更多优质内容
请关注公众号
请关注公众号

队列的作用是削峰、解耦(服务间互不影响,方便做到降级)和异步。
带来削峰这个优点的同时也带来一个问题:消费者处理能力不足从而导致消息积压;
带来解耦这个优点的同时也带来一个问题:消息丢失导致上游服务和下游服务无法达到最终一致性;
所谓的可靠性是指消息不丢失、不重复以及尽量不积压。
在回答“在使用 MQ 消息队列时,如何确保消息不丢失”这个问题时,我们需要同时回答几个问题:
如何知道有消息丢失?
哪些环节可能丢消息?
如何确保消息不丢失?
a. 如何知道消息丢失
producer 给每个消息附加一个递增的序号,如果consumer接收到的序号不连续则数据丢失。
注意点1:像Kafka和RocketMQ这样的消息队列不保证Topic上的严格顺序,只能保证单个分区上的消息是有序的,因此每个分区上的序号应该相互独立,都从0开始递增(序号不一定是0,1,2,3...,而是像TCP的seq一样按消息长度增长)。每个consumer和分区一一绑定,不能既接收分区1又接收分区2。
注意点2:如果producer是多实例的,消息序号上还要带上producer的标识。
b.哪些环节可能丢消息?
一条消息从生产到消费完成这个过程,可以划分三个阶段:
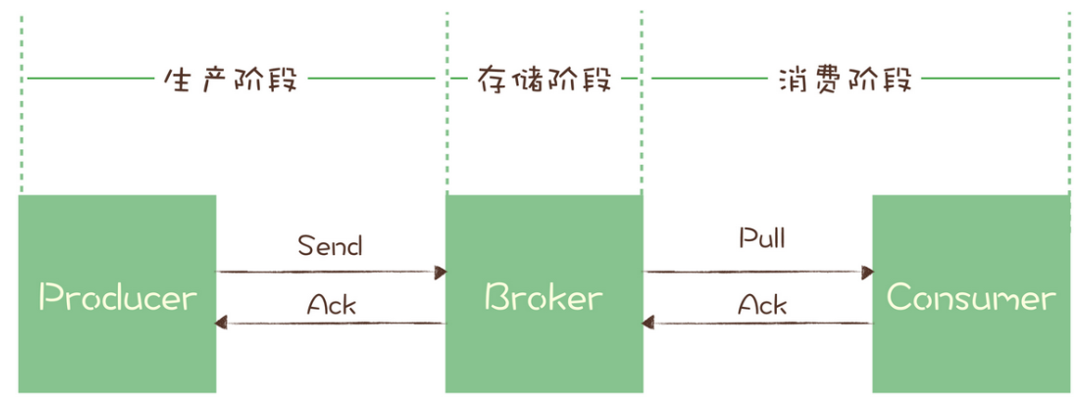
分别为消息生产阶段,消息存储阶段和消息消费阶段。
生产阶段可能引起消息丢失的情况:消息在网络中丢失;
如何解决:
使用请求应答机制(ACK),只有producer接收到broker的ack才认为消息发送成功。否则producer应该超时重试,重试失败则返回异常给用户。
存储阶段可能引起丢失的情况:broker接收到消息后,消息被消费前宕机;
如何解决:
做好持久化,只有消息写入磁盘后才发送ack给producer;
在集群架构下,至少有2个broker保存了消息才发送ack,即使某个broker宕机,其他broker也能代替。
消费阶段可能引起丢失的情况:
消费者拉取消息时,消息在网络中丢失;
消费者拉取消息后,处理消息前宕机;
如何解决:
消费者在处理完消息后才发送ack给broker,不要一接收到消息就发送ack(或者消费者拉取到消息后马上做本地缓存,本地缓存后再返回ack);broker如果没有收到消费者的ack,消费者再次拉取数据时,broker会发送和上一次相同的消息。
c.如何处理消费过程中拉取到的重复消息
在MQTT协议中,给出了三种传递消息时能够提供的服务质量标准:
一般都是一些对消息可靠性要求不太高的监控场景使用,比如每分钟上报一次机房温度数据,可以接受数据少量丢失
一般解决重复消息的办法是,在消费端让消费消息的操作具备幂等性。所谓幂等性是指:对某一个消息操作一次和操作多次所造成的影响相同。
At least once+幂等消费=Exactly once
那么具体如何避免重复消费?
在Kafka中,每个消息会有一个offset作为该消息的序号,消费者每次返回ack时,会将自己下一个要处理的offset捎带上。
Kafka就会发送下一个offset对应的消息。
为了避免消费者处理完消息后,在返回ack前宕机,下次消费者重启时会重复处理broker发出的重复消息。消费者需要做幂等性处理。这里方案有很多,比如生产者在消息里面带一个唯一ID,消费者在处理前先检查该唯一ID是否存在再决定是否处理。处理完后,将该唯一ID写入到mysql或者redis中,该过程是一个原子操作。
d. 如何避免消息积压
消息积压是由于消费者消费速度不及生产者生产速度造成的,只需增加消费者数量即可,但需要注意,增加consumer数量的同时也要增加Topic中的分区数量,确保consumer和partition数量一致,否则多出来的consumer是不会消费消息的。
e. 消息队列中的事务
消息队列中的事务主要解决的是生产者和消费者的数据一致性问题。
实现分布式事务的方法包括 2PC 和 TCC。
2PC(2 Process Commit,二阶段提交),分别有协调者和参与者两个角色,二阶段分别是准备阶段和提交阶段。
准备阶段:协调者向各参与者发送准备命令,这个阶段参与者除了事务的提交啥都做了
提交阶段:协调者看看各个参与者准备阶段是否执行,如果都ok那么就向各个参与者发送提交命令,如果有一个不ok那么就发送回滚命令。
而且 2PC 是一种强一致性的分布式事务,它是同步阻塞的,在参与者接收到提交或回滚命令之前,所有参与者会被阻塞。
2PC效率低,并且存在协调者单点故障问题,并且在极端条件下存在数据不一致的风险,例如某个参与者未收到提交命令,此时宕机了,恢复之后数据是未执行状态,而其他参与者都已经执行和提交事务了。
2PC 只适用于数据库层面的事务,什么意思呢?就是你想在数据库里面写一条数据同时又要在业务服务中上传一张图片,这两个操作 2PC 无法保证两个操作满足事务的约束。
TCC(Try - Confirm - Cancel),也是一种两阶段提交,需要在业务层面上实现Try、Confirm、Cancel 3个方法。
Try操作作为一阶段,负责资源的检查和预留,Confirm操作作为二阶段,执行真正的业务并提交操作,Cancel是预留资源的取消;
TCC也需要一个协调者发出 Try、Confirm 或 Cancel 的指令。