更多优质内容
请关注公众号
请关注公众号

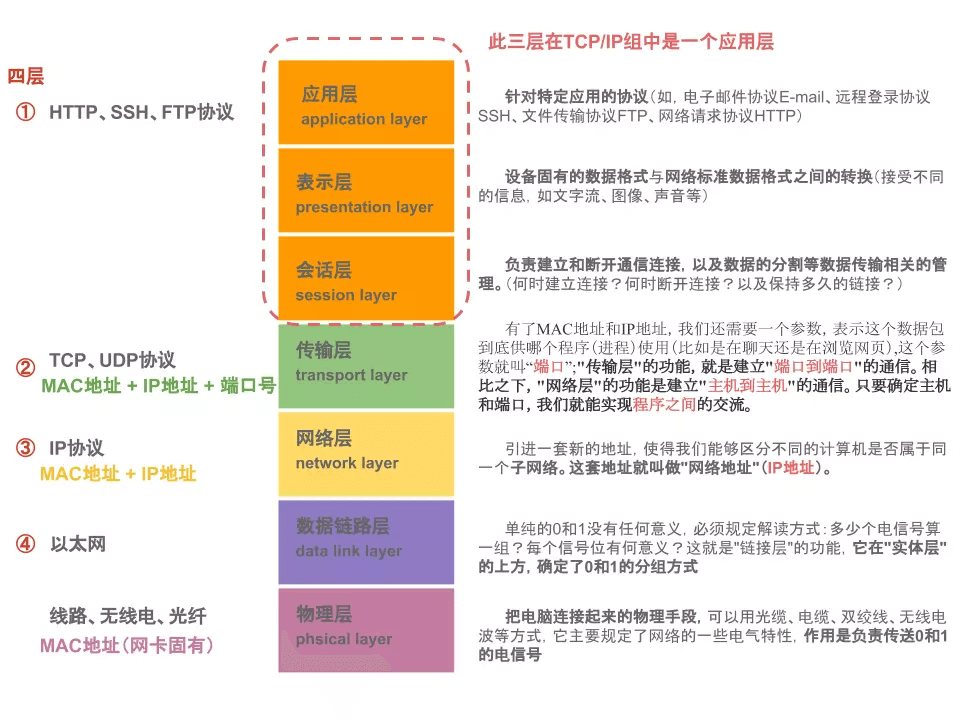
七层网络模型又称为OSI七层网络模型
具体的七层自上而下是:
应用层、表示层、会话层、传输层、网络层、数据链路层、物理层
有时候人们会将表示层和会话层与应用层合并为一个层统称为应用层,于是就有了TCP/IP五层模型(自上而下):
应用层、传输层、网络层、数据链路层、物理层
其中应用层 = 七层模型中的应用层+表示层+会话层
每一层都对应着一些只属于自己这一层的协议:
以五层模型来说:
应用层对应HTTP、FTP、SSH等协议
传输层对应TCP、UDP协议
网络层是IP协议
数据链路层有SLIP、CSLIP、PPP、MTU
物理层有ISO2110、IEEE802、IEEE802.2
具体你不用知道有哪些协议,你只需要知道每一层有属于自己的协议就行,然后记住一些重要的协议如HTTP/SSH/TCP/UDP/IP协议。
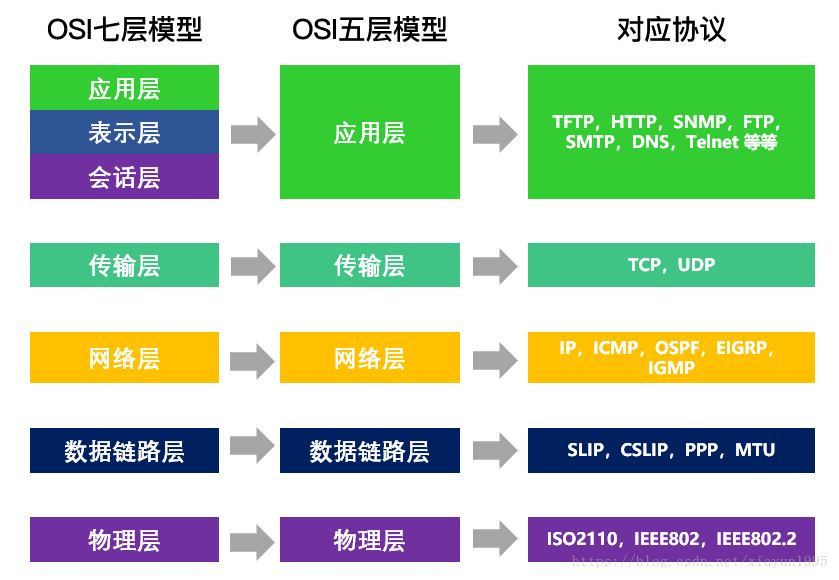
七层网络模型对应协议
============================
接下来介绍一下,数据传输的过程和每一层的作用:
假如有两台机器A,B;A是客户端所在的机器,B是服务端所在的机器。那么当A发送一个数据给B的时候,数据会从A的应用层产生---->A的传输层---->A的网络层---->A的数据链路层---->A的物理层---->B的物理层---->B的数据链路层---->B的网络层---->B的传输层---->B的应用层。
在A的每一层中,数据会经过一步步的封装,传到B的每一层会一步步的解封装。这是一个在A自上而下,在B自下而上的过程。
当数据到了B的应用层之后,B的应用程序就可以对数据进行处理。
传输流程如图:
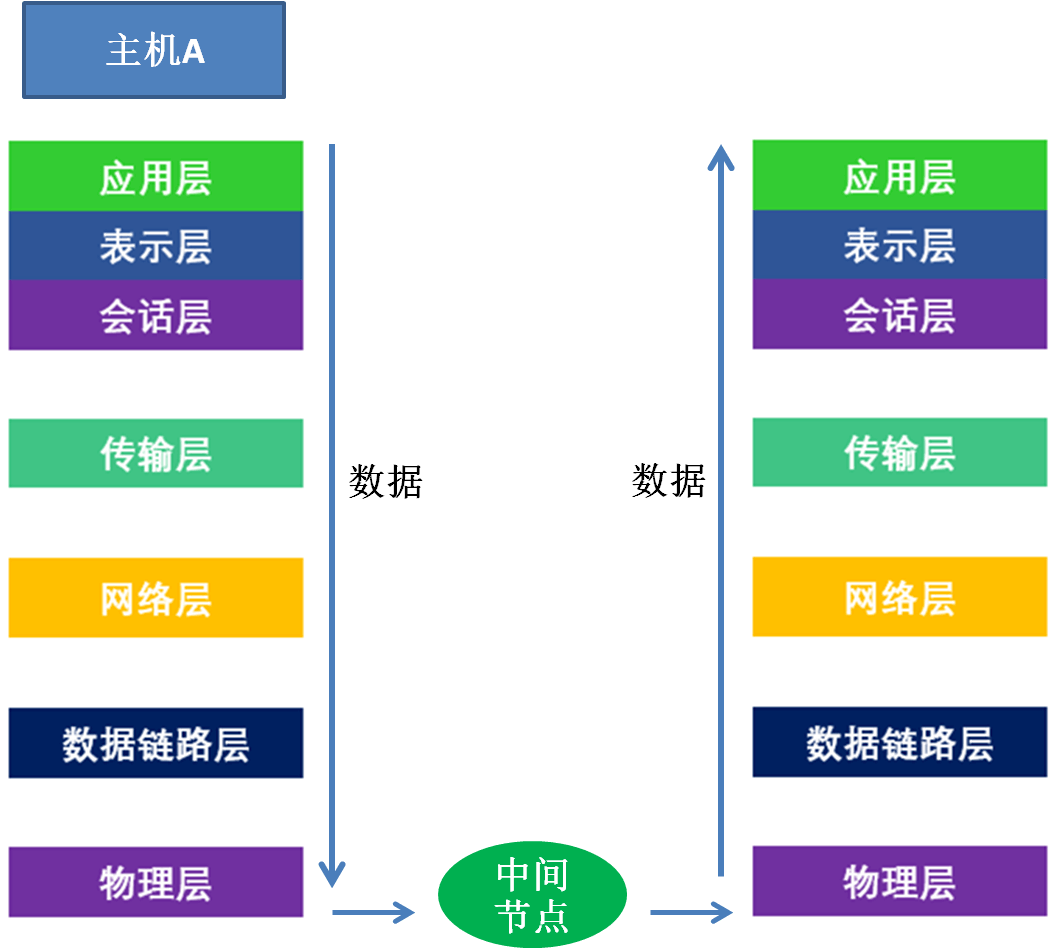
数据包传输流程
每一层对应的设备如下图:
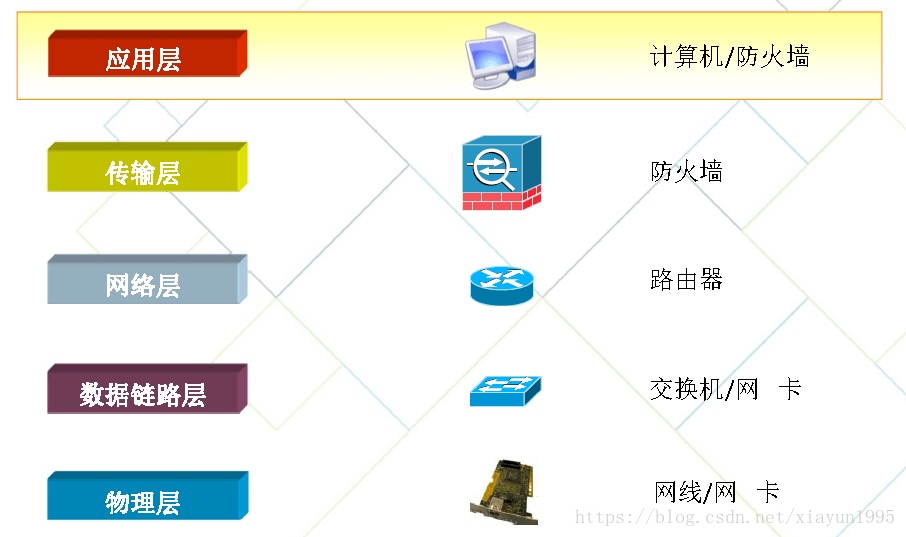
每一层对应的设备
下面介绍每一层的具体作用:
应用层
应用层的主体是程序进程,应用层协议定义的是应用进程间通信和交互的规则。
在我的理解中,例如客户端的应用层的程序就是浏览器,而服务端的应用层的程序是Apache或者Nginx。客户端使用浏览器浏览网页的时候,浏览器会打开一个端口(假设是10000)用来发数据出去,而服务端的Apache或者nginx会打开一个80端口来接收请求。
当然数据不会从A的应用层直接传到B的应用层。中间还有一段很长的路要走。
假如我们在主机A上发送一段字符串作为要传输给B的数据,应用层将这条消息处理为一个五层的数据包,然后传给A的传输层。
传输层
传输层会对应用层发过来的五层数据包进行进一步的封装,为该数据包添加一个TCP/UDP头部(TCP或者UDP二者其中一个,具体取决于软件选择那个协议),这个头部信息包含了源端口号(A的端口号10000)和目的端口号(80)。
这样一来,系统就知道出发点的端口和目的地的端口。
网络层
知道起点和终点的端口还不够,还需要知道起点和终点的IP地址。
网络层也有一个很重要的协议——IP协议,当数据包到网络层时,网络层会对该数据包添加一个IP包头,其中含有数据包的源IP和目标IP,数据传输的过程中就是根据这个目标IP找到需要通信的主机B的。
前三层的数据包很重要,在一个包中称为上三层数据,是最有价值的包,不能被别人篡改,一旦被篡改就有可能造成通信出错或者信息泄露。(例如本来A发给B的数据,上三层数据被篡改后发给了C)
接下来我们要通过介质将数据包传输,这就是数据链路层和物理层要做的事。
数据链路层
在第二层会给上三层数据包加上一个二层头部(MAC子层)和二层尾部(FCS)。
MAC子层头部:
含有源MAC地址和目标MAC地址字段,关于这一块的内容我们在后面的整理中再学习,这里我们只需要知道每一台主机的MAC地址是唯一固定的。
FCS:帧校验序列
上三层加上帧头之后,对中间的信息数据会使用一个循环校验算法,最终得到一个固定的值,我们可以利用这个值和FCS得出这个数据包的内容是否缺失。
简单来说,数据链路层还是在给数据包添加地址信息。
当上三层的数据包到了数据链路层,就意味着这个信息已经成功到达计算机的网卡。
物理层
在物理层上所传数据的单位是比特。发送方发送1(或0)时,接收方应当收到1(或0)而不是 0 (或1)。 因此物理层要考虑用多大的电压代表 “ 1 ” 或 “ 0飞以及接收方如何识别出发送方所发送的比特。
到了物理层,数据包变成了比特流,以电脉冲的形式传输到交换机,最后到达目标主机B的物理层。
你可以简单的认为,是电流在电线里面传输。
在B中,信息会从物理层往上传到B的应用层。这个过程是上面的过程的一个逆操作。
具体流程图如下:
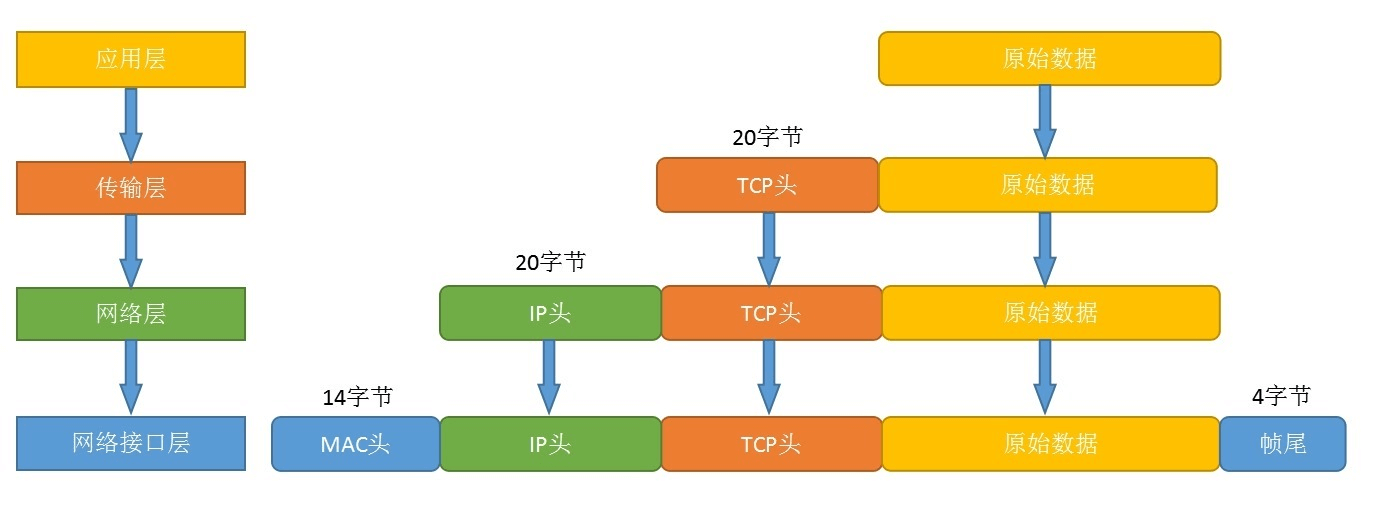
传输流程
每一层的作用
==========================
一次Http请求都发生了什么:
1.用户浏览器输入网址
2.浏览器拿到网址去请求IP
3.向目标IP 发送TCP连接 3次握手
4.服务器解析请求,并返回处理好的 html 页面(字符串)
5.浏览器按照规则解析渲染画面
6.四次挥手,连接结束
三次握手的过程:
第一次握手:发送端先发送一个带SYN (synchronize) 同步标志的数据包给 Server,在一定时间内等待接收回复
第二次握手:服务端接收到SYN数据包后,返回一个带 SYN/ACK (acknowledgement charactor) 确认字符 标志的数据包来表示确认收到消息。
第三次握手:接收方接收到Server的确认消息后,再发送一个带ACK标志的数据包给接收端,表示握手成功
注意:上述过程都有一个等待时间,如果在等待时间内Server、或者Client 没有回复,本次请求视作失败,再次请求。Server没有回复的原因可能是栈满了
- 建立连接成功后,浏览器才会向WEB服务器发送一个HTTP请求
四次挥手的过程
客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
服务器-关闭与客户端的连接,发送一个FIN给客户端
客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
经过上面四次挥手后,连接结束。
============================================
一次HTTP请求所包含的报文:
假如我们请求一张图片
.png)
使用Chrome的开发者工具可以看到如下请求:
.png)
我们关注的是第一个请求,对一张jpg图片的请求。我们使用wireshark抓包工具捕获到发送的数据包:
.png)
红色框框内就是一次完整http请求所发送的数据包,在这里是10条,另外那两条不在红框内的是对favicon.ico文件的请求,咱们不去关注这两条。
首先在正式发送请求之前,会进行三次握手,也就是图中No 2558/2582/2583 这三条。
No.2558 第一次握手 [TCP协议]
客户端先发送一个带SYN (synchronize) 同步标志的数据包给 Server,在一定时间内等待接收回复。
绿色框框内的是端口号,61036是客户端浏览器开的端口。8080是服务端nginx开的端口
No.2582 第二次握手 [TCP协议]
服务端接收到SYN数据包后,返回一个带 SYN/ACK (acknowledgement charactor) 确认字符 标志的数据包给客户端来表示确认收到消息。
No.2583 第三次握手 [TCP协议]
客户端接收到Server的确认消息后,再发送一个带ACK标志的数据包给服务端,表示握手成功
----------- 接下来进入HTTP请求阶段-----------
No.2603 发送HTTP请求 [HTTP协议]
客户端发送一个Data报文给服务端,这个Data报文就是我们经常用F12,在浏览器开发者工具那里看到的请求信息,也是我们常说的HTTP请求。这一过程才真的是从客户端的应用层到服务端的应用层。
No.2639 服务端确认收到HTTP请求 [TCP协议]
当服务端接受到Data报文,服务端的TCP层(传输层)会发送一个ACK标志的数据包给客户端,表示接受到请求了(这件事是系统内核做的,而不是nginx或者Apache去做的),这个过程数据包是从服务端的TCP层传到客户端的TCP层,也是没有应用层的参与的。然后系统内核把请求交给nginx或者Apache去处理(这才是nginx和Apache做的)。
No.2640 服务端返回HTTP响应 [HTTP协议]
当请求处理完以后,服务端的nginx会把响应返回给客户端,这个过程是数据从服务端应用层到客户端应用层的过程。从上图中可看出该响应返回的状态码是304。
----------- 接下来进入四次分手的阶段-----------
No.2826 [TCP协议]
客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
No.2827 [TCP协议]
服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号
No.2844 [TCP协议]
服务器-关闭与客户端的连接,发送一个FIN给客户端
No.2854 [TCP协议]
客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
经过上面四次挥手后,连接结束。
PS:
上面的三次握手都是从tcp层(传输层)开始而不是从http层(应用层)开始的。也就是说数据从 客户端的传输层-->网络层-->数据链路层-->客户端的物理层-->服务端的物理层-->数据链路层->网络层-->服务端的传输层
没有应用层的参与
注意,三次握手的处理是Linux系统内核本身处理的而不是Apache或者nginx这样的进程去处理。因为三次握手是tcp层的通信,还没到应用层。Apache和nginx处理的是之后的HTTP请求。
三次握手之后,才算建立连接成功,浏览器才会向WEB服务器发送一个HTTP请求,也就是图中No.2826这条请求。这条请求是客户端开始向服务端请求图片。
以上是一次完整的HTTP请求会包含的报文和数据包。
上面只是请求一个静态资源,如果是请求一个页面,那么情况会更复杂,因为一个页面包含很多的js/css/image这样的静态资源,还有ajax请求等。
==========================================================
从上面的内容我们知道,客户端和服务端必须通过TCP三次握手建立了连接之后,才能发送请求给服务端。连接就像是通道,请求就像是货物,所以建立了连接才能发送请求。
建立了连接才能发送请求
建立了连接才能发送请求
建立了连接才能发送请求
重要的事情说3遍。
那么问题来了
1.现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?一个 TCP 连接可以发送几个 HTTP 请求?
在 HTTP/1.0 中,一个TCP连接发送一个请求并接收到响应后断开。但是很多浏览器会在建立连接的时候使用 Connection: keep-alive 这个header,意思是说,完成这个 HTTP 请求之后,不要断开 HTTP 请求使用的 TCP 连接,而是维持一段时间不断开,这样这个连接就可以发送多个请求。
既然维持 TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,才会一个连接只能发送一个请求。
刚刚说使用keep-alive可以维持连接一段时间不断开,那么这个时间有多长,这是由服务端决定的。例如nginx的keepalive-timeout参数指定默认75s内没有新的请求发过来就会断开连接。但是如果还有新的请求发过来就不会断开。
当然,一个TCP连接能发送的请求也是有限的,nginx的keepalive_requests 100;就限定一个TCP连接上最多执行多少次http请求
所以打开一个页面的时候,这个页面的静态资源的请求有很多都是通过一个tcp连接传输到服务器的。
2.一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
在 HTTP/1.1 存在 Pipelining 技术可以完成这个多个请求同时发送,但是由于浏览器默认关闭,所以可以认为这是不可行的。
在 HTTP2 中由于 Multiplexing 特点的存在,多个 HTTP 请求可以在同一个 TCP 连接中并行进行。
那么在 HTTP/1.1 时代,浏览器是如何提高页面加载效率的呢?主要有下面两点:
A. 维持和服务器已经建立的 TCP 连接,在同一连接上顺序处理多个请求。
B. 和服务器建立多个 TCP 连接。
3.为什么有的时候刷新页面不需要重新建立 SSL 连接?
在第一个问题的讨论中已经有答案了,TCP 连接有的时候会被浏览器和服务端维持一段时间。TCP 不需要重新建立,SSL 自然也会用之前的。
4.浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
我们知道TCP连接短时间不会断开,那么是不是意味着一个页面的所有资源的请求都可以通过这个TCP连接进行呢?
如果真的这么干,那么用户就会等图片、js、css加载等到天昏地暗了。
这是因为,我们刚刚说过,如果是HTTP/1.1的话,一个TCP连接无法同时发送多个http请求,只能一个一个的发,再一个一个的接收请求。只建立一个TCP连接,请求的速度就会很慢。
此时浏览器对同一个服务器就会开多个TCP连接来发送请求来加快请求速度。
Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
当然,不能对同一个服务器建立太多TCP连接,不然服务端压力会很大的,当然服务端也会有限制。