更多优质内容
请关注公众号
请关注公众号

线程池
线程池是存放多个线程的容器
CPU从线程池中调度线程并执行,执行后不会销毁线程,而是将线程放回线程池以便重复利用。
在正式的开发中,当我们想用多线程完成某个任务的时候,我们不会在需要完成任务的时候才创建线程,任务结束就释放线程资源。而是会创建一个线程池,在线程池中创建一定数量的线程,并且一开始就启动线程。线程池中的线程即使没有任务也是处于启动的状态。
平时线程池中的线程都处于休眠状态。当任务队列中有任务则从任务队列中获取任务,此时线程池中的线程会被唤醒,用于并发完成任务。当任务完成后,线程不会被销毁,而是返回线程池中继续休眠。
为什么要使用线程池
1.线程是稀缺资源(线程的创建时会消耗资源和时间的)
所以不应该频繁的创建和销毁
2.架构解耦
将线程的创建和业务的处理分开,更加优雅。
意思是,我们不应该等到要处理业务的时候才去创建线程。而是应该一开始就把多个线程创建好,等到要处理业务的时候直接从线程池里面拿线程就好。
3.线程池本来就是使用线程的最佳实践
现在我们要搭建一个比较完整的多线程任务处理体系。其中我们需要以下几样东西:
1.存放多个任务的队列(任务队列ThreadSafeQueue)
2.要执行的任务(任务对象Task)
3.处理任务的线程(线程对象ProcessThread)
4.存放线程的线程池(ThreadPool)
A. 线程安全的任务队列 ThreadSafeQueue
# coding=utf-8
from threading import Lock,Condition,Event
class ThreadSafeQueue:
def __init__(self,max_size=0,timeout=None):
self.queue=[]
self.lock=Lock()
self.cond = Condition()
self.max_size = max_size
self.timeout=timeout
def size(self):
self.lock.acquire()
size = len(self.queue)
self.lock.release()
return size
def put(self,item):
self.cond.acquire() # 这里使用了条件变量的锁,整个put过程都是一个原子操作,都是上了锁的
while self.max_size>0 and len(self.queue)>=self.max_size:
res = self.cond.wait(timeout=self.timeout) # True or False
if not res:
self.cond.release() # 记得释放锁,否则其他线程会死锁
return False
self.queue.append(item)
self.cond.notify()
self.cond.release()
def pop(self):
self.cond.acquire() # 这里使用了条件变量的锁,整个pop过程都是一个原子操作,都是上了锁的
while len(self.queue)<=0:
res = self.cond.wait(timeout=self.timeout)
if not res:
self.cond.release()
return False
item = self.queue.pop(0)
self.cond.notify()
self.cond.release()
return item
def batch_put(self,items):
if not isinstance(items,list):
items = list(items)
for item in items:
self.put(item)
def get(self,index):
self.lock.acquire()
try:
item = self.queue[index]
except:
item=None
self.lock.release()
return item
if __name__ == "__main__":
from threading import Thread
def producer(queue):
for i in range(10000):
queue.put(i)
def consumer(queue):
while True:
print(queue.pop())
queue = ThreadSafeQueue(max_size=100)
t1 = Thread(target=producer,args=(queue,))
t2 = Thread(target=producer,args=(queue,))
t3 = Thread(target=consumer,args=(queue,))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()我们知道,多线程需要从任务队列中添加和获取任务,此时这个任务队列就变成了多线程的共享资源,多线程会对这个队列竞争使用。为了避免竞争造成的混乱,我们要让这个队列中的元素(也就是任务)是有序的存取的,这样这个队列才是线程安全的。
而任务队列的线程安全主要是通过加锁和条件变量来实现的。其效果就是,一次只有一个线程往队列中放入任务或者写入任务,a线程在取任务的时候,b线程不能从队列取任务;a线程往队列放任务的时候,b线程也不能从队列中取任务。也只有这样才能保证队列是线程安全的。
这么一来,任务的存取(put()和pop())就是串行的,单线程的,而不是并发的,没有提高效率。但是没关系,任务的执行是并发执行的,会提高效率。
B.任务对象Task
# coding=utf-8
from uuid import uuid4
from threading import Condition
# 无返回值的任务
class Task:
def __init__(self,func,*args,**kwargs):
self.id = uuid4() # 任务唯一标示
self.callable = func # 任务函数
self.args = args
self.kwargs = kwargs
# 执行任务
def call(self):
res = self.callable(*self.args,**self.kwargs)
return res
def __str__(self):
print("任务ID: %s" % str(self.id))
def __repr__(self):
print("任务ID: %s" % str(self.id))
# 有返回值的任务
class AsyncTask(Task):
def __init__(self,func,*args,**kwargs):
super(AsyncTask, self).__init__(func,*args,**kwargs)
self.result = None
self.cond = Condition()
# 当任务完成时设置任务函数的返回值
def set_result(self,result):
self.cond.acquire()
self.result=result
self.cond.notify()
self.cond.release()
# 获取任务函数的返回值,该函数可以在任务完成前调用。在任务完成前会阻塞主线程,直到set_result()被调用,才能获取任务的返回值。
def get_result(self):
if self.result is None:
self.cond.acquire()
self.cond.wait()
self.cond.release()
return self.result任务对象的关键是将任务函数的引用作为参数传入到Task对象中,存储在Task对象的一个变量里面。当需要执行任务的时候,直接调用这个变量所存储的函数即可。
任务对象,一个任务只能创建一个任务对象。或者说一个任务对象只代表一个任务
任务结果的获取是发生在主线程(get_result),任务结果的设置是发生在线程池中的线程(set_result),要等线程执行完这个任务才会设置结果
如果主线程去获取任务结果时,线程池中的线程还没有执行完,此时主线程就要等待结果设置好了get_result才能获取到结果并返回
可以给任务添加一个条件变量来实现上述过程,任务没完成则条件变量处于等待状态(等待阻塞的是主线程),任务完成后则发出通知,唤醒主线程
通过 set_result 和 get_result 方法实现了主线程和其他线程间异步执行下还能获取到任务执行完毕的返回值。这是通过条件变量实现的。
Task对象的实例会作为任务放入到 任务队列 ThreadSafeQueue 中
C.处理任务的线程(线程对象ProcessThread)
# coding=utf-8
from threading import Thread,Lock,Event
from .Task import Task,AsyncTask
class ProcessThread(Thread):
def __init__(self,queue,*args,**kwargs):
super(ProcessThread, self).__init__(*args,**kwargs)
self.queue = queue
self.dismiss_flag=Event()
self.args = args
self.kwargs = kwargs
def run(self):
while True:
if self.dismiss_flag.is_set():
break
task = self.queue.pop()
if not isinstance(task,Task):
continue
result = task.call()
# 如果这个任务是一个有返回值的任务,则执行完任务时,设置结果
if isinstance(task, AsyncTask):
task.set_result(result)
def stop(self):
print("线程停止获取任务")
self.dismiss_flag.set() # 停止从任务队列中取任务
self.queue.stopBlocking() # 唤醒任务队列中pop的阻塞线程对象会放入线程池中统一管理
D.存放线程的线程池(ThreadPool)
# coding=utf-8
from threading import Thread
from time import sleep
from .ProcessThread import ProcessThread
from psutil import cpu_count
from .Task import Task
from .ThreadSafeQueue import ThreadSafeQueue
class ThreadPool:
def __init__(self,pool_size=0):
self.pool = [] # 线程池
self.task_queue = ThreadSafeQueue() # 大小没有限制的任务队列
if pool_size==0:
self.size = cpu_count()*2 # 定义线程池中线程的个数,默认CPU核数*2个线程
else:
self.size = pool_size
def init_thread(self):
for i in range(self.size):
thread = ProcessThread(self.task_queue)
self.pool.append(thread)
# 运行线程
def start(self):
for thread in self.pool:
thread.start()
def stop(self):
for thread in self.pool:
thread.stop()
while len(self.pool):
thread = self.pool.pop()
thread.join() # 这一句是考虑到线程正在执行任务,等它执行完了再终止主线程
def size(self):
return len(self.pool)
# 添加任务
def put_task(self,task):
if not isinstance(task,Task):
raise TaskTypeException
self.task_queue.put(task)
# 批量添加任务
def batch_put_task(self,tasks):
self.task_queue.batch_put(tasks)
class TaskTypeException(Exception):
pass
if __name__=="__main__":
# 使用线程池做简单任务:
def simpleTask():
#time.sleep(0.5)
print("print 1")
#time.sleep(0.5)
print("print 2")
# 实例化一个线程池
pool = ThreadPool()
# 先将线程池中所有线程启动,一开始没有任务,所以所有线程启动之后立即进入等待状态
pool.start()
# 添加10万个任务给线程池,里面的线程会自动获取任务执行
print("开始执行任务")
for i in range(100000):
task = Task(simpleTask)
pool.put(task)
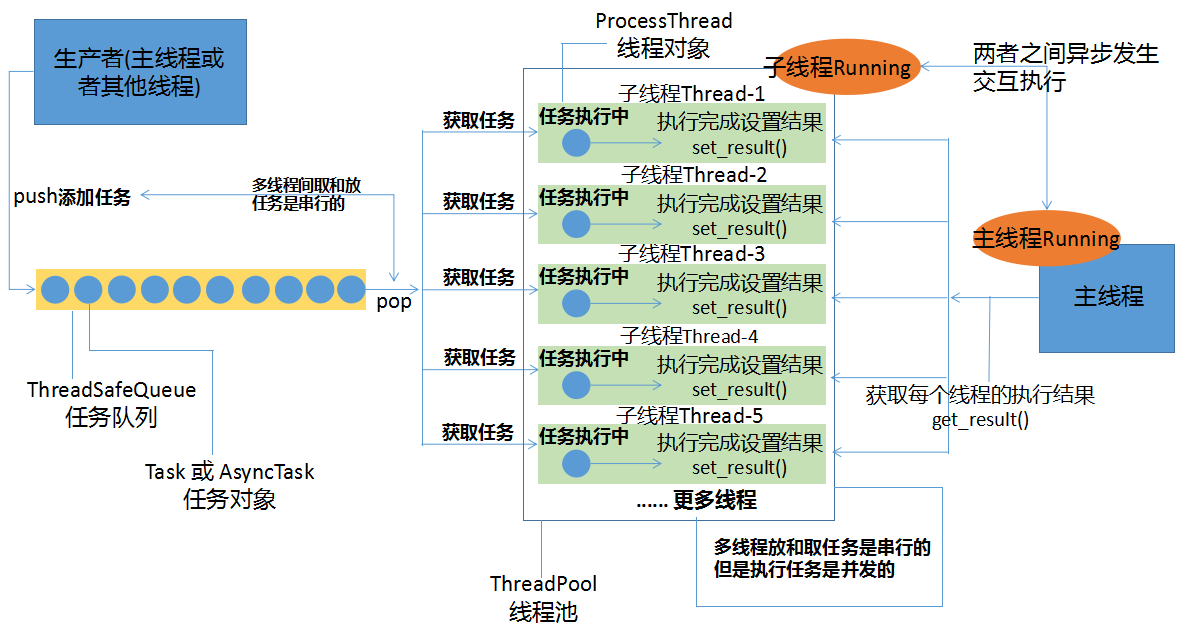
这个线程池的功能:1 存放多个ProcessThread线程对象; 2.负责线程的启动停止; 3.接收Task任务对象并存放到任务队列中
整体的架构如下图所示:
下面,使用这个线程池写一个爬取文章列表页和详情页以及图片的程序
Crawler.py
这个程序有点多,所以写贴出伪代码,让大家先了解里面的逻辑
# coding=utf-8
import requests, pymysql
from bs4 import BeautifulSoup
from ThreadTool.ThreadPool import ThreadPool,AutoStopThreadPool
from ThreadTool.Task import Task
from ThreadTool.ThreadSafeQueue import ThreadSafeQueue
# 由于任务函数会继续生产任务,所以这里写一个新的线程池将任务队列解耦,从线程池中分离出来
class MyThreadPool(ThreadPool):
def __init__(self,task_queue,pool_size=0):
super(MyThreadPool, self).__init__(pool_size)
self.task_queue=task_queue
start_urls={ ...起始url }
# mysql参数
db_conf = { ...mysql连接参数 }
def dl_img(pic_url,dir_path="./uploads/fx112/full"):
...图片下载
# 构建任务函数
class Crawler:
def __init__(self,base_url,start_urls,task_queue):
1. ...保存一个任务队列 self.task_queue 以及初始爬取的列表页url
2. ...创建两个集合用于存放爬取过的详情页和列表页 crawled_list_links 和 crawled_detail_links
3. ...连接数据库获取数据库中记录的上一次爬取过的详情页url并放入刚刚定义的集合中
4. ...创建mysql连接池,这个连接池是一个线程安全的队列 self.create_db_pool()
# 生成连接池
def create_db_pool(self):
1. ...生成10个mysql连接 ThreadSafeQueue(10)
2. ...将10个连接放入队列以备使用 self.db_pool.put(conn)
# 开始任务
def start(self):
...调用 self.crawl_list(self.start_urls) 开始爬取初始列表页url
# 爬取列表页
def crawl_list(self,url,type):
1. ...爬取本页的下一页的列表页链接list_link 和本页的所有详情页链接art_links
2. ...对每一个列表页和详情页创建一个任务 Task ,并将任务放入任务队列 self.task_queue中;列表页的任务函数是self.crawl_list;详情页的任务函数是self.crawl_detail;将这两个任务函数作为参数传入 Task() 对象中
3. ...Crawler类外的线程池中的线程会自动获取任务队列中的任务并执行
def crawl_detail(self,url,type):
1. ...爬取详情页的数据
2. ...获取到详情页的图片链接,并下载图片 self.crawl_imgs()
3. ...数据入库 self.insert_db() 这里复用了连接池中的mysql连接
# 数据入库
def insert_db(self,field):
1. ...从连接池取出连接
2. ...数据入库
3. ...将连接放回连接池
# 批量下载一个详情页中的所有图片
def crawl_imgs(self,imgs):
...调用 dl_img() 下载图片
# 创建任务队列
task_queue = ThreadSafeQueue()
# 创建线程池
pool = MyThreadPool(task_queue)
# 创建线程并开始运行线程,此时线程会开始不断从任务队列中获取任务
pool.init_thread()
pool.start()
# 开始往任务队列中放任务
crawler = Crawler(base_url="https://www.fx112.com",start_urls=start_urls,task_queue=task_queue)
crawler.start()
这里面涉及到两个池:mysql连接池和线程池
线程池是在Crawler这个类之外创建的。任务队列也是在Crawler这个类之外创建的,并且这个队列会传入Crawler类中,也会传入线程池中。Crawler实例会往队列添加任务,线程池的会从队列取出任务执行。
线程池中线程先启动等待获取任务队列中的任务,然后Crawler才爬取内容并创建任务,并将任务放入队列
线程池中的线程就是消费者,而主线程中的Crawler实例就是生产者。
下面贴出详细代码
# coding=utf-8
import os,sys,re,time
import hashlib
from fake_useragent import UserAgent
# sys.path.append(os.path.abspath(os.path.dirname("./ThreadPool")))
# os.chdir("./ThreadPool")
import requests, pymysql
from bs4 import BeautifulSoup
from ThreadTool.ThreadPool import ThreadPool,AutoStopThreadPool
from ThreadTool.Task import Task
from ThreadTool.ThreadSafeQueue import ThreadSafeQueue
# 由于任务函数会继续生产任务,所以这里写一个新的线程池将任务队列解耦,从线程池中分离出来
class MyThreadPool(ThreadPool):
def __init__(self,task_queue,pool_size=0):
super(MyThreadPool, self).__init__(pool_size)
self.task_queue=task_queue
# 咨询 1; 曝光 2;投诉 3;
start_urls={
"https://www.fx112.com/brokers/rights/consulting/":1,
"https://www.fx112.com/brokers/rights/exposure/":3,
"https://www.fx112.com/brokers/rights/complaints/":2
}
# mysql参数
db_conf = {
"host":"127.0.0.1",
"user":"root",
"password":"573234044",
"charset":"utf8",
"database":"fx285",
"cursorclass":pymysql.cursors.DictCursor
}
def timetostr(strTime):
# 先转换为时间数组
timeArray = time.strptime(strTime, "%Y-%m-%d %H:%M:%S")
# 转换为时间戳
timeStamp = int(time.mktime(timeArray))
return timeStamp
def dl_img(pic_url,dir_path="./uploads/fx112/full"):
if not pic_url:
return
try:
ua = UserAgent()
headers = {"User-Agent":ua.random}
r = requests.get(pic_url,headers=headers)
if r.status_code==200:
dir_path = dir_path.replace("\\","/").strip("/")
real_dir_path = os.path.abspath(dir_path).replace("\\","/")
m=hashlib.md5()
m.update(pic_url.encode())
fn = m.hexdigest()
fn = fn[8:24]+".jpg"
real_img_path = real_dir_path+"/"+fn
with open(real_img_path,"wb") as f:
f.write(r.content)
return dir_path.strip(r".")+"/"+fn
else:
return False
except:
return False
# 构建任务函数
class Crawler:
def __init__(self,base_url,start_urls,task_queue):
self.base_url = base_url
self.start_urls = start_urls
self.task_queue = task_queue
self.crawled_list_links = set()
self.crawled_detail_links = set()
conn = pymysql.connect(**db_conf)
cursor = conn.cursor()
sql = "select url from brokers_art"
cursor.execute(sql)
res = cursor.fetchall()
for url in res:
self.crawled_detail_links.add(url['url'])
print(self.crawled_detail_links)
self.create_db_pool()
# 生成连接池
def create_db_pool(self):
self.db_pool = ThreadSafeQueue(10) # 生成10个连接
for i in range(10):
conn = pymysql.connect(**db_conf)
self.db_pool.put(conn)
print("生成mysql连接")
def start(self):
for url,type in start_urls.items():
self.crawl_list(url,type)
def url_concat(self,uri):
return self.base_url.strip(r"/")+"/"+uri
def crawl_detail(self,url,type):
if url in self.crawled_detail_links:
print("%s 已经采集过了!" % url)
return
r = requests.get(url)
soup = BeautifulSoup(r.text,"html.parser")
field = {}
try:
field['id'] = re.findall("(\d+)\.html", url)[0]
field['title'] = soup.find("div",class_="title").find("h2").get_text()
field['type']=type
field['mark']=str(soup.find("div",class_="mark"))
field['content']=str(soup.find("div",class_="content"))
field['content'] = re.sub("<div class=\"Imgs\">.*?</div>","",field['content'],flags=re.DOTALL)
field['content'] = re.sub("<p style=\"font-size: 14px; margin-top:40px; line-height: 30px; text-indent: 2em; color: #AEAEAE;\">.*?</p>","",field['content'],flags=re.DOTALL)
field['url'] = url
field['reply']= str(soup.find("div",class_="comment-text"))
img_tags = soup.findAll("div",class_="Imgs")
field['img']=[]
for img in img_tags:
field['img'].append(self.url_concat(img.find("img")['src']))
field['img']=",".join(field['img'])
field['create_time']=timetostr(soup.find("p",class_="time").findAll("em")[-1].get_text())
field['reply_time']=timetostr(soup.find("p",class_="comment-time").get_text())
field['is_reply']=1
except BaseException as e:
print("Error:%s" % url)
print(e)
return
# 爬取图片任务
print("Img:%s" % url)
field['img']=self.crawl_imgs(field['img'])
# 添加数据入库任务
self.insert_db(field)
print(field)
def insert_db(self,field):
# 从连接池取出连接
conn = self.db_pool.pop()
cursor = conn.cursor()
sql = "insert ignore into brokers_art (id,type,title,mark,content,img,url,reply,create_time,reply_time,is_reply) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
try:
cursor.execute(sql,(field["id"],field["type"],field["title"],field["mark"],field["content"],field["img"],field["url"],field["reply"],field["create_time"],field["reply_time"],field["is_reply"]))
conn.commit()
self.crawled_detail_links.add(field['url'])
except BaseException as e :
print(field['url'])
print(e)
cursor.close()
self.db_pool.put(conn) # 回收连接
def crawl_imgs(self,imgs):
if not imgs:
return
imgs = imgs.split(",")
img_list=[]
# print(imgs)
for img in imgs:
im = dl_img(img)
if im:
img_list.append(im)
imgs=",".join(img_list)
return imgs
def crawl_list(self,url,type): # 爬取列表页
list_base_url = re.sub(r"\d+.html","",url)
r = requests.get(url)
soup = BeautifulSoup(r.text,"html.parser")
# 爬取详情页链接
ul=soup.find("div",class_="content").find("ul")
li_tags = ul.findAll("li")
# 爬取下一页列表页链接
try:
list_link = list_base_url+soup.find("li",class_="thisclass").find_next().find("a")["href"]
if list_link in self.crawled_list_links:
list_link=None
except: # 没有下一页的情况
list_link=None
print(list_link)
for li_tag in li_tags:
# links.append()
art_link = self.url_concat(li_tag.find("a")["href"])
# 添加爬取详情任务
task_detail = Task(self.crawl_detail,type=type,url=art_link)
self.task_queue.put(task_detail)
print("添加详情页任务 %s " % art_link)
# 添加爬取列表页任务
if list_link:
task_list = Task(self.crawl_list, list_link, type)
self.task_queue.put(task_list)
self.crawled_list_links.add(list_link)
print("添加列表页任务 %s " % list_link)
# 创建任务队列
task_queue = ThreadSafeQueue()
# 创建连接池
pool = MyThreadPool(task_queue)
# 创建线程并开始运行线程
pool.init_thread()
pool.start()
# # 开始往任务队列中放任务
crawler = Crawler(base_url="https://www.fx112.com",start_urls=start_urls,task_queue=task_queue)
crawler.start()
# crawler.crawl_detail("https://www.fx112.com/brokers/rights/complaints/5144.html",3)