更多优质内容
请关注公众号
请关注公众号

本文续上一篇文章,对红楼梦文本进行全文分词和每一章节分词,对分词进行统计以及根据分词频率绘制全文的词云图和每一章节的词云图
废话不多说,我们直接上代码
这里说明一下,
hlm_chapter_info.csv 是上一篇文章中处理好的每一章的信息,包括章标题,章的段落数,字数,开始的段数,结束的段数
hlm_cont.csv 是将文章的每一行作为DataFrame的行存储为的csv,csv的一行就是红楼梦文本的一行(除去"第x卷"这样的行)
stopwords.txt 停用词文本,用于去除文本中无意义的词如 我,你,它,和,而且...等词
下面脚本的思路是,先获取每一回的开始段落数和结束段落数,然后从而获取每一回的全部内容,再根据jieba库对每一回的内容进行分词,去掉停用词中无用的分词,这样得到最终的每一回的分词存到hlm_hui_with_cutwords.csv文件中。
# 该脚本用于给红楼梦进行分词
import pandas as pd
import jieba
df_hui = pd.read_csv("./hlm_chapter_info.csv")
df_hlm = pd.read_csv("./hlm_cont.csv")
print(df_hui.head())
# print(df_hlm.head())
hui_cont=pd.Series(["content"]*len(df_hui))
#将每回的内容获取到
for i in range(len(df_hui)):
start = df_hui['parag_start'][i]+1
end = df_hui['parag_end'][i]+1
# print(df_hlm['content'][start:end])
hui_cont[i] = "".join(list(df_hlm['content'][start:end]))
# print(hui_cont.head())
# print(len(hui_cont))
#读取停用词
with open("./hlm/stopwords.txt",encoding="utf-8") as f:
stop_words = [i.strip("\r\n") for i in f.readlines()] # 要将每个停用词后面的\r\n给去掉,否则后面是无法去掉内容中的停用词的
cutwords_list = []
#对每段内容进行分词
for cont in hui_cont:
cutwords = pd.Series([i for i in jieba.cut(cont) if len(i)>=2])
#去除停用词
cutwords = cutwords[cutwords.apply(lambda x:x not in stop_words)] #cutwords.apply(lambda x:x not in stop_words)返回一堆[True,False,...],True代表的是非停用词的分词
#上面还可以写成 cutwords[~cutwords.isin(stop_words)] cutwords.isin(stop_words)也是返回一堆True False
#将处理好的分词插入df_hui中
# cutwords_list.append(cutwords.values) # cutwords是Series,而Series是不能直接作为值插入到df_hui的单元格中,而cutwords.values(列表)就可以
cutwords_list.append(",".join(cutwords.values)) #由于之后要将分词写入csv文件,所以,将分词转为字符串形式而不是列表形式,否则在csv中,列表太长会自动转为...,省略了很多分词
df_hui['cutwords'] = pd.Series(cutwords_list) #将每回的分词添加到df_hui回信息的dataframe中,并写入新的一个csv文件
print(df_hui.head())
# df_hui.to_csv("./hlm_hui_with_cutwords.csv",index=False)
接下来获取全书的分词,并统计整本书的分词出现频率,然后绘制词云图:
# =============== 获取全书分词,并对每个分词做统计和排序 =================
import pandas as pd
import numpy as np
from wordcloud import WordCloud
import matplotlib.pyplot as plt
df_hui = pd.read_csv("./hlm_hui_with_cutwords.csv")
cutwords_all = ",".join(df_hui['cutwords'].values)
print(len(cutwords_all))
cutwords_list = cutwords_all.split(",")
df_words = pd.DataFrame({"words":cutwords_list}) #将全书分词转为df,因为df才有groupby方法,可以进行分组统计
print(df_words.head())
word_group = df_words.groupby(by=['words'])['words'].agg({"number":np.size}) # 或者用len也可以,计算的是分词出现的次数
print(word_group) #此时他的index是words列
#将index变成words列,并重新索引
word_group = word_group.reset_index()
word_group['wordlen'] = word_group['words'].apply(len) #每个分词的长度
#根据分词出现次数降序排序
word_group = word_group.sort_values(['number'],ascending=False)
print(word_group)
#将出现次数小于5的词干掉,并将统计好的分词写入csv中
word_group_new = word_group[word_group['number']>=5] #或者 word_group_new = word_group.loc[word_group['number']>=5,:],不能用iloc,iloc里面不接收[False,Frue,...]的形式
print(word_group_new)
# word_group_new.to_csv("./hlm_cutwords_stat.csv",index=False)
#绘制词云图并保存
filename = "hlm_cutwords_wordcloud/.csv"
word_freq_dict = {word_group_new['words'].iloc[i]:word_group_new['number'].iloc[i] for i in range(len(word_group_new))} #这里的字典推导式不要写成word_group_new['words'][i]:word_group_new['number'][i],因为word_group_new中的索引不是正常索引而是乱序的索引,所以要用iloc;如果使用的reset_index那么两种写法都对
# print(word_freq_dict)
wc = WordCloud(font_path="simhei.ttf",width=1600,height=1000).fit_words(word_freq_dict)
fig = plt.figure(figsize=(16,16))
plt.imshow(wc)
plt.axis("off")
plt.show()
得到的全书分词统计如下(只展示部分分词):
| words | number | wordlen |
| 宝玉 | 3762 | 2 |
| 贾母 | 1230 | 2 |
| 凤姐 | 1097 | 2 |
| 王夫人 | 1015 | 3 |
| 说道 | 979 | 2 |
| 老太太 | 975 | 3 |
| 姑娘 | 951 | 2 |
| 众人 | 872 | 2 |
| 奶奶 | 847 | 2 |
| 太太 | 825 | 2 |
| 只见 | 791 | 2 |
| 两个 | 771 | 2 |
| 不知 | 709 | 2 |
| 听见 | 692 | 2 |
| 贾琏 | 669 | 2 |
| 告诉 | 605 | 2 |
| 东西 | 603 | 2 |
| 平儿 | 590 | 2 |
| 袭人 | 584 | 2 |
| 回来 | 569 | 2 |
| 宝钗 | 568 | 2 |
得到的词云图如下:
.png)
红楼梦全书词云图
接下来绘制出现频率高的250个和500个词的条形图
# 绘制条形图查看分词出现频率
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文
plt.rcParams['axes.unicode_minus'] = False #正常显示负号
df_stat = pd.read_csv("./hlm_cutwords_stat.csv")
print(df_stat.head())
#绘制出现频率大于500,250的词
df_morethan_500 = df_stat.loc[df_stat['number']>500] #或者df_statloc[df_stat['numbe']>500]
df_morethan_250 = df_stat[df_stat['number']>250]
fig = plt.figure(figsize=(16,16))
plt.subplot(121)
x_label_500 = df_morethan_500['words'] #横坐标的文本
x_pos_500 = np.arange(len(df_morethan_500)) #横坐标的位置
plt.bar(x=x_label_500,height=df_morethan_500['number'],color="skyblue") #x是横坐标的标签值,height是y值,x的值也可以在xticks的labels参数中设置
plt.xticks(rotation=90) #由于横坐标的中文有点长,所以,将横坐标转90度显示
plt.xlabel("出现次数超过500次的关键词")
plt.ylabel("频率")
plt.title("红楼梦关键词频率")
plt.subplot(122)
x_label_250 = df_morethan_250['words'] #横坐标的文本
x_pos_250 = np.arange(len(df_morethan_250)) #横坐标的位置
plt.bar(x=x_label_250,height=df_morethan_250['number'],color="yellow")
plt.xticks(rotation=90)
plt.tick_params(labelsize=6) #设置横坐标字体小一些
plt.xlabel("出现次数超过250次的关键词")
plt.ylabel("频率")
plt.title("红楼梦关键词频率")
plt.show()
得到的条形图如下(点击图片可以查看大图):
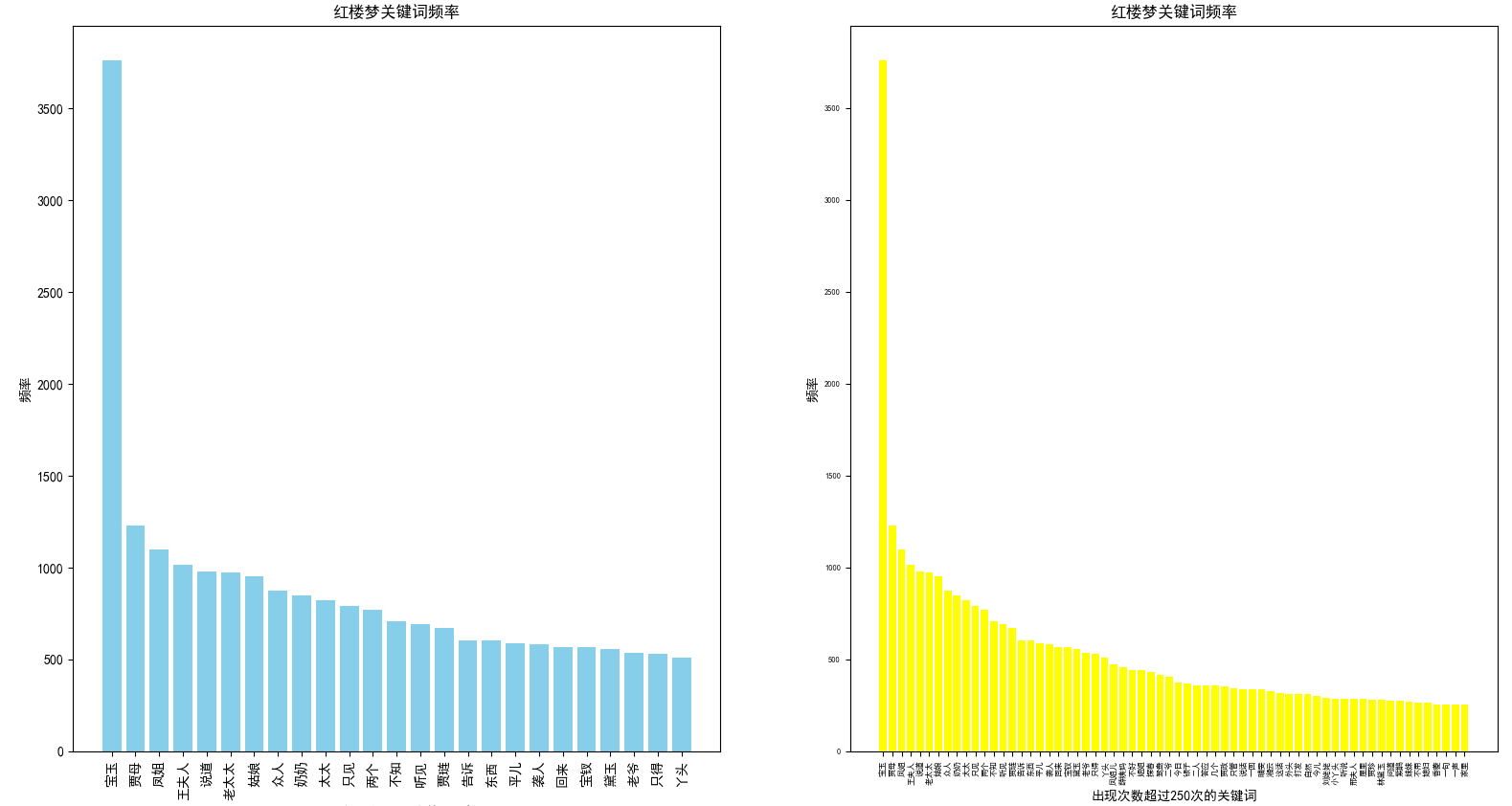
红楼梦分词频率条形图
最后对每一回的分词绘制分词频率条形图以及词云图,并将这些图存到自定义目录 hlm_hui_pic 中,一共240张图
# 对每一回的分词做条形图统计和词云图
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文
plt.rcParams['axes.unicode_minus'] = False #正常显示负号
# 制作每一回数据的条形图,传入的数据是Series,即df_hlm的一行数据;第二参是图片存储位置,不含文件名
def makeBar(data,fp="."):
fp = fp.strip(r"/")
fig = plt.figure(figsize=(10,8)) #这句很重要,重新生成一个画布,这样上一个条形图的plt就不会叠加到这一个条形图的plt
#先获取每个词的词频
cutwords = pd.DataFrame({"cutwords":data['cutwords'].split(",")}) #转为df,因为df才可以使用groupby
cutwords_group = cutwords.groupby(by=['cutwords'])['cutwords'].size() # 返回一个series
cutwords_group = cutwords_group.sort_values(ascending=False) #对Series的值倒序排序
cutwords_group_final = cutwords_group[:25]
#定义条形图x和y
x = cutwords_group_final.index
y = cutwords_group_final.values
b = plt.bar(x=x,height=y)
for i in b: #设定条形图的y值数据标签
h=i.get_height()
plt.text(i.get_x()+i.get_width()/2,h,"%s" % h,fontsize=12,ha='center', va='bottom') #这三参分别是,标签的位置(横坐标位置,纵坐标位置)和值
plt.xlabel("出现最多的25个分词")
plt.ylabel("出现频数")
plt.xticks(rotation=90)
plt.tick_params(labelsize=12) #横坐标数据的字体大小
plt.title(data['chapterNum']+" "+data['fullName'])
plt.savefig(fp+"/分词频率_"+data['chapterNum']+".png")
plt.close() #画完后关闭plt再画下一个
def makeWordCloud(data,fp="."):
fig = plt.figure(figsize=(10,10))
cutwords = data['cutwords'].replace(","," ")
wc = WordCloud(font_path="simhei.ttf").generate(cutwords)
plt.imshow(wc)
plt.axis("off")
plt.title(data['chapterNum'] + " " + data['fullName'])
plt.savefig(fp+"/词云图_"+data['chapterNum']+".png")
plt.close()
df_hlm = pd.read_csv("./hlm_hui_with_cutwords.csv")
for i in range(len(df_hlm)):
data = df_hlm.iloc[i, :]
makeBar(data,"./hlm_hui_pic") #获取df_hlm的第i列的所有行,是一个Series,传入makeBar
makeWordCloud(data,"./hlm_hui_pic")