更多优质内容
请关注公众号
请关注公众号

数组 Array
官方定义:
数组是指一个具有同一类型元素的固定长度序列。
数组的长度是不可变的,需要在声明数组的时候就要指定长度,而且元素个数超出这个长度就会报错(相当于在内存空间中申请了一块固定长度的空间,元素的内容不能超过这块空间的大小)。数组的 长度是该数组类型的一个内置常量(既然是常量肯定就不能变啦),可以用Go语言的内置函数len()来获取。
常规的数组声明方法:
[32] byte // 长度为32的数组,每个元素为一个字节
[2*N] struct { x, y int32 } // 复杂类型数组,N是一个已定义的常量
[1000]* float64 // 指针数组
[3][5] int // 二维数组
[2][2][2] float64 // 等同于[2]([2]([2]float64))
数组的遍历和元素访问(和字符串一样,两种方法,这里不再赘述)
数组在声明的时候就已经申请了指定长度的内存空间,并且为每个元素设定了默认值(零值)。
比如:
var array [5] string // 默认五个元素都是空字符。如果是int则默认5个都是0
fmt.Println(array)
我们可以这样给数组初始化
array := [5] int {1,2,3,4,5}
如果是这样呢
array := [5] int {1,2}
那么此时array就是 [1,2,0,0,0]
如果这样:
var array1 [10] int
array2 := [5] int {1,2,3,4,5}
array1 = array2
fmt.Println(array1,array2)
那么很抱歉,会报错,不能把一个数组变量赋值给另一个长度不符的数组变量(因为不同长度的数组是不同的类型)。
Go中数组的特点
A.数组中的元素是连续的,都在一块连续的内存空间中
这里我们与map这种类型进行对比
Map 中的元素是不连续的,元素与元素之间可能位于不同的内存空间。因此通过map1[xxx]来查找元素时会先根据下标xxx映射到元素的内存地址(先找到这个元素所在的内存地址)再从这个地址的空间读取元素值。
Array中的元素是连续的,都位于同一块内存空间,因此array[4]查找一个元素的话,需要先找到Array这块空间的地址,这个地址其实就是第一个元素的指针地址。要获取array[4]的内容,只需通过偏移量计算出第四个元素的指针地址即可(假如数组中类型是int8,第一个元素的指针地址是x,那么array[4]的地址就是 x + 4 * 8),系统就会直接到这个地址读第四个元素的内容。
所以Map和Array的获取和修改元素值操作都是一个O(1)操作。
但是由于Map的元素是不连续的,所以遍历的时候Map每一次迭代都要寻址跳到下一个元素的地址(因为是不连续的所以每次跳到一个地址可能要移动很多个偏移量),而Array只要移动几个字节的偏移量就能到达下一个元素的地址(因为是连续的)。因此Map的遍历效率比Array低。(说通俗点是因为Map的元素散布在不同的地方,相互之间距离很远,而Array的元素都集中在一个空间距离很近,还是连续的)
B.数组的长度在定义后不可变
C.值类型
在Go语言中数组是一个值类型(value type)。所有的值类型变量在赋值和作为参数传递时都将产生一次复制动作(就是在内存中又申请了一块大小和数据一模一样的空间)。如果将数组作为函数的参数类型,则在函数调用(不是传的时候复制,而是在函数中调用这个数组时才复制)时该参数将发生数据复制。因此,在函数体中无法修改函数外的数组的内容,因为函数内操作的只是所传入数组的一个副本。
例如:
func main() {
array1 := [5] int {1,2,3,4,5}
array2 := array1 // copy出一块新的空间放{1,2,3,4,5}
fmt.Println(array1,array2)
fmt.Println(array1 == array2) // true
}
再例如:
func main() {
array1 := [5] int {1,2,3,4,5}
modify(array1)
fmt.Println(array1)
}
func modify(array [5] int) {
array[0] = 10
fmt.Println(array)
}
结果:
[10 2 3 4 5]
[1 2 3 4 5]
如何在函数内改变函数外的数据结构呢?可以用切片。
切片 Slice
官方定义:
切片是一种变长的具有相同类型元素的序列。一个切片一定会对应一个数组,切片包含以下的内容:
1.一个指向数组的指针
2.切片中的长度len和容量cap
3.系统为切片创建的存储空间
一个切片的本质是一个结构体,结构体的内容如下
type IntSlice struct {
ptr *int // 指向底层数组的指针
len, cap int // 长度 和 容量
}
切片对长度和容量的访问是直接的(直接在自己的结构体中访问),对底层数组的访问是间接的(通过结构体的指针找到底层数组再访问)
这里注意,切片的指针指向的不是整个底层数组,而是指向底层数组的第一个元素。也就是说指针记录的是底层数组的第一个元素的地址(或者说,底层数组的第一个元素的地址就是底层数组的地址)
当创建一个切片X的时候,系统会为这个切片X创建一个存储空间A来存放X的指针/len/cap。
于此同时Go内部肯定会隐式的生成一个与切片X对应的数组Y并创建一个存储空间B来放这个数组Y(或者这个数组Y是之前已经存在的也可以),并且让切片X的指针指向这个数组Y。
如果将切片X赋值给另一个切片Z,那么此时只会复制多一份指针和存储空间A给Z,用于记录切片Z的信息,而不会复制多一份数组Y,这样就节省了空间。
创建一个切片的3种方式
例子1:基于已有的数组创建切片
arr := [10] int {1,2,3,4,5,6,7,8,9,10} // 创建一个有10个长度的数组
s1 := arr[:5] // 基于arr的前5个元素创建一个切片
fmt.Println(len(s1), cap(s1)) // 查看其长度和容量,结果是5 和 10
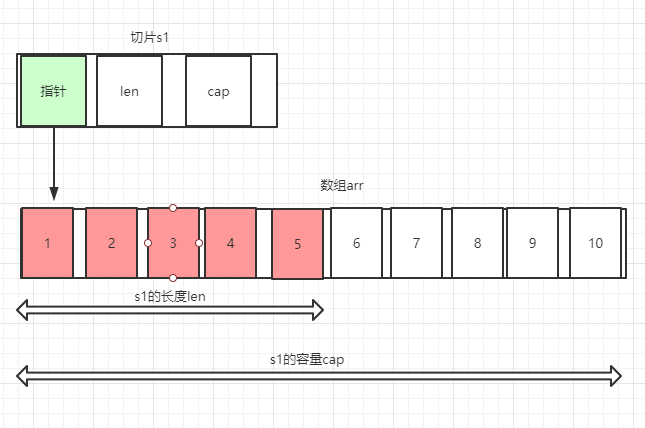
在这个例子中,s1只引用了arr的前5个元素,所以s1的长度为5,但是s1指向的数组的长度是10,所以s1的容量是10。
我们还可以
s := arr[:]
s := arr[5:]
例子2:直接创建一个切片(通过make()创建切片)
s2 := make([]int, 5) // 创建一个长度和容量都为5的切片,Go内部会创建一个大小为5,内容都是0的数组
fmt.Println(len(s2), cap(s2), s2)
// 结果为:5 5 [0 0 0 0 0]
s3 := make([]int, 5, 10) // 创建一个长度和容量都为5的切片,Go内部会创建一个大小为10,内容都是0的数组
fmt.Println(len(s3), cap(s3), s3) // 5 10 [0 0 0 0 0]; s3只引用了数组的前5个元素
例子3:直接创建一个切片(不通过make,通过:=直接创建切片)
s4 := []int {1,2,3,4,5} // 初始化一个切片
fmt.Println(len(s4), cap(s4), s4) // 5 5 [1 2 3 4 5]
// 注意,这里和初始化数组很像
arr2 := [5]int {1,2,3,4,5} // 初始化一个数组
arr3 := [...]int {1,2,3,4,5} // 初始化一个数组,和上一句没有区别,他会在编译的时候自动计算数组长度为5
fmt.Println(arr2, arr3)
如果 [] 里面有指定长度,那就是创建一个数组;没有指定长度,就是创建一个切片(内部也会隐式的创建一个数组)
例子4:基于一个切片创建一个切片
s5 := []int {1,2,3,4,5,6,7,8,9,10} // 创建一个有10个长度和容量的切片
s6 := s5[:5]
fmt.Println(len(s6), cap(s6), s6) // 5 10 [1 2 3 4 5]
s7 := s5[3:5:8] // 截取3~4两位,容量截取到第7位
fmt.Println(len(s7), cap(s7), s7) // 2 5 [4 5]
我们可以看到一个比较有趣的现象: s7
它其实是这样子的:
.png)
s7 = s5[3:5:8]的意思是s7引用数组的第3到第4这两个元素,容量范围是第3到第7个元素的范围,所以容量大小是5。
此时s7的指针其实指向了数组中的第四个元素的位置,并且引用了2个元素即4和5。
相比于数组长度不可变而言,切片是可以扩展长度的。
例子5:使用append给切片添加元素
s8 := make([]int, 3, 5) // 创建一个长度为3,容量为5的切片,Go内部会创建一个大小为5,内容都是0的数组
s9 := s8
s8 = append(s8, 100, 100)
fmt.Println(len(s8), cap(s8), s8) // 5 5 [0 0 0 100 100]
fmt.Println(len(s9), cap(s9), s9) // 3 5 [0 0 0]
s8 = append(s8, 100)
fmt.Println(len(s8), cap(s8), s8) // 6 10 [0 0 0 100 100 100]
fmt.Println(len(s9), cap(s9), s9) // 3 5 [0 0 0]
s8[1] = 10
fmt.Println(s8) // [0 10 0 100 100 100]
fmt.Println(s9) // [0 0 0]
让我们为上面的每行代码进行图解
s8 := make([]int, 3, 5)
s9 := s8
.png)
s8 = append(s8, 100, 100)
.png)
由于s8后面添加了两个元素,而且s8的长度原本为3容量为5,添加两个元素后,长度没有超过容量,所以s8还是引用原来的数组arr,只是长度刚好达到容量。
s8 = append(s8, 100)
此时s8的长度达到6,超过了容量5,Go内部会开辟一块新的空间存放数组arr2,大小扩展为s8容量的两倍(2倍是Go内部对切片扩容的规则,是按照切片的容量*2而不是按照数组的容量*2),并让s8指向arr2;而s9仍然指向arr1。
.png)
s8[1] = 10
由于s8和s9指向的是两个不同的数组,所以修改s8[1]不会影响到s9
例子6:
s8 := make([]int, 3, 5) // 创建一个长度为3,容量为5的切片,Go内部会创建一个大小为5,内容都是0的数组
s9 := s8
s8 = append(s8, 100, 100)
fmt.Println(len(s8), cap(s8), s8) // 5 5 [0 0 0 100 100]
s9 = append(s9, 50)
fmt.Println(len(s9), cap(s9), s9) // 4 5 [0 0 0 50]
fmt.Println(len(s8), cap(s8), s8) // 5 5 [0 0 0 50 100]
这里对s9添加一个元素50居然影响到了s8,其实原因很简单,因为s8和s9都指向同一个arr,所以对s9添加一个元素50,会修改底层的数组的第四个元素为50,从而修改了s8。
像上面一样画个图就可以很容易理解。
例子7:
s5 := []int {1,2,3,4,5,6,7,8,9,10} // 创建一个有10个长度和容量的切片
s7 := s5[3:5:8]
fmt.Println(len(s7), cap(s7), s7) // 2 5 [4 5]
s7 = append(s7, 100, 100, 100, 100)
fmt.Println(len(s7), cap(s7), s7) // 6 10 [4 5 100 100 100 100]
fmt.Println(s5) // [1 2 3 4 5 6 7 8 9 10]
图解:
.png)
在执行s7 = append(s7, 100, 100, 100, 100)的时候,由于s7的cap容量不足,所以会在内存中重新创建一个扩容后的数组(s7的原本容量是5,扩容按照2倍来扩,所以新的s7的容量为10),s7重新指向这个新数组,就变成了这样:
.png)
由于s5和s7不是指向同一个数组,所以,s7的append不会影响到s5的内容。
但是我们看看下面这种情况:
例子8:
s5 := []int {1,2,3,4,5,6,7,8,9,10}
s7 := s5[3:5:8]
fmt.Println(len(s7), cap(s7), s7) // 2 5 [4 5]
s7 = append(s7, 100, 100, 100)
s7 = append(s7, 100)
fmt.Println(len(s7), cap(s7), s7) // 6 10 [4 5 100 100 100 100]
fmt.Println(s5) // [1 2 3 4 5 100 100 100 9 10]
例子8和例子7的区别就是:例子8的s5被改变。
其实原因很简单,第一次append的时候 s7 = append(s7, 100, 100, 100) 由于没有超过s7的容量,所以s5和s7还是共用的1个底层数组,因此s7添加元素的时候也会修改s5所指向的底层数组的第6和第7个元素。
第二次append的时候才为s7新分配了一个扩容后的数组,并拷贝s7所引用的原来那个数组的数据到新数组中。但是原数组已经被改变了,s5就受到影响了。
切片的遍历和数组一模一样,不再赘述。
从上面的例子我们知道可动态增减元素是数组切片比数组更为强大的功能,对于切片而言,切片实际元素个数和分配的空间可以是两个不同的值。
append方法的第2参除了可以传入元素,还可以传入切片,表示将这个切片里面的所有元素添加到第1参的切片中。
append(slice1, slice2...)
...表示将slice2中的元素打散后一一传入append中。
例子9:基于切片创建切片时,新切片可以包含超过旧切片的元素范围
arr := [5]int {1,2,3,4,5}
s10 := arr[:3]
s11 := s10[:4]
fmt.Println(len(s11), cap(s11), s11) // 4 5 [1 2 3 4]
s12 := s10[:6] // 报错
fmt.Println(len(s11), cap(s11), s11)
s13 := s10[:3:3]
fmt.Println(len(s13), cap(s13), s13) // 3 3 [1 2 3]
s14 := s13[:4] // 报错
fmt.Println(len(s14), cap(s14), s14)
s10只有 [1,2,3] 3个元素,而s11要获取s10的前4个元素,其实是可以的,他会去拿底层数组arr的前4个元素。
但是s12就不行,因为s12要拿的元素超过了s10的cap容量范围。
s13限定了获取arr的前3个元素,而且限定容量也是3,s14拿s13的前4个元素就会报错,因为超过了s13的cap容量
例子10:切片的拷贝copy()
切片的拷贝copy(a,b)是将一个切片b复制给切片a。如果b的长度为5,a的长度为3,那么b只把前3个元素复制给a。如果a的长度为5,b的长度为3,那么b把3个元素复制给a,a的后两个元素保留。
Copy返回的是复制的元素个数。
例10-1:
s11 := []int {7, 8, 9}
s12 := []int {1,2,3,4,5}
copy(s12, s11)
fmt.Println(cap(s11), s11, cap(s12), s12) // 3 [7 8 9] 5 [7 8 9 4 5]
s12[1] = 100
fmt.Println(cap(s11), s11, cap(s12), s12) // 3 [7 8 9] 5 [7 100 9 4 5]
这个例子中,s11和s12是指向两个不同的底层数组。Copy操作将s11的元素拷贝到s12的前三个元素,底层体现为将s11对应的底层数组的元素内容拷贝到s12对应的底层数组的前3个元素。
例10-2:
s13 := []int {1,2,3,4,5}
s14 := s13[2:]
fmt.Println(cap(s13), s13, cap(s14), s14) // 5 [1 2 3 4 5] 3 [3 4 5]
copy(s13, s14)
fmt.Println(cap(s13), s13, cap(s14), s14) // 5 [3 4 5 4 5] 3 [5 4 5]
这个例子会发现,将s14复制给s13之后,s13的结果变了,但是s14的结果也变了(从[3,4,5]变为[5,4,5]),原因很简单,s13和s14共享一个底层数组,所以改变s14也会影响到s13。
注意,切片的拷贝只能在两个相同类型的切片进行,如果是将整型的切片拷贝给一个字符串的切片会报错。
如果我们声明一个切片但是没给他初始化。这个切片的长度和容量都是0,底层没有创建数组(此时的s0其实是一个nil)
var s0 []string
fmt.Println(len(s0), cap(s0), s0) // 0 0 []
切片无法访问到长度以外,容量以内的元素。
s19 := []int {1,2,3,4,5}
s20 := s19[:2:cap(s19)] // s20的容量为5,长度为2
fmt.Println(s20[0]) // 1
fmt.Println(s20[4]) // 报错,因为s20没有下标为4的元素,即使s20的容量为5
归纳点:
切片本质上是对数组的指针+内置的记录其长度和容量。所以相比与数组而言,切片是一种轻量型的数据类型。在将切片作为参数传递给函数的时候,只是会在内存中多创建一个切片结构(即指针+长度+容量的一个结构体)引用原有数组,而不会多创建一个数组。所以在函数中修改切片A会影响函数外的引用同一底层数组的切片B。
上面我们说到,切片在添加元素时如果超过了容量会在底层创建一个新数组,而且容量为原容量的2倍。为什么扩容会按照2倍来扩?
这是为了避免频繁的进行内存分配和数据拷贝。加入扩容是按照+1来扩,而不是按照*2来扩,那么我每次append都会发生新的内存分配以生成一个新的底层数组,并且拷贝原数组的数据到新的数组上,那么append效率就会大大降低。
如果按照*2来扩就可以大大减轻这种问题。
接下来,我们介绍一些操作切片的技巧
例子11:反转一个切片
func reverse(s []int) {
for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 {
s[i], s[j] = s[j], s[i]
}
}
func main() {
s15 := []int {1,2,3,4,5}
reverse(s15)
fmt.Println(s15)
}
例子12:删除一个切片中的某元素
// 删除s中的第i个元素,要求不影响原切片
func remove(s []int, i int) (new_s []int) {
new_s = append(new_s, s[:i]...)
new_s = append(new_s, s[i+1:]...)
return new_s // new_s和s指向两个数组,互不影响
}
func main() {
s16 := []int {1,2,3,4,5}
s17 := remove(s16, 2) // 移除3这个元素
fmt.Println(s17, cap(s17)) // s17是[1,2,4,5]
fmt.Println(s16) // s16还是[1,2,3,4,5],说明remove没有影响原切片s16
}
那么如何写一个会影响原切片的remove呢?
func remove(s []int, i int) []int {
copy(s[i:], s[i+1:])
return s[:len(s)-1]
}
如果删除元素后不用保持原来的顺序,我们可以将最后一个元素覆盖要删的元素。
func remove(s []int, i int) []int {
s[i] = s[len(s) -1]
return s[:len(s) - 1]
}
和数组不同的是,slice之间不能比较,因此我们不能使用==操作符来判断两个slice是否含有全部相等元素。
标准库提供了高度优化的bytes.Equal函数来判断两个字节型slice是否相等([]byte),但是对于其他类型的slice,我们必须自己展开每个元素进行比较:
func equal(s1 []int, s2 []int) bool {
if len(s1) != len(s2) {
return false
}
for i := range s1 {
if s1[i] != s2[i]{
return false
}
}
return true
}
slice唯一合法的比较操作是和nil比较
if summer == nil { /* ... */ }
slice切片的零值是nil(此时没有为他创建底层数组),但是不为nil的切片也可能是一个空切片(就是创建了底层数组,但是底层数组没有元素)。
var s []int // len(s) == 0, s == nil
s = []int{} // len(s) == 0, s != nil
所以如果你需要测试一个slice是否是空的,使用len(s) == 0来判断,而不应该用s == nil来判断。因为len(s)==0的判断方式对零值切片和非零值空切片都使用。
注意,如果我们声明了一个空切片,想往空切片中一个个的添加元素
var a []int
a[0] = 1
a[1] = 2
这样会报错,因为a的容量和长度都为0,根本没有下标为1和2的元素。
应该这样才对:
a = append(a, 1)
a = append(a, 2)
最后一个例子是切片被传入函数后在函数中对其操作会如何影响函数外的切片:
package main
import "fmt"
func main() {
sl := make([]int, 0, 32)
changeSlice(sl)
fmt.Println(sl) // []
}
func changeSlice(sl []int){
sl = append(sl,5, 5, 5)
fmt.Println(sl) // [5, 5, 5]
}
从程序的运行结果来看,在changeSlice函数内对sl切片改变不会影响函数外的sl。但实际上切片已经被影响。
我们知道切片本质是一个这样的结构体
type IntSlice struct {
ptr *int // 指向底层数组的指针
len, cap int // 长度 和 容量
}
结构体作为参数传入函数是值拷贝,因此changeSlice内外的sl是两个不同的结构体,但是这两个结构体的ptr数组指针指向的是同一个数组。
所以执行changeSlice函数内的append时,函数内的sl的len变为3,函数外的sl的len还是0。但是他们共同指向的数组已经变成[5, 5, 5]。函数外的sl打印出来是[],是因为它的len为0,所以数组的3个元素相当于被隐藏了。
解决方法:想要在函数内影响函数外的切片变量,只需传切片的指针而不是传切片本身即可