更多优质内容
请关注公众号
请关注公众号

这里说的性能优化不仅仅是对Nginx调参实现优化,还有对Linux系统内核参数进行修改来提升性能。
分为三部分:
CPU层面的优化(进程调度);
网络层面的优化;
磁盘IO的优化;
优化方法论:
A. 从软件层面提升硬件使用效率:(通过Nginx参数调优)
增大CPU的利用率
增大内存的利用率
增大磁盘IO的利用率
增大带宽的利用率
B. 提升引荐规格(从Linux系统硬件本身下手)
网卡:万兆网卡
磁盘:固态硬盘
CPU:更多核,更大缓存,更优的架构
内存:更快的访问速度
C. 超出硬件性能上线后使用DNS
=========================================
CPU层面的优化:如何高效使用CPU
A. 如何增大Nginx使用CPU的有效时长
1 要让Nginx能够使用全部CPU资源
nginx是一个master主进程和多个worker子进程的架构。接收连接和处理请求都是worker进程的工作。所以worker进程数量应该等于CPU个数
2 使Nginx进程间不做无用功,浪费CPU资源
以下情况Nginx进程会浪费CPU资源:
a. worker进程繁忙时主动让出CPU,例如worker进程间会由于争抢CPU造成资源耗散,当worker进程数量大于CPU个数时会发生这种状况。所以worker进程数量应当等于CPU个数,而且每个worker进程应该绑定一个CPU。
通过 worker_processes number|auto; ,该指令声明开启多少个worker进程,auto表示默认和CPU个数相同。
b. worker进程调用一些API导致主动让出CPU
所以应该拒绝使用类似的使用API的第三方模块
c. 被其他非worker进程争抢资源
可以通过提升worker进程优先级,占用CPU更长的时间
可以减少操作系统上消耗资源的非Nginx进程,比如压缩文件,备份之类的工作可以放在深夜去完成。
关于CPU进程调度(上下文切换):
为何一个CPU可以同时运行多个进程?
表面上看一个CPU可以同时运行好几个程序,也就是运行多个进程,但实际上他们不是同时发生的,CPU会给每一个进程分配一小段时间片,然后所有进程放在一个循环的队列中,每个进程工作了规定时间片的时长后,CPU会切换到队列中的下一个进程工作,而这个时间片的时长很短,所以CPU其实同一时间只能运行一个进程,只不过切换的速度太快让我们看起来像是一起运行的。
例如,有ABC三个进程,每个进程分配的时间片是100毫秒,CPU会处理A进程100ms,然后切换到B进程工作100ms,然后切换到C工作100ms,然后又切换回A工作100ms,循环以上过程。
但是每一次切换都会消耗一点时间,这个上下文切换时间是微秒(us)级别的,但是如果进程数多的话,累计起来的切换时间还是很多的。
如何查看所有进程数:
使用Top命令:
Tasks: 89 total, 2 running, 87 sleeping, 0 stopped, 0 zombie
这里共有89个进程,我们主要关注处于R状态即running和S状态即sleeping的进程数。
R状态:表示正在运行或在运行队列中等待的状态。
S状态:休眠中,受阻或等待某个条件的形成,反正就是处于等待状态。
凡是R状态的进程都是放在队列中准备就绪的进程,也就是说CPU会切换处于R状态的进程为这些进程工作。所以R状态的进程都是消耗CPU的进程,而S状态的进程都是几乎不怎么消耗CPU的进程,就是因为S的进程不在队列中,不会去运行。
当R状态的进程数长时间大于CPU核数时,负载会急速增高。
使用
ps -aux | awk '{if($8~"R") print}'
可以打印出具体的处于R状态的进程。 $8表示ps -aux的第8列(表示进程状态的列),~表示使用正则,{if($8~"R") print}表示如果第8列包含R字符的话,就打印出来。
一个处于R状态的进程让出CPU的话,分为主动让出和被动让出:
被动让出就是该进程运行的时间到达了时间片规定的时间会让出,切换到下一个处于队列中的进程运行。
主动让出就是当某R状态的进程受到阻塞,该进程会从R状态进入S状态,即使没有运行完规定时间片内的时间就让出了CPU,而且进入S状态该进程会从队列中脱离出来。也就是说,S状态的该进程不会再被切换到进行工作,除非阻塞解除,变回为R状态。
什么情况下会发生阻塞?当硬件执行速度不一致时,例如CPU和磁盘,CPU运行的速度是纳秒级别,而磁盘操作是毫秒级别,当进程进行磁盘读写时就会处于阻塞状态。
根据上面知识,Nginx可以通过以下几个点做到高效占用CPU:
1. 让worker进程都处于R状态,这样说明该worker进程在使用CPU工作,闲着就说明有worker进程没有使用CPU。
worker进程由于使用epoll和事件,即使进程受阻也会去处理其他请求,基本上不会处于S状态。除非是一些nginx的第三方模块的运行导致worker进程进入S状态主动让出CPU
如果是Apache,Apache进程受到阻塞时例如进行磁盘操作,这个进程就会进入S状态,等待磁盘操作完成,这个过程中该进程就会闲着,没有使用到CPU。如果是在高并发的情况下,这种闲着的状态是很致命的,因为老的进程处于S状态不能去处理其他请求,Apache会为了处理更多的请求而开启更多的进程,从而加大了进程间切换的时间消耗。
而如果是Nginx,worker进程进行磁盘操作的时候会注册一个事件,worker进程在磁盘读写的时候不会干等着,而是去处理其他请求,等磁盘操作完毕会触发之前的事件把那个worker进程叫回来继续处理回这个请求。所以即使进行磁盘操作受到阻塞,worker进程也不会进入S状态。
这也是Nginx比Apache性能好的原因。
2. 尽可能减少进程间的切换(一个是减少进程总数,一个是增加worker进程的时间片增大worker进程的运行时间)
我们知道进程切换的越频繁,消耗的切换时间越多,因为每一次切换都是要消耗一点点时间的。
此时我们可以增加worker进程的时间片来让worker进程的切换次数减少同时单次运行worker进程的时间增大。可以通过修改进程优先级做到。
Nice静态优先级:-20~19 # 值越小优先级越高,占用的时间片越长
Priority动态优先级:0~139
一般进程的时间片是 5ms~800ms,尽可能让worker进程的时间片达到800ms。
假如原本worker进程时间片为100ms,那么要切换8次该worker进程才能干完的事情,现在时间片改为800ms,切换1次该worker进程就能干完了。节省了切换7次进程的时间损耗。
在nginx中可以通过worker_priority指令指定worker进程的静态优先级:
worker_priority 0; # 默认为0,我们可以将其设为-20 ,上下文为main
另一方面就是减少进程总数,不要在nginx所在的Linux机器上做其他的占用CPU的事情,这样的话处于R状态的非nginx进程少了,一方面CPU花费在非nginx进程运行的时间少了,另一方面上下文切换时间也少了,效率就上来了。
所以一方面增加nginx进程的时间片,一方面减少其他进程数。
可以通过
cat /proc/cpuinfo | grep "processor" | wc -l
查看逻辑CPU个数
cat /proc/cpuinfo| grep "cpu cores"| uniq
查看每个物理CPU的核数
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
查看物理CPU个数
cat /proc/meminfo | grep MemTotal
查看总内存
free -m 查看总内存,使用内存,空闲内存,单位M
PS:请勿混淆CPU个数和核数以及CPU物理核数和CPU逻辑核数,一个物理CPU可以有多核,Linux系统的总核数 = 物理CPU个数*每个物理CPU的核数
一个物理CPU通过一定技术可以分成多个逻辑CPU。worker_processes设定的是逻辑CPU的个数。
逻辑CPU数量 = 物理cpu数量 * cpu cores(每个物理CPU的核数) * siblings/cpu cores(如果支持并支持超线程,此值大于1)
如果不支持超线程,则:
物理CPU个数 * cpu cores(每个物理CPU的核数) = 逻辑CPU的个数
综上总结几个调优参数:
worker_processes number|auto; # 声明开启多少个worker进程,auto表示默认和逻辑CPU个数相同。一般来说,拥有几个逻辑CPU,就设置为几个worker_processes 为宜,但是 worker_processes 超过8个就没有多大意义
worker_cpu_affinity auto; # 默认每一个worker进程绑定一个CPU,这是比较好的设置。
=========================================
网络层面的优化:
可以通过
netstat -anp|grep tcp # 可查看tcp连接情况
对TCP连接的优化
主要是两方面:让Linux系统能建立更多的并发连接;让每次TCP连接的时间更快。
首先介绍TCP三次握手在Linux系统中的一些流程:
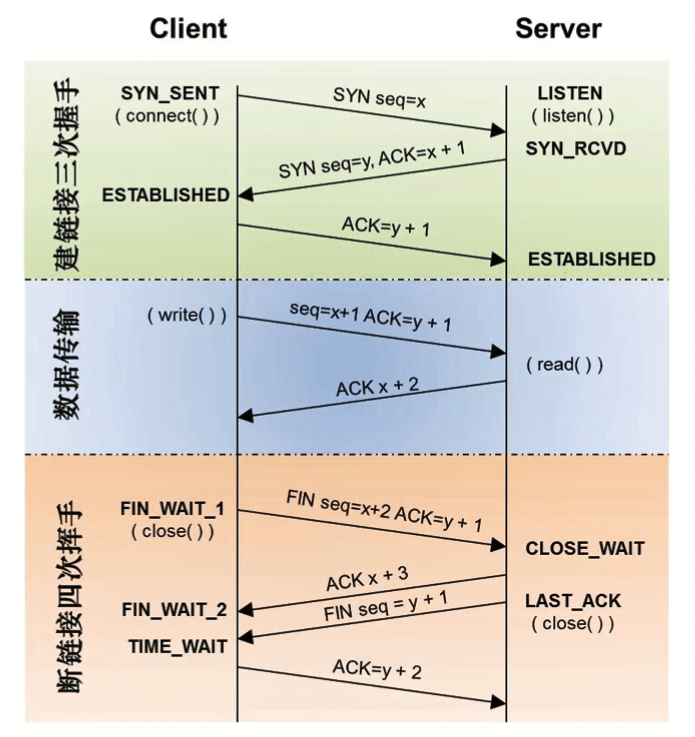
未建立连接时,服务端的端口(例如80)处于Listen状态。
第一次握手:客户端通过connect()方法发送SYN报文给服务端,客户端处于SYN_SENT状态。服务端通过listen()方法接收到该报文,此时第一次握手完成,连接完成了一半,叫做半连接,服务端会将这些半连接放在一个SYN队列中。而此时服务端的该连接状态变为SYN_RCVD
第二次握手:服务端发送一个SYN+ACK的报文给客户端,客户端接收以后进入ESTABLESHED状态。
第三次握手:客户端发送一个ACK报文连带着HTTP请求给服务端,服务端接收到以后会从SYN队列取出对应的一个半连接放到一个ACCEPT队列中,此时半连接转变为成功建立的连接,ACCEPT队列中都是成功建立的连接。此时服务端的该连接从SYN_RCVD变为ESTABLISHED状态。
下一步,Nginx通过accept()函数从Linux系统的ACCEPT队列中取出建立好的连接,并处理HTTP请求。
SYN队列和ACCEPT队列中能容纳的连接的数量是有限制的,而这些也是决定Linux的并发连接数量的因素之一,它限制的是能够建立的tcp连接的并发数量(而CPU和内存则是限制能够处理的tcp连接的并发数量,能连上的连接不一定有足够的性能都能同时处理)。SYN队列长度由tcp_max_syn_backlog参数决定,ACCEPT队列长度由min(net.core.somaxconn,backlog)决定,somaxconn是系统内核参数,直接定义了ACCEPT队列能容纳的已完成连接的上限个数,而backlog实在nginx中在listen指令中限制的,如 listen 80 backlog=2048。
A. 让Linux系统能建立更多的并发连接:
A-1 TCP连接相关的调优参数(Linux内核变量)
fs.file-max
# Linux能够同时打开的文件数量。每一个连接都是文件句柄,所以Linux容纳的文件句柄数的上限也会限制并发连接数。
sysctl -a|grep file-max # 可查看系统内可使用的最大句柄数
# fs.file-max = 183961
# 查看更详细的:
sysctl -a | grep file-nr
# fs.file-nr = 1888 0 183961
# 1888是已使用的句柄数,0是已分配的句柄数,183961是总句柄数
ulimit -n查询的结果表示单个进程允许打开的最大文件句柄数
可用ulimit -n xxx调大该参数值。
系统重启后会丢失,需要同时修改/etc/security/limits.conf中的nofile值。其中,* 这行的配置表示对非root用户生效。
* soft nofile 1024000
* hard nofile 1024000
root soft nofile 1024000
root hard nofile 1024000
net.ipv4.ip_local_port_range
查看:
sysctl -a | grep ip_local_port_range # 建立连接时端口可用范围
#默认 net.ipv4.ip_local_port_range = 32768 60999 默认是从32768端口到60999端口,所以从这个参数知道最多3万多个并发连接。当然还会有其他内核参数的限制,所以你不一定能有3万这么多的并发连接数的容纳量。
net.ipv4.tcp_max_syn_backlog
查看:
sysctl -a | grep net.ipv4.tcp_max_syn_backlog # TCP 3次握手时,第一次握手时客户端发送SYN报文给服务端,由于此时只握手了一次,所以也叫半连接,这些半连接会放入一个SYN队列中,该参数就是限制半连接数量(SYN队列的长度)的参数。系统默认是128,意味着最多只能容纳建立128个并发连接,在高并发的系统中,这个参数肯定是要改大的。
# 默认 net.ipv4.tcp_max_syn_backlog = 128
net.core.somaxconn
sysctl -a | grep somaxconn # 是指服务端accept队列容纳的已完成的连接的上限数量。
# 默认 net.core.somaxconn = 128
net.core.netdev_max_backlog
# 默认 net.core.netdev_max_backlog = 1000,这是在每个网络接口接收数据包的速率比内核处理这些包的速率快时(即接收包比处理包快时,有很多接收到的包不能被及时处理,只好先放着队列中等待前面的包处理好了再处理),会有一个队列保存这些数据包,该参数表示该队列的最大值。
对于一个4G内存的Linux服务器,建议以上内核参数修改为以下值来进行优化:
net.core.netdev_max_backlog = 20480 # 默认 1000
net.core.somaxconn = 20480 # 默认 128
net.ipv4.tcp_max_syn_backlog = 20480 # 默认 128
net.ipv4.ip_local_port_range = 1024 65000 # 默认 32768 60999
以上内核参数可以通过 修改/etc/sysctl.conf来修改,sysctl -p生效。
PS:如需查看网络带宽,可以先执行 ifconfig查看网卡名字。
然后 执行 ethtool 网卡名字 查看带宽
使用 iftop 命令可以查看高并发下带宽的使用情况。如果带宽不够,即使Linux和Nginx的参数调优调的再好也不能支持高并发。
iftop命令需要通过yum或者apt-get下载。
A-2. Nginx中的调优
worker_connections 1024; # 用于设置单个worker进程接收的最大并发连接数,这个连接数包括上游和下游的连接。
listen 80 backlog=2048; # 设置backlog用来限制ACCEPT队列的长度。nginx中默认backlog只有几百,应该调高。
PS:上面的Linux内核参数决定的都是能够建立的并发连接数上限,而worker_connections和worker_processors决定的是Nginx能够接收和处理的并发连接的上限数量,当然Nginx能处理的上限数量也受限于系统的CPU性能和内存大小。
关于TCP中TIME_WAIT状态的连接:
time_wait状态是在tcp四次挥手的过程中,主动关闭TCP连接的一方(即先发起FIN包的一方,如果使用keepalive那么这一方一般是客户端,如果没有使用keepalive,那么主动关闭TCP连接的会是服务端),在发送完最后一个ACK包后进入的状态。
系统需要在TIME_WAIT状态下等待2MSL(maximum segment lifetime )后才能释放连接。
也就是说,如果是服务端nginx的端口出现Time_Wait状态(客户端time_await不要紧不会影响到服务端),此时连接还没彻底断掉,但是该连接已经不会发送或接收请求了,所以过多的time_wait的端口会导致并发连接数量高但是又是些没什么用的连接,占着资源不干事情。而且time_wait占着这个端口,其他连接就不能通过这个端口和服务端建立连接了。
如果请求数量不多,但是查看nginx日志是提示 worker connection out of limits 超出限制,那么可能就是因为服务端有太多time_wait状态的连接。所以我们要想办法减少time_wait状态的连接。
什么情况下服务端会出现大量time_wait连接:
当nginx作为服务端且没有使用keepalive的时,使用的都是短连接,这会快速产生大量time_wait。或者nginx中的keepalive_requests指定的每个连接发送的请求上限数较小时。这两种情况都会导致服务端成为作为主动关闭连接的一方,从而使服务端Linux出现time_wait
当使用php-fpm的时候,nginx和php-fpm服务如果都在一台主机上,客户端和服务端都在一台主机上,所以无论是使用短连接(php-fpm主动断开连接)还是使用keepalive长连接(nginx主动断开连接),这台主机都一定会出现time_wait的socket。此时一定要使用keepalive,因为这样的话,连接会保持一段时间不断开,就不会这么快产生time_wait的socket,time_wait的socket就不会这么多。
但是高并发连接下,keepalive的超时时间keepalive_timeout参数不能设置的太长,否则会有很多连接在发送完请求后处于空闲状态(不再发送请求了)但是不断开,要等到超时时间内没有新请求发送过来的情况下才会断开。如果达到并发连接上限,空闲连接不发送请求,其他连接又连不过来,会很浪费资源,性能很低。
一句话,就是要严控出现在服务器中的time_wait状态的socket套接字。
解决方案:
1.无论nginx是作为客户端请求上游服务,还是作为服务端服务于下游服务,对上下游服务都要开启keepalive。
对于上游服务通过:
proxy_http_version 1.1;
proxy_set_header Connection "";
开启上游服务
并通过在 upstream {...} 中设置 keepalive指令,保持一定数量的空闲keepalive连接
作为服务端,使用
keepalive_requests 1000; #默认100
将每个连接传送请求的上限数量调大,避免一个连接发送的http请求较多时(超过keepalive_request限制的数量),服务端nginx会主动关闭连接来迫使客户端建立新连接来发送剩下的http请求,导致服务端出现time_wait
2.如果nginx作为客户端请求上游服务,可以开启
net.ipv4.tcp_tw_reuse = 1
表示系统作为客户端时新连接可以复用仍处于time_wait状态的端口
B. 让每次TCP连接的时间更快:
使用TCP Fast Open可以加快每次TCP连接。它的原理是这样的:
正常 TCP 3次握手
第一次客户端发一个SYN信号给服务端。
第二次服务端回一个SYN+ACK信号给客户端。
第三次客户端会再发一个ACK信号,顺便把HTTP请求也带过去。
然后连接建立成功,服务端将请求的响应Data返回客户端。
使用 TCP Fast Open 的过程:
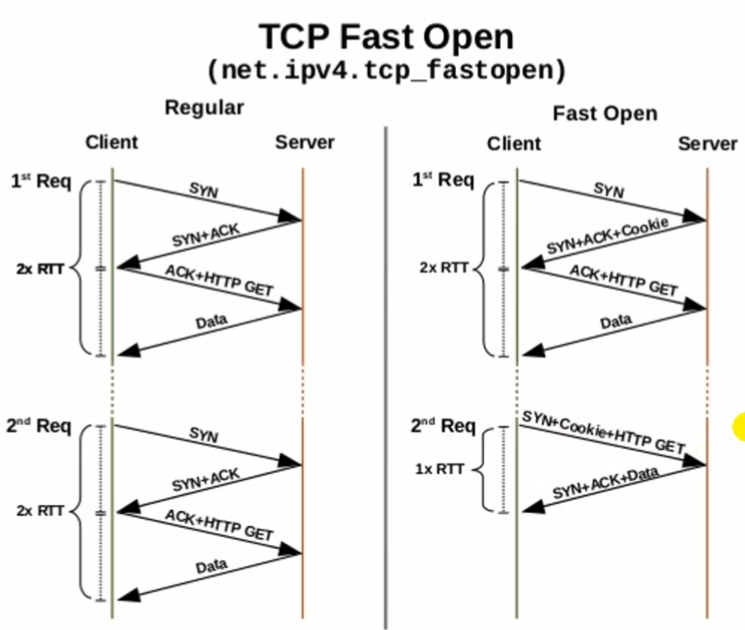
建立第一次连接的3次握手时会,第二次握手手服务端会发送SYN+ACK信号顺便发一个Cookie给客户端,这个Cookie值是通过一系列算法算出来的。
第二次建立TCP连接的时候,客户端第一次握手发送SYN信号,同时会把这个Cookie和HTTP请求发过去,服务端验证Cookie无误后返回SYN+ACK+响应信息。整个过程只发生了2次握手,请求就发出去了,响应Data也返回回来了。
可以通过 net.ipv4.tcp_fastopen 打开TCP Fast Open(TFO)功能。这是Linux系统内核变量。
0 关闭
1 作为客户端时可以使用TFO
2 作为服务端时可以使用TFO
3 无论作为客户端还是服务端都是用TFO
sysctl -a | grep tcp_fastopen # 查看是否开启TFO
如何修改:
vi /etc/sysctl.conf
修改完之后执行
sysctl -p
使其生效
在并发的时候,可以通过
netstat -nat | grep 端口号 | wc -l
查看客户端和某端口建立的tcp并发连接数。
netstat -nat | wc -l
查看总的并发连接数
-a (all) 显示所有选项,默认不显示LISTEN相关。
-t (tcp) 仅显示tcp相关选项。
-u (udp) 仅显示udp相关选项。
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服务状态。
-c 每隔一个固定时间,执行该netstat命令。
-------------------------------------------
上面介绍了 网络层面中TCP层的优化,下面介绍应用层的优化:
ssl_session_cache shared:name:size # 用于TLS/SSL优化握手性能,定义共享内存,为所有worker进程提供Session缓存服务。1MB可用于4000个session
ssl_session_tickets on|off # 默认on,是否开启会话票证,也是真的ssl的。
keepalive_requests 100; # 使用keepalive,允许你一个TCP连接最多传100个请求。可以使用在上游和下游服务中。
使用 keepalive_requests优点为:减少握手次数、减少并发连接数、降低TCP拥塞
gzip on # 对HTTP包体(对于静态文件而言也就是静态文件内容)进行压缩,提升网络传输效率;默认是off的
gzip_types text/html; # 限制对什么类型的文件压缩。
gzip_min_length 20; # 对小于20字节的包体不进行压缩
gzip_comp_level 1; # 压缩率,1~9,越高越消耗性能
gzip_proxied off; # 是否对上游的响应压缩。默认off,因为上游服务器一般会自己压缩。
======================================
磁盘层面的优化
磁盘分为机械硬盘和固态硬盘,后者的速度比前者快很多,但更贵。
可以通过以下命令查看
lsblk -d -o name,rota
对于其返回值,看rota值来判断,如果rota为1,则意味旋转,则为机械盘,若rota为0则意味着发该盘为固态
减少磁盘IO可以从以下方面下手:
A. 优化读取
Sendfile零拷贝
使用内存盘或者SSD盘(固态硬盘)
B. 减少写入
AIO(异步IO)
增大error_log级别(低级别的错误就不会写入到error_log中,可以减少写入次数)
关闭或压缩access_log
对于上游服务的缓存,启用proxy buffering,将上游服务的响应缓存起来写入内存中。默认是开启的。
syslog替代本地IO
C. 线程池thread Pool
关于直接IO和异步IO的概念:
正常读文件,会先从磁盘读取,并存到内核存储的缓冲区(磁盘高速缓存),然后再传到用户进程的缓冲区中(例如存到一个变量中),写入也是一样的过程。当然这个读取的时候,进程由于阻塞会处于休眠的状态,因为读取或者写入需要时间。
直接IO则是读文件会先从磁盘读取直接传到用户进程的缓冲区中,绕过了磁盘高速缓存,精简了一次拷贝过程。
直接IO适用于大文件,因为大文件放到磁盘高速缓存放不下
对于大文件,可以使用直接IO
异步IO则是用户进程受到阻塞的时候,不进入休眠状态(S状态),使得这个进程就可以在等待读写磁盘的时候进行其他工作。
directio size|off; # off是不使用直接IO;size指定文件大小,表示如果某文件超过指定大小,对给文件的操作使用直接IO
aio on|off # 默认off,使用异步IO
使用sendfile零拷贝技术:
如果客户端请求一个文件,正常的流程就是应用程序读取磁盘,磁盘内容存到内核缓冲区,再存到应用程序进程的缓冲区,再发送到Linux内核的socket缓冲区,然后通过滑动窗口发送给客户端。
如果使用了sendfile零拷贝技术,则应用程序调用sendfile方法,告诉磁盘要读取哪些内容,然后存到磁盘高速缓存,然后直接就传到了socket缓冲区然后发给客户端。中间减少了内存拷贝的次数和进程间切换次数,所以又叫零拷贝。
指令:
sendfile on;
sendfile可以和aio,directio指令一起用。
但是当directio生效时sendfile就会失效。
例如:
location / {
sendfile on;
aio on;
directio 8m;
}
如果请求的文件大于8M,就会启用aio和directio;小于8M会使用sendfile零拷贝。
在使用sendfile的时候,如果还使用了gzip,那么使用sendfile失效,就会造成gzip失效,因为gzip压缩包体必须要将磁盘文件内容拷贝到应用程序(nginx)才能对这个内容进行压缩,而sendfile就是跳过了这一步拷贝过程,文件内容不会拷贝到nginx中。
这种情况可以先用tar命令将文件内容压缩为.gz的文件,然后在nginx使用gzip_static模块,他可以检测对应目录的和URL中同名.gz文件,返回该文件的内容。这样同时实现了零拷贝和压缩功能。
gzip_static 要通过 --with-http_gzip_static_module 启用才可以
gzip_static on|off; #默认off
===============================================
使用stub_status模块监控Nginx
要通过 --with-http_stub_status_module 启用
它的功能是通过HTTP接口实时监控nginx的连接状态。统计数据存在共享内存中,所以可以统计所有worker进程的数据,reload不会导致统计数据清空,但是热部署会导致数据清空。
指令:
stub_status; # 上下文:server,location
例如我专门开一个端口给这个服务:
server {
listen 8090;
location / {
stub_status;
}
}
这样访问 http://IP:8090就可以看到统计内容。
内容如下:
Active connections: 4
server accepts handled requests
6 6 48
Reading: 0 Writing: 1 Waiting: 3
Active connection 是客户端和nginx的TCP连接数(并发连接数),等于Reading、Writing和Waiting之和
accepts 是自nginx启动开始,和客户端建立过的连接总数。
handled 是自nginx启动开始,和客户端处理过的连接总数。如果Linux接入的连接总数没有超过worker_connections,这个值和accepts是一样的。如果handled比accepts小,说明系统建立的并发连接数超过了Nginx的连接池能容纳的总并发连接数(即接入Linux系统的连接数超过了nginx能并发处理的连接数),也就是worker_connections调小了,要调大点。
requests 是自nginx启动开始,和客户端处理过的请求总数。由于使用keepalive,一个连接可以发送多个请求,所以requests指标应该比accepts和handled指标大很多,如果比accepts和handled指标大的不多很可能有大量time_wait状态的连接。
Reading 是正在读取HTTP请求头的连接总数
Writing 是正在向客户端发送请求响应的连接总数
Waiting 是当前空闲的HTTP Keepalive连接总数,服务端是要保持一定数量的空闲keepalive连接的。