更多优质内容
请关注公众号
请关注公众号

索引是什么,下面是mysql的官方定义:
“索引是帮助mysql高效获取数据的排好序的数据结构”。 抓重点,索引的本质是一种数据结构,而且是排好序的。索引作用有2个,一个是排序,一个是快速查找,而快速查找的基础就是排好了序的索引。
那么索引可以有哪些数据结构:
二叉树、红黑树、hash表和B-Tree
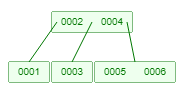
二叉树索引
下面我们以二叉树这种数据结构的索引为例,说明索引是如何工作的:
假如现在有一张表,表里面有两个字段 Col1 和 Col2:
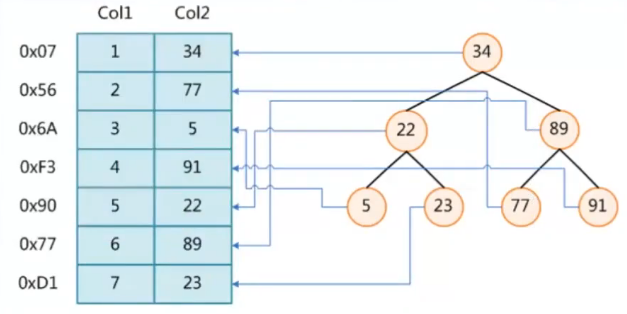
现在我查询一个sql: select * from t where col2=89;
在不使用索引情况下,mysql会从头遍历表t,一条条的往下查询,并比对 col2 字段是否为89。
如果使用了二叉树索引,在对col2字段建立索引的时候,mysql会将col2字段的所有内容以二叉树的数据结构写入到一个索引文件中。
我们知道二叉树其实是由链表变形而来的,是由多个节点和链接指向构成的。在二叉树索引中,每一个节点都存储着key和value,key是从来col2的值(89),value是col2这个字段所在行的磁盘地址(0x07,0x56之类的)。
二叉树的特点就是一个节点的右子节点的key比左子节点的key大,通过二叉树进行查找的时间复杂度是 O(log2n),而不用二叉树通过遍历的方式查找的复杂度是 O(n)。所以在二叉树中可以快速找到 key 为 89 的节点,获取到这个节点的value(存储col2 = 89的行所在的磁盘空间地址),然后再从这个地址中获取col2=89这一行的所有字段的数据。
树上的每一个索引节点都被分配一个磁盘空间地址,也就是说一棵树的所有节点都是存在磁盘上的不同位置。每一个父节点都有两条单向链接指向左右子节点,单向链接存储着子节点的磁盘地址。父节点A可以通过单向链接上记录的磁盘地址找到子节点B的位置。
查找一个索引的时候需要将树的节点中的数据从磁盘加载到内存,这就会发生一次磁盘IO操作。如果这个节点的key不是我要找的索引值,就会根据单向链接中存的磁盘地址找到子节点的磁盘空间,读取到内存,这又是一次IO操作。
因此,从根节点每往下找一层子节点就是一次IO操作。
如果二叉树这种数据结构是按字段值从小到大或者从大到小的顺序来构建的话,就会完全退化为一个单向链表,复杂度就又变回了O(n),和全表扫描一行行遍历没什么区别。
例如,对上图中的col1这个字段建立二叉树索引就会发生这种情况。
结论:二叉树构建索引可能会退化为一个接近单向链表的结构,此时查找和排序的复杂度与全表扫描没有什么区别。因此二叉树不适合作为索引的数据结构
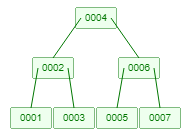
红黑树索引
红黑树的本质是一个二叉平衡树。红黑树每添加一个节点(例如是节点A)会检查该节点A左右两边的子分支是否平衡,如果该节点A的右边的层级大于该节点左边的层级超过2层,就会做一个节点的平衡(左旋),使得该节点A节点的左右两边的层数相等。
而红黑树的自动平衡功能可以解决二叉树退化为单向链表的问题
以上图中col1字段创建红黑树索引为例:
.png)
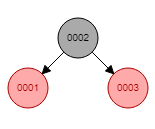
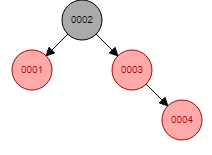
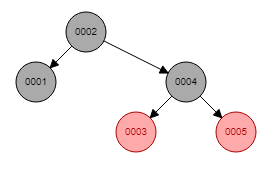
红黑树的复杂度也是 O(log2n),它的特点是添加或者删除节点的时候会自动平衡。
但是,用红黑树作为mysql数据表的索引还是存在问题的。
你想想看一个几百万的表用红黑树构建索引,这棵树就会有很多很多层,因为红黑树毕竟是一个二叉树,每个节点只能有两个分叉,所以数据一多,树的层级就多。当查找一个key比较大的数据时,就要从根节点一直找到底层叶节点,效率还是不高。当数据表中的记录数越多,红黑树的层级越高,查询效率就越低。
举个例子,用红黑树构建一个有100多万数据的表的索引,那么这个红黑树大概有20层。假如我查找的数据刚好在叶子节点,意味着我要在红黑树上查20个节点才能找到底层。
每往下层去遍历一个节点就是一次IO操作,就会发生20次磁盘io。
所以红黑树的瓶颈在于层数可能太多。我们希望能够在建立几百万的索引的基础上把树的层级控制在3~4层之内。
结论:红黑树构建索引的瓶颈在于存储大表索引时,树层级太多,导致查找发生的io次数多。
B-Tree索引(多叉平衡树)
B-Tree在红黑树的基础上采用了横向扩展的优化。普通二叉树和红黑树的一个节点只能存一个索引(一个节点的磁盘空间只存一个key-value数据),而B-Tree的每个节点可以存储多个索引(给一个节点分配一个大一些的磁盘空间存多个key-value数据)。所以B-Tree的每个节点可以有多个单向链接。
接下来我们看看一个保持在3层的B-Tree的构建过程
.png)
.png)
.png)
.png)
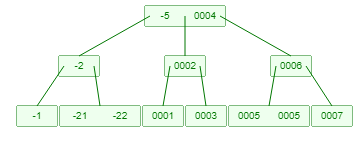
B Tree的特点
1. 所有的叶子节点的层级都是一样的且叶节点从左到右key是排好序的是递增的,例如上面 所有叶子节点都是在第三层。
2. B树的每个节点虽然有多个链接指向,但是每个索引还是只有2个链接指向,每一个索引构成的子树都满足二叉树的特性(右子节点比左子节点的key大)。
3. 单个节点内的多个索引是递增的有排序的。当往B树中插入一个索引的时候,索引被插入到一个节点会在这个节点中和其他索引进行排序排列。
结论:B树的横向扩展特性就很好的解决了红黑树层数过高的问题,但mysql还是没有选择B树作为索引的数据结构,原因是B树无法高效的做到范围查找。
B+Tree索引
B+ 树符合B Tree的所有特性。但是B+ Tree 的非叶子节点不存储value,只存储key(key就是索引字段的字段值,value是该索引字段对应的行的磁盘地址或者是索引所在行的其他列的实际数据,value存什么是因存储引擎的类型而异的)。这使得每个非叶子节点可以存放更多的索引(因为不存value节省了空间)。
B+树的每一个叶子节点之间维护这一个双向链接,这个双向链接存储着相邻叶节点的磁盘空间地址,使得相邻的叶节点可以找到对方的磁盘地址。
叶子节点会包含所有的索引字段的key和value。部分子节点的key会冗余存储一份在父节点中(如下图的44)。
B+树的一个节点在磁盘中表现为一个数据页,在添加或者删除行的时候可能会发生的节点平衡(页分裂或旋转)。
一个节点中的每一个索引的两条链接指针存储着其子节点的磁盘地址。
B+树的结构如下图
.png)
B+ 树的查找也是从根节点开始往下查。以查找上图中的53为例:
B+ Tree 的根节点是直接存在内存中的,所以第一个节点无需从磁盘读到内存。Mysql通过一定的算法(比如二分查找)得出53在50和66这两个索引之间,于是获取50和66之间的单向链接,这个链接存储着根节点的一个子节点的磁盘空间地址。于是根据这个地址从磁盘中读取[52 66]这个子节点的数据到内存。在内存中进行查找运算得到53在52和66之间,于是又获取到链接找到[52 53]这个叶节点,加载到内存,得到53号索引对应的value值。
B树和B+树通过横向扩展的方式让树保持一个比较低的层级,那么有一个问题:既然树的层级越低,查找索引的IO操作次数越少的话,可不可以将所有索引的key-value都放在一个节点中,这样就只有1层了?
首先要知道,在树中查找一个索引的时候,需要将节点从磁盘加载到内存中。如果几千万个索引都放在一个节点(大概会有几百兆)。一来为了找1个索引而把所有索引的数据加载到内存会很浪费内存;二来几百兆的数据从磁盘写到内存的速度也要很长时间。
所以这样做的效率很低很笨。
对于mysql而言,树的一个节点(无论是叶子节点还是非叶子节点)会被分配一个16K的大小的页来存多个索引,一个节点就是一个数据页。
我们可以查看mysql一页有多大
mysql> show global status like "Innodb_page_size";
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
我们从磁盘取行数据加载到内存的时候,不可能是从磁盘读一行数据到内存又再回到磁盘再读一行数据到内存,这样频繁的发生io效率会很低。因此实际情况是,每次从磁盘读取数据到内存的最小单位是一个页(B+树中一个节点),所以有时候虽然你只想查一行,但是还是会把一个页给读取到内存。
那么一棵B+树能存多少个索引(多少条行)呢?
以innodb表的主键索引为例,一个整型id大概占8B,每个索引的链接指针占6B,16K/14B = 1170; 所以一个非叶子节点大概能放1170个索引。而叶子节点保存着value和双向指针,假设value是索引字段所在行的其他字段的实际数据(假设平均是1K,指针大概占12B,可以忽略不计),那么一个叶子节点最多只有16个索引。
那么一棵3层的B+ Tree,大概能存储 1170*1170*16 = 两千多万 条数据。
所以两千多万条数据如果通过B+ Tree建立索引,要查找一行数据也就进行2次磁盘IO即可(因为B+树的根节点一般是直接加载在内存中的),花的时间也就两次IO的时间。
如果数据超过2千多万,那就增加 B+ 树的层数为4层即可。
Hash表索引
如果以Hash结构作为索引,mysql会建立一个hash表,这个hash表是这样的:先对索引列的值进行一个hash散列函数的计算得到一个散列值,以这个散列值作为key,以索引所在的行数据的磁盘地址作为value。将key和value存在一个高速的映射表中。这样下次根据索引查找行的时候就可以快速找到行所在的地址。
对于where条件为精确查找(where in/=)来说,hash表的结构比B+树的性能高。但是对于范围查找(>/</between)来说,还是要对mysql表进行逐行遍历,一个个的通过hash函数计算得到散列值,再通过散列值查hash表的value。
B+树是怎么进行范围查找的呢?这全靠B+树叶子节点之间的双向指针和叶子节点是有序的这两个特性。例如做出where id > 30 这样的范围查询,mysql会先通过B+树的查找算法找到30所在的叶子节点A,然后通过叶子节点A的双向链接找到了它右边相邻节点B的地址,然后通过B的链接找到了B的右边相邻节点C的地址,一直这样找下去,就获取到了 id > 30的数据。
考虑到同是兼顾精确查找和范围查找mysql还是使用了B+树而不用hash表。
B+ 树和B树的区别在于两点:
1. B树的叶子节点之间没有双向指针,不支持范围查找,如果B树要进行范围查找的话需要找到范围的左边界的索引所在的节点并从它开始进行中序遍历;
2. B树的非叶子节点包含了value,但是B+树的非叶子节点只有key没有value,由于B树的非叶子节点包含value就意味着相同层数的B树和B+树,B树能存储的索引个数远小于B+树。同样是3层数,B+数可以存 1170 * 1170 * 16 = 两千多万个索引,而B树只能存 16*16*16 = 4096个索引。如果用B树结构存一张两千多万的大表的索引,就需要大概7层。
不论是二叉树,红黑树,B树还是B+树,他们都是对数据排好序的结构,排好序的索引是高效查找的前提。“排好序”体现在一个节点的key比左节点的key大,比右节点的key小(叶子节点从左到右的key是从小到大的)。这也应了本文的第一句话:“索引是帮助mysql高效获取数据的排好序的数据结构”