更多优质内容
请关注公众号
请关注公众号

ES分布式机制的透明特性
ES隐藏了很多分布式机制,例如
分片机制:插入了一条document,这个document会注入到哪个shard中;
集群发现机制:启动一个ES节点后,该ES节点可以自动发现集群并加入到该集群中;
shard负载均衡:多个shard在多个节点的分配策略;
shard副本、路由请求、集群扩容、扩容缩容时shard重新分配等等。
master节点
ES集群的众多node中,会有一个master节点。master节点除了接收用户请求外,还负责管理ES集群的元数据,如索引的元数据,集群节点的元数据等。master节点会被集群自动选出。
master节点不承载所有请求,因此不会成为单点瓶颈。
节点对等的分布式架构
ES节点具有如下特性:
节点对等:每个节点都能接收请求。
自动请求路由和响应收集:如果用户的请求发送给集群中的节点A,节点A发现用户要查找的数据在节点B,则节点A会将请求转发B,并收集B的响应返回给用户。
shard机制
一个index包含多个shard,每个shard是一个最小的数据容纳单元,同时一个shard就是一个Lucene实例,具有完整建立索引和处理请求的能力,因此也是一个最小工作处理单元。集群增减节点时,shard会在nodes之间迁移从而负载均衡。
shard分为primary shard和replica shard,后者是前者的副本,负责容错和承担读请求负载。
每一个document只会存在于某一个primary shard和对应的replica shard,不可能存在于多个primary shard中。
primary shard的数量在创建索引是就已经固定了,不能更改,如需更改只能重新建索引,replica shard的数量则可以随时修改,但只能按倍数增加或减少。
举个例子,创建一个index时,如果设置该索引的primary shard的数量是3,那么即使集群有4个node,也不会多创建一个shard保证每个node分布有数据。如果设置了replica shard的数量为1,则表示每个primary shard都对应一个replica shard,共3个replica shard,完整数据有2份;如果设置了replica shard的数量为2,则表示有6个replica shard,完整数据有3份。
primary shard的数量默认为5,replica默认是1,即默认共10个shard,5个primary和5个replica。
primary shard不能和自己的replica shard放在同一个节点上,否则宕机时主数据和副本数据同时丢失。例如 primary1~3和replica1~3,primary1不能与replica1放在同一节点,但primary1可以与replica2放在同一节点。
可以在创建Index时指定shard的数量。
PUT /test_index { "setting":{ "number_of_shards":3, "number_of_replicas":1 } }
单node环境的shard分布
单node环境下,创建一个index,并规定包含3个primary shard和3个replica shard。
PUT /test_index { "setting":{ "number_of_shards":3, "number_of_replicas":1 } }
此时集群status是yellow,实际上只有3个primary shard分配到仅有的一个node,其他3个replica shard无法分配,相当于集群中不存在replica shard。
双node环境下的shard分布
在上面的单node情景下,增加一个新node并且新node加入到集群里之后,ES会自动在新node创建3个replica shard,并且自动拷贝数据到replica shard中。
ES横向扩容过程
假设一开始有2个node,3 primary + 3 replica = 6 shard。此时的shard的分布情况如下。
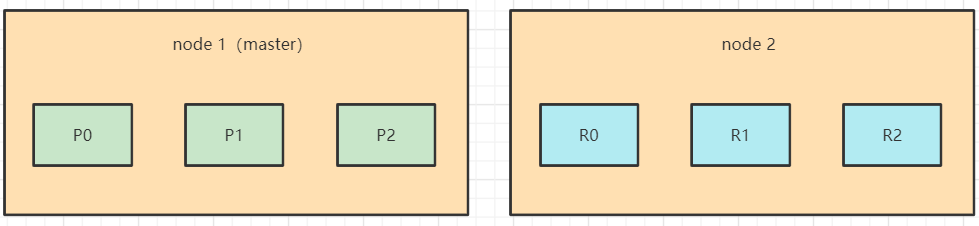
扩容一个node之后,ES会自动迁移一部分shard到新node,使每个node的shard数量尽量接近。

每个node被分配的shard越少,每个shard持有的IO/CPU/Memory资源越多,或者说一台能力固定的机器要处理的数据量越少,检索性能越好。
扩容是有极限的,极限取决于shard的数量,对于一个3 primary + 3 replica的ES服务,最多只能扩容到6台机器,每个shard占有1台机器的资源,性能最好。
如果想要在继续扩容,虽然我们无法修改primary的数量,但可以更改replica的数量。例如再增加3个replica,此时最多可以扩容到9台机器。
ES的容错性
ES的容错性是指允许宕机的节点个数。ES容错性和机器台数以及shard个数有关。
例如,在3台机器(假设每台机器只启动1个ES进程,即只有3个node)和6个shard的组合之下,只能容忍1台机器发生宕机。
如果shard数量不变,扩容到6台机器,则最多可以容忍3台机器宕机(但运气不好的话,2台机器宕机也会造成集群不可用,比如P0和R0同时宕机)。
如果机器数量不变,增加3个replica shard,变成共9个replica shard,则可以容忍2台机器宕机,如下图所示。

假设主节点宕机,会选取其他节点(假设node2)为master,并将缺失shard对应的replica shard 在新master中晋升为primary shard(对应node2中的R0和R2晋升为P0和P2)。