这是不能容忍的,所以一般设为no
2.带宽消耗
redis官方建议集群的节点数不要超过1000个,节点数越多,消耗的带宽会越多,因为集群在运行的过程中每台机器会不停的发送ping/pong消息给集群中的其他机器,这会带来不可忽视的带宽消耗(也就是说redis集群带宽的消耗是由于ping/pong消息的发送)。
影响Redis集群的带宽消耗的因素:
a.消息发送频率:节点发现与节点最后通信时间超过cluster-node-timeout/2时会直接发送ping消息(也就是说,任意的2台机器之间至多等cluster-node-timeout/2的时间就会发送一次ping/pong消息,所以控制cluster-node-timeout这个参数可以直接影响到带宽的消耗。而且节点数越多,每台机器发送消息的频率也会越高)。
b.消息数据量:slots槽数组(2KB)和整个集群1/10的状态数据(10个节点状态数据约1KB)。所以集群节点数量越多,状态数据量也会越多。
c.节点部署的机器规模:集群分布的机器越多且每台机器划分的节点数越均匀,则集群内整体的可用带宽越高。
这里说的节点就是redis节点,机器就是机器,并不是一个节点就在一台机器上面。如果特定数量的节点放在越多的机器上,消耗的带宽越高。
一个例子:
当200个节点分布在20台机器(每台10个节点)
cluster-node-timeout=15000, ping/pong带宽为25Mb
cluster-node-timeout=20000, ping/pong带宽为15Mb
按照我的理解:
假如一台机器只放1个节点,且1/2个cluster-node-timeout时间内某一个节点要和集群内其他节点完成一次ping/pong,那么在这个时间内整个集群的发送消息的次数就是 n! 次(n阶乘次)。所以此时带宽消耗和节点数量的关系是接近呈指数增长的一个关系。
优化:
a. 避免“大”集群:就是说避免多业务使用一个集群,大业务可以使用多个集群(前提是这多个集群内的数据是没有关联的)
b.cluster-node-timeout: 带宽和故障转移速度的均衡。这个参数调的越大,带宽消耗就越小,但是故障转移的时间(应该说是发现故障的时间)就越长。
c.尽量将节点均匀分布到多台机器上:这样既保证了高可用(一台机器挂掉还有其他机器撑着),有保证了带宽消耗较少。
3.Pub/Sub广播(发布订阅在集群中的问题)
publish会在集群的每个节点广播,会严重消耗带宽
解决方法:单独走一套 Redis Sentinel
具体情况作者也没怎么说。
4.数据倾斜和请求倾斜
数据倾斜
就是说集群中有的节点所存的数据量大,有的节点数据量少。
出现数据倾斜有一下原因:
a.节点和槽分配不均,有的节点分配的槽多,有的节点槽少。
可以通过
redis-cli --cluster info ip:port 查看,它会列举出所有主节点的槽的情况
通过
redis-cli --cluster rebalance ip:port
进行均衡,它会将16384个槽进行重新分配,但是这个命令要谨慎操作。
b.不同槽所存的key数量差异较大,有的槽存的key多,有的槽存的key少
CRC16的哈希算法下,分布会比较均匀的。如果出现这种情况可能是由于hash_tag的原因。
可以通过 cluster countkeysinslot {slot} 获取槽对应key的个数
c.包含bigkey,比如有的key存的是内容很大的hash
可以通过在从节点执行命令 redis-cli --bigkey 发现bigkey
d.内存相关配置不一致
请求倾斜
就是用户经常请求某个key,使得请求经常命中到某一个节点。
优化:
避免bigkey
热点key不要用hash_tag
当一致性要求不高时(就是redis中数据更新但是本地可以不那么及时的更新),可以用本地缓存 + MQ
5.集群的读写分离
集群模式的从节点不接受任何读写请求
如果在从节点的客户端进行读取,它会重定向到主节点进行查询数据
Redirected to slot [xxx] located at ip:port
如果想在集群中做读写分离会很复杂,成本非常高,宁愿将分布式的节点数增加也不要对集群进行读写分离。
6.数据迁移
使用
redis-cli import ip:port --cluster-from ip:port --cluster-copy(或者 --cluster-replace)
可以将数据从单机迁移到集群
具体命令可以使用命令
redis-cli --cluster help
查看
也可以查查百度如何具体进行迁移
集群迁移缺点如下:
不支持在线迁移,如果你的redis服务还开着的情况下进行迁移,此时用户写入的新数据无法导入到集群中。
单线程迁移,影响速度
不支持断点续传
集群 VS 单机
key批量操作支持有限:如mget和mset所操作的key必须在一个slot中。
不支持多数据库:集群模式下只有一个db
复制只支持1层:不支持树形复制结构
分布式redis不一定好,因为很多业务的QPS是达不到这么高的,也就是说很多业务不需要。而且redis分布式无法跨节点使用mget,keys,scan,flush,sinter这样的命令。跨节点也无法使用事务。智能客户端的维护也很复杂,要建立更多的连接池。
所以很多情况下,redis sentinel + 一主多从的架构就已经足够好了,它是高可用的而且也有多个redis节点可以减轻读的压力,程序通过请求sentinel节点来对redis节点进行读写操作。