更多优质内容
请关注公众号
请关注公众号

Go 语言将 I/0 操作封装在以下几个包中。
io :为IO原语提供基本的接口,在 io 包中最重要的是两个接口-一-Reader 和 Writer 接口。本章所提到的各种包,都和这两个接口有关,只要程序实现了这两个接口,它就有了IO功能
ioutil :封装一些实用的 I/O 函数,这个包主要提供了一些常用、方便的 I/O 操作函数
fmt :实现格式化IO
bufio:实现带缓冲的 I/O 。它封装于 io.Reader 和 io.Writer 对象,创建了 另一个对象( Reader和Writer ),在提供缓冲的同时实现了一些文本 I/O 的功能
io.Reader 和 io.Writer 接口
Reader接口源码:
type Reader interface {
Read(p []byte) (n int, err error)
}
只要实现了Read方法的类型就是io.Reader接口类型,Read方法需要传入一个自定义的字节切片p,Read()可以从一个可读对象中读取一定长度的数据到字节切片p中,并返回本次读取的长度n和可能发生的错误err。
Read方法有以下规则:
需要注意的是,传入的p必须是一个有长度的切片不能是长度为0的切片,因为Read每次从可读对象读取的数据最大长度就是len(p)。如果len(p) 为 0,即使可读对象有数据可读,Read也无法读取到数据。
下面我们写一个从标准输入读取数据的示例
func main(){
s := os.Stdin
cont, err := readFrom(s, 10)
fmt.Println(string(cont), err)
}
// num是每次读取的数据长度
func readFrom(r io.Reader, num int) (cont []byte, err error){
for {
p := make([]byte, num) // 每次循环都要创建长度为num的字节切片用于接收可读对象的数据
n, err := r.Read(p)
fmt.Println(n, err) // 打印每次接收到的数据
if n >0 {
cont = append(cont, p...) // 如果读到有数据,那么不论本次读取有没有错误都先接收了这部分数据先
}
if err == io.EOF{ // 如果是EOF的错误表示所有结束读取,此时将err置空并停止读取
err = nil
break
}
}
return cont, err
}
在屏幕上输入 Ctrl + D 就相当于输入EOF结束符。
错误的写法(将p的定义放在for之外):
p := make([]byte, num)
for {
// ...
}
这样的话会出现一个问题,当某次Read读取的长度不足len(p)的时候,p中的内容就会有部分更新,剩余部分还是原来的旧数据,导致数据混乱。
如果遇到err为EOF时不停止循环,那么每次之后会继续不停的从可读对象Read空内容,而且每次Read都会立刻返回,且每次返回的err都是EOF(相当于空转)。
运行结果
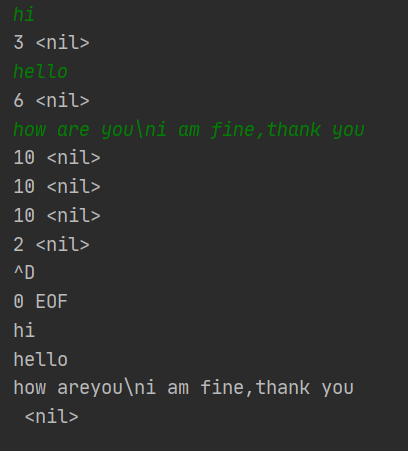
绿色部分是我输入,白色部分是程序输出
Writer接口源码:
type Writer interface {
Write(p []byte) (n int, err error)
}
Write会往一个可写对象(Writer对象)写入长为len(p)的数据内容,数据来自p切片。如果可写对象的写事件未就绪(例如可写对象的缓冲区满了),Write方法就会阻塞。
如果n<len(p)就会(就要)返回非nil的err。
Write方法绝对不能修改切片p和里面的数据(系统提供的标准库的Write方法肯定不会这样做,但是如果我们自己实现一个Write方法的时候就要注意这点)。
fmt包
下面主要介绍fmt包的 Print 和 Scan 系列函数。
Print系列函数包括 Fprint/Fprintf/Fprintln/Sprint/Sprintf/Sprintln/Print/Printf/Println
Scan系列函数包括Fscan/Fscanf/Fscanln/Sscan/Sscanf/Sscanln/Scan/Scanf/Scanln
无论是Print 还是 Scan 系列,他们都以F开头的函数作为基础,也就是说Print系列的其他函数是通过内部调用F开头的函数来实现的。
F开头的函数可以传入io.Writer和io.Reader指定从哪个可读或可写对象中读取或输出
f结尾的函数可以用占位符格式化如 Fprintf Sprintf Printf Fscanf Sscanf Scanf
S开头的函数不打印而是只返回给变量
ln结尾的函数会在打印时换行
Print 和 Scan的区别在于前者功能是输出和打印,后者是输入和接收(他们相当于是一对相反操作的系列函数),因此Fprintf 或Fscanf会接收一个io.Writer或io.Reader作为输出的目的地或输出的来源 。
例如:
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {
// ...
}
func Fscanf(r io.Reader, format string, a ...interface{}) (n int, err error) {
// ...
}
无论是Print系列还是Scan系列,他们的非S开头的函数都是返回一个n和err,与前面的io.Reader的Read和io.Writer的Write方法一样。
之前的章节中已经演示了很多的Print系列的函数。所以在这里只演示Scan系列函数
以Fscanln为例
func main(){
var cont1, cont2, cont3 string
fmt.Fscanln(os.Stdin, &cont1, &cont2, &cont3)
fmt.Println(cont1, cont2, cont3)
}
这个程序从标准输入中读取内容并且赋值到cont1 cont2 cont3中。
需要注意的是Scan系列的函数用来接收数据的变量必须是指针或者引用类型,这样Scan系列的函数才能在函数内影响到他们。
另外Scan系列函数给传入的变量进行赋值是是以空格或者换行符来分割的,例如上面的例子,一开始会阻塞,当有屏幕输入的时候就会被唤醒,我输入了
hi! how are you
结果 cont1 cont2 cont3分别是 hi!和how和are
Fscanln与Fscan的区别在于,前者会把换行当作结束符空格当作分隔符,后者会把换行和空格都当作分隔符。
例如,使用Fscan
输入
hi
hello
how are you
得到
hi hello how
但是如果用Fscanln来运行,还是输入
hi
hello
how are ytou
结果只能得到hi。在遇到第一个换行的时候就结束了,所以cont2和cont3都没接收到值。
如果说F开头的scan系列的函数可以指定输入源的话,纯Scan系列的函数就只是以标准输入作为输入源,S开头的scan系列的函数则只能以普通的字符串作为输入源。除了这个区别以外,其他功能都和F开头的scan系列函数相同
例如:
func main(){
var cont1, cont2, cont3 string
fmt.Sscanln("hello, my name is zbp", &cont1, &cont2, &cont3)
fmt.Println(cont1, cont2, cont3)
}
得到
hello, my name
func main(){
var cont1, cont2, cont3 string
fmt.Sscanln("hello, my\nname is zbp", &cont1, &cont2, &cont3)
fmt.Println(cont1, cont2, cont3)
}
得到
hello, my
cont3没有接收到。
func main(){
var cont1, cont2, cont3 string
fmt.Sscan("hello, my\nname is zbp", &cont1, &cont2, &cont3)
fmt.Println(cont1, cont2, cont3)
}
得到
hello, my name
func main(){
var (
cont1 string
cont2 []byte
cont3 int
)
fmt.Sscanf("hello, age 40", "%s%v%d", &cont1, &cont2, &cont3)
fmt.Println(cont1, cont2, cont3)
}
得到
hello, [97 103 101] 40
scan系列函数用的还是比较少的,因此仅作了解即可。
path包 路径操作
Base()与Dir()返回一个路径字符串的目录和文件名部分,Ext()返回文件扩展名。
os.PathSeparator表示路径分隔符,他会根据不同文件系统而不同。
func main(){
dir := "/root/zbp/blog/"
dir2 := "/root/zbp/blog"
file := "/root/zbp/blog/1.txt"
file2 := "/root/zbp/blog/1"
fmt.Println(path.Dir(dir)) // /root/zbp/blog
fmt.Println(path.Dir(dir2)) // /root/zbp
fmt.Println(path.Dir(file)) // /root/zbp/blog
fmt.Println(path.Dir(file2)) // /root/zbp/blog
fmt.Println(path.Base(dir)) // blog
fmt.Println(path.Base(dir2)) // blog
fmt.Println(path.Base(file)) // 1.txt
fmt.Println(path.Base(file2)) // 1
fmt.Println(path.Ext(dir)) // 空字符串
fmt.Println(path.Ext(file)) // .txt
}
需要注意的,Dir函数在处理 “/root/zbp/blog/” 和 “/root/zbp/blog”的返回值不同。
Base在获取路径最后一个元素时会默认把最后的/去掉再获取,如果路径是空则返回’.’,如果路径是’/’则返回’/’。
path和filepath包下的一些其他的方法,这些方法有些是path包的有些事filepath包的
func IsAbs(path string) bool // 是否时绝对路径
func Abs(path string) (string, error) // 返回绝对路径,这个是filepath包的函数
func Rel(basepath, targpath string) (string, error) // 返回targpath相对于basepath的相对路径
func Join(elem ...string) string // 拼接路径
func Split(path string) (dir, file string) // 将路径分割为目录和文件名部分
func Clean(path string) string // 简化一个路径(去掉重复的/和.和..)
func Walk(root string, walkFn WalkFunc) error // 遍历一个路径下的表层文件,并将这些文件放到walkFn这个回调函数处理
os包 文件系统操作
文件系统的操作依赖于os包,os包兼容了各种操作系统的文件操作并返回一些统一后的接口。syscall包则会根据不同的操作系统提供一些特殊功能。os依赖于syscall,但我们应该优先使用os提供的功能。
在go中,文件(非目录的文件)用文件对象os.*File来表示
os.File的源码如下:
type File struct {
*file // os specific
}
type file struct {
pfd poll.FD
name string
dirinfo *dirInfo // nil unless directory being read
appendMode bool // whether file is opened for appending
}
当我们创建或者打开一个文件的时候就可以拿到这样的一个文件对象或者说资源标识符。
此外,我们还会经常看到os包的一些文件操作的函数会返回 os.FileInfo 这样的类型,它是一个文件的信息描述对象,获取一个文件的信息描述对象是不用打开文件的。
os.FileInfo源码如下:
type FileInfo interface {
Name() string // base name of the file
Size() int64 // length in bytes for regular files; system-dependent for others
Mode() FileMode // file mode bits
ModTime() time.Time // modification time
IsDir() bool // abbreviation for Mode().IsDir()
Sys() interface{} // underlying data source (can return nil)
}
下面看看os提供了哪些操作文件的方法:
创建目录
func Mkdir(name string, perm FileMode) error // 创建目录
func MkdirAll(path string, perm FileMode) error // 递归创建目录,如果目录已存在则不执行该操作
创建文件
os.Create()方法创建一个文件,返回一个 os.*File文件对象,f可读可写,若文件已存在则直接打开。
func main(){
f, err := os.Create("./1.txt") // 创建一个文件,返回一个 os.*File文件对象,f可读可写。默认权限0666
if err != nil {
log.Fatal(f)
}
defer f.Close()
f.WriteString("Hello")
f.Close()
}
不要试图在可读可写状态的*File下先写后读,这样是读不到内容的,因为写完之后文件指针就到了末尾了。
打开文件
func Open(name string) (*File, error) // 以只读方式打开文件
func OpenFile(name string, flag int, perm FileMode) (*File, error) // 以指定模式打开文件,第二参就是模式
打开模式 如下:
.png)
打开模式可以组合使用,例如:
os.OpenFile("./1.txt", os.O_CREATE | os.O_WRONLY, 0777)
以写的方式打开,如果文件不存在则创建。
下面我们看一个文件写入的例子:
func main(){
f, err := os.OpenFile("./1.html", os.O_CREATE|os.O_WRONLY, 0777)
if err != nil {
log.Fatal(err)
}
defer f.Close()
cont := `....` // 一个网页的html内容,大概300K
cont_bytes := []byte(cont)
seek := 0
fmt.Println(len(cont_bytes))
for {
c := cont_bytes[seek:seek+1024]
n,err := f.Write(c)
//f.Sync()
fmt.Println(seek)
if err != nil{
fmt.Println(err)
break
}
seek += n
time.Sleep(3*time.Second / 100)
if seek > len(cont_bytes)-1{ // 写入完毕
break
}
}
}
循环写入1024个字节到文件中,每次循环都会睡0.03秒。睡眠的目的是为了查看每次Write之后文件大小是否都变化了。
结果是这个过程中文件大小一直都是0,只有到了最后程序结束的时候文件的大小从0变为328K。
这说明Write方法会先把内容写入到缓冲区中,不会直接刷到磁盘,只有在所有Write都结束之后才会写入到磁盘。
如果希望能够每次写入后都进行刷盘的话,可以每次调用完Write后调用f.Sync()方法。
所以如果是复制一个大文件例如几G的视频的时候,要注意要手动调用Sync方法刷盘,否则内存可能会被撑爆。
当然了,频繁的调用sync方法进行刷盘会降低效率(毕竟刷盘是写入磁盘,是一次系统调用,写入磁盘的速度远比内存操作慢),我尝试将一个150M的文件通过循环调用Write方法复制到另一个地方。每次写入1K。如果每次循环都手动刷一次盘,总共花了19秒,不手动刷盘只花了5.5秒。但是如果我把每次写入的大小从1K调为40K,那么手动刷盘也只花了5.7秒。
所以如果希望手动刷盘不会降低效率的话,可以调大每次Write方法写入的大小(也是每次刷盘的大小),或者可以降低刷盘的频率,比如不要每循环1次刷一次盘,而是每循环20次才刷一次盘。
查看文件或者目录的状态
func Stat(name string) (FileInfo, error)
返回的FileInfo对象可以调用方法获取文件或者目录的信息,具体的方法如上os.FileInfo源码所示。
如果要查看某个文件或目录是否存在,可以在调用Stat方法之后通过判断返回的err来做到。如果err不为空而且调用 os.IsNotExist(err)返回true就说明文件不存在。
重命名和剪切
func Rename(oldpath, newpath string) error
删除文件
func Remove(name string) error // 删除一个文件
func RemoveAll(path string) error // 递归删除
func Truncate(name string, size int64) error // 从0裁剪文件到指定长度
如果传入0则清空文件
文件的读取可以使用
f.Read方法
如果希望一次性读取某文件的所有内容可以这样:
fileInfo, _ := os.Stat("./1.html")
fileSize := fileInfo.Size()
f, _ := os.Open("./1.html")
c := make([]byte, fileSize)
f.Read(c)
fmt.Printf("%s", c)
文件的写入可以使用
f.Write
f.WriteString
方法
前者是写入字节,后者是写入字符串,后者的好处是无需开发者将一个字符串转为字节切片再调用Write写入,可以节省一次数据从String到[]byte的拷贝
缓冲区bytes.Buffer 类型
关于bytes.Buffer类型的内容,我是参考的这位兄弟的文章:
Go标准库中的bytes.Buffer(下文用Buffer表示)类似于一个FIFO的队列,它是一个流式字节缓冲区,其底层的结构是一个字节切片。
我们可以持续向Buffer尾部写入数据,从Buffer头部读取数据。当Buffer内部空间不足以满足写入数据的大小时,会自动扩容。因此bytes.Buffer也是一个动态缓冲区,是一个容量可变的缓冲区。
流式字节缓冲区一般会有两个下标位置:写入位置(下文用ePos表示),读取位置(下文用bPos表示)。
bPos和ePos一开始都为0,ePos随写入内容时后移,bPos随读取内容时后移。
bPos永远小于等于ePos。
ePos减bPos即为待读取的内容大小(下文用content以及contentSize表示)。
整个内存块的大小(下文用capacity表示)减去ePos,即为将可直接写入内容的大小(下文用eIdle表示)。
.png)
写入时,逻辑如下:
当需写入内容的大小(下文用neededSize表示)小于eIdle时,直接在尾部追加写入即可。
由于已写入Buffer的内容有一些可能已被上层读取(即bpos前的空间),所以实际上bpos前面的空间(下文用bIdle表示)也是空闲的。
当neededSize超过eIdle时,此时有两种情况:
1. 如果eIdle加上bIdle大于neededSize,可以将content向左平移拷贝至从0位置开始,将bPos设置为0,ePos设置为刚才的(epos-bpos)。此时,eIdle变大,可直接在尾部追加写入。
2. 如果eIdle加上bIdle仍然小于neededSize,只能重新申请一块更大的内存,将当前待读取内容拷贝至新内存块,并将老内存块释放。然后在新内存块的尾部追加需写入的内容。
无论是哪两种都会发生数据的拷贝(平移是数据在一块内存中的拷贝转移)。
但是实际上,Buffer的实现和上面所说有些细微区别,或者可以说是一种优化吧:
当neededSize超过eIdle时,只要contentSize加neededSize超过当前capacity的一半时,就进行扩容。即扩容策略更为激进,目的是减少后续平移拷贝频率,空间换效率。
另外,Buffer扩容后新内存块的大小为:(2 * 当前capacity) + neededSize。
最后,Buffer只有扩容策略,没有缩容策略,即扩容到多大就占多大的内存,即使内部contentSize很小,而capacity已增长到非常大。当前使用的内存块只有在Buffer对象释放时才能随之释放。
Buffer在创建时并不会申请内存块,只有在往里写数据时才会申请,首次申请的大小即为写入数据的大小(因为首次申请的时候切片容量capacity=0, 所以申请的大小为 2*capacity+neededSize = neededSize)。
Buffer底层使用单个[]byte切片实现。
capacity,即切片的cap。
bPos使用了一个整型变量存储,即off。
ePos运用了Go切片的特性。Go的切片实际上是一个结构体,包含了len, cap, p三个数据成员。当我们操作Buffer时,除了初始化和扩容时会重新申请底层内存块,其他时候只是对切片重新切片,也即只是改变了切片的len属性,以及p的指向,底层被指向的那整块内存块并不会发生改变。切片当前的len就是当前的ePos。
但是bytes.Buffer类型也有一个Len()方法用来获取缓冲区的长度,这个长度其实是当前切片的len - off(即ePos - bPos的位置,即content的长度,所以Len()是不包括已读数据bIdle的长度的)
接下来是一些bytes.Buffer的方法和实现的接口
其中,WriterTo和ReaderFrom方法就是全部写入和全部读取(ioUtil.ReadAll和WriteAll就是通过bytes.Buffer的ReaderFrom和WriterTo实现的)。
还需要注意的是Truncate 和 Grow 方法。
Truncate相当于是把bPos指针往右移动n位,虽然Read也会使得bPos指针往有移动n位,但是他们的区别是Read会把读到的这n位内容拷贝到传入的p参数中,调用方就可以获取到这部分数据,Truncate则直接移动bPos指针而已不会发生拷贝,调用方获取不到这n位数据,因此对于调用方而言,这部分数据就好像删除了似的。
Grow方法的作用是让eIdle的长度保持n的大小,这个操作可能是平移content也可能是扩容,但是都会做出数据的拷贝。
// ---------- 满足了一些比较重要的interface
// 将Buffer读取(拷贝)到p
// @满足 interface io.Reader
func (b *Buffer) Read(p []byte) (n int, err error)
// 将p写入(拷贝)Buffer
// @满足 interface io.Writer
func (b *Buffer) Write(p []byte) (n int, err error)
// 死循环读取r的内容,写入(拷贝)Buffer中,直到读取失败
// @满足 interface io.ReaderFrom
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error)
// 将Buffer的内容全部写入(拷贝)w中
// @满足 interface io.WriterTo
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error)
// ---------- 满足了一些其他interface
// 读取一个字节
// @满足 interface io.ByteReader
func (b *Buffer) ReadByte() (byte, error)
// 撤销一个字节的读操作
// 撤销是有前提的,比如前一个操作不能是写相关的操作,也不能是撤销的操作
// @满足 interface io.ByteScanner
func (b *Buffer) UnreadByte() error
// 和 UTF8 Unicode 相关的读取
// @满足 interface RuneReader
func (b *Buffer) ReadRune() (r rune, size int, err error)
// 撤销一个rune的读操作
// @满足 interface RuneScanner
func (b *Buffer) UnreadRune() error
// 写入一个字节
// @满足 interface io.ByteWriter
func (b *Buffer) WriteByte(c byte) error
// 见 func Write
// @满足 interface StringWriter
func (b *Buffer) WriteString(s string) (n int, err error)
// ----------
// 整个待读取的内容,类似于peek预览
// @并不会真正消费
// @不发生拷贝
func (b *Buffer) Bytes() []byte
// 预览待读取内容的前n个字节
// @并不会真正消费
// @不发生拷贝
func (b *Buffer) Next(n int) []byte
// 见 func Bytes
func (b *Buffer) String() string
// 待读取内容的大小
func (b *Buffer) Len() int
// 总容量大小
func (b *Buffer) Cap() int
// 读取直到delim字符的内容
// @消费
// @发生拷贝
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error)
// 见ReadBytes
func (b *Buffer) ReadString(delim byte) (line string, err error)
// ----------
// 丢弃待读取内容的前n个字节
func (b *Buffer) Truncate(n int)
// 清空所有数据
func (b *Buffer) Reset()
// 确保有n大小的剩余空间可供写入
func (b *Buffer) Grow(n int)
// 将r写入
func (b *Buffer) WriteRune(r rune) (n int, err error)
// ---------- 创建
// 创建Buffer对象时就写入buf
func NewBuffer(buf []byte) *Buffer
// 见 func NewBuffer
func NewBufferString(s string) *Buffer
接下来我们看一下go中的不同的读写文件方式以及他们的效率,下面的内容参考
https://blog.csdn.net/c_j33/article/details/82957394
go中文件常见读取方式有3种:直接使用os包的open和read、使用bufio包读取、使用ioutil读取
func readRaw(path string) string {
start := time.Now()
fi, err := os.Open(path)
if err != nil {
panic(err)
}
defer fi.Close()
defer func() {
fi.Close()
fmt.Printf("[readRaw] cost time %v \n", time.Now().Sub(start))
}()
var data []byte
buf := make([]byte, 1024)
for {
n, err := fi.Read(buf)
if err != nil && err != io.EOF {
panic(err)
}
data = append(data, buf[:n]...)
if 0 == n {
break
}
}
return string(data)
}
func readWithBufferIO(path string) string {
start := time.Now()
fi, err := os.Open(path)
if err != nil {
panic(err)
}
defer func() {
fi.Close()
fmt.Printf("[readWithBufferIO] cost time %v \n", time.Now().Sub(start))
}()
r := bufio.NewReader(fi)
var data []byte
buf := make([]byte, 1024)
for {
n, err := r.Read(buf)
if err != nil && err != io.EOF {
panic(err)
}
if 0 == n {
break
}
data = append(data, buf[:n]...)
}
return string(data)
}
func readWithIOUtil(path string) string {
start := time.Now()
fi, err := os.Open(path)
if err != nil {
panic(err)
}
defer func() {
fi.Close()
fmt.Printf("[readWithIOUtil] cost time %v \n", time.Now().Sub(start))
}()
fd, err := ioutil.ReadAll(fi)
return string(fd)
}
func main() {
file := "test.txt"
readRaw(file)
readWithBufferIO(file)
readWithIOUtil(file)
}
文章的作者分别用这3个函数去读取一个大小为330M的文件,耗时如下:
[readRaw] cost time 1.490717874s
[readWithBufferIO] cost time 573.336617ms
[readWithIOUtil] cost time 379.678285ms
[readRaw] cost time 1.45133396s
[readWithBufferIO] cost time 541.944555ms
[readWithIOUtil] cost time 983.909509ms
发现用os包的Read最慢,而用bufio和ioutil包读则不分伯仲。
接下来我们从源码层面去解释这个现象
首先我们看一下用 bufio读取,bufio顾名思义是带缓冲的读取。
readWithBufferIO先创建了一个bufio读取器NewReader,源码如下
package bufio
// NewReader returns a new Reader whose buffer has the default size.
func NewReader(rd io.Reader) *Reader {
return NewReaderSize(rd, defaultBufSize)
}
// NewReaderSize returns a new Reader whose buffer has at least the specified
// size. If the argument io.Reader is already a Reader with large enough
// size, it returns the underlying Reader.
func NewReaderSize(rd io.Reader, size int) *Reader {
// Is it already a Reader?
b, ok := rd.(*Reader) // 用断言做类型转换,把rd从原本的Reader类型转为bufio.Reader类型
if ok && len(b.buf) >= size { // 计算Reader原本的缓冲区大小是否比要求设置的缓冲区大小size(size在这里是bufio.defaultBufSize即4096)要大。如果是则保持现有的缓冲区大小,否的话就用size(4096)作为缓冲区大小
return b
}
if size < minReadBufferSize { // 如果size设定的缓冲区大小小于16个字节,则以16代替size
size = minReadBufferSize
}
r := new(Reader) // 创建一个bufio.Reader的实例
r.reset(make([]byte, size), rd) // 将rd这个Reader封装为有size大小的缓冲区的bufio.Reader类型
return r
}
NewReader 和 NewReaderSize做了一件事情,他把传入的文件对象rd这个*os.File的io.Reader用bufio.Reader封装了起来变成一个带缓冲的Reader(变量b),b.buf是一个字节切片,就是bufio.Reader的缓冲区内容。
源码中defaultBufSize = 4096,即4K,也就是说使用bufio读取的时候,会执行一次IO系统调用读取4096byte(4K)大小到bufio缓冲区(即bufio.Reader的buf成员)。而readWithBuffIO中的r.Read(buf)会先从bufio缓冲区读1K大小的内容(在本例中是1K),如果bufio的缓冲区中的内容读完了则会再次进行系统调用4K的内容到bufio缓冲区中。
这样做的好处是减少了系统调用的次数,不用每次Read都进行系统调用。毕竟每次系统调用都会做从用户态到内核态的切换。
我们再看看ioutil的ReadAll
package ioutil
// ReadAll reads from r until an error or EOF and returns the data it read.
// A successful call returns err == nil, not err == EOF. Because ReadAll is
// defined to read from src until EOF, it does not treat an EOF from Read
// as an error to be reported.
func ReadAll(r io.Reader) ([]byte, error) {
return readAll(r, bytes.MinRead)
}
// readAll reads from r until an error or EOF and returns the data it read
// from the internal buffer allocated with a specified capacity.
func readAll(r io.Reader, capacity int64) (b []byte, err error) {
var buf bytes.Buffer
// If the buffer overflows, we will get bytes.ErrTooLarge.
// Return that as an error. Any other panic remains.
defer func() {
e := recover()
if e == nil {
return
}
if panicErr, ok := e.(error); ok && panicErr == bytes.ErrTooLarge {
err = panicErr
} else {
panic(e)
}
}()
if int64(int(capacity)) == capacity {
buf.Grow(int(capacity))
}
_, err = buf.ReadFrom(r)
return buf.Bytes(), err
}
readAll内部使用了bytes.Buffer的缓冲区(即readAll中的buf变量),他和bufio中的缓冲不同的是,bytes.Buffer是一种动态的缓冲区,其缓冲区大小会随着读取的过程慢慢增大(当然,他不会无限增大)。buf.Grow(capacity) 做的就是通过扩容或者平移的方式保证这个缓冲区被多次写入后总是至少有capacity大小的空闲空间能存放调用方要读取的内容(这里的capacity即为bytes.MinRead,即512B)。
ReadFrom则是会循环读取r中的内容(ReadFrom内部每次循环也会调用Grow进行缓冲区扩容)到buf缓冲区(buf是一个字节切片,也是bytes.Buffer缓冲区)直到读完,最后通过调用buf.Bytes将缓冲区的内容一次性返回给调用方。不过,这种动态缓冲区的缺点读取过程中在于扩容或者平移的数据拷贝会损耗效率。
总结的说,ioutil.ReadAll就是把文件内容先拷贝到缓冲区,每次读取的长度会越来越大,拷贝完毕后就一次性的返回给调用方。
如果我们用fi.Read(buf)的时候传入一个4096大小的buf,就能够达到bufio.Read的效果,如果传入一个大于4096的buf,那会比bufio.Read还要快,因为相当于每次系统调用都读取超过4096的内容大小。
除了这些内容之外,go还提供了很多其他功能如
container包:实现了堆/链表/环这3中数据结构,使得我们不必重新实现这些基本数据结构和其算法
encoding/xml包:解析xml或html
logrus包和seelog包:日志系统
archive/zip包:压缩和解压
等等,这些包不再做一一介绍,这些工具包等到真的用到的时候再去查如何使用即可。go的重点还是其高性能的并发编程。
那么到此为止,本博客网站的《Go入门系列》文章已经结束,该系列文章参考go 圣经加上自己的理解添加了一些本人自己写的示例,最终将这个系列的文章给展示出来。
该系列文章只是介绍了Go圣经 中主要和重要的知识点,如果想要查看更多 go圣经 的内容,可以参考原书链接:
https://books.studygolang.com/gopl-zh/