更多优质内容
请关注公众号
请关注公众号

ES官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/index.html
先通过如何用数据库做模糊搜索引出ES的优势。
用数据库如何做搜索
一般会使用%关键词%进行模糊搜索。
select * from products where name like "%牙膏%";
缺点:
1、无法使用索引,会全表扫描;
2、每一行扫描时,需要进行字符串查找,复杂度介于O(n+m)到O(mn)之间。如果母字符串很长,则每一行比对的成本也很大。
3、无法满足用户需求和容错场景。例如,数据表记录的是”生化危机大电影“,用户搜索”生化机“肯定无法搜索成功,而实际上用户希望能搜成功。
总结起来,数据库做搜索性能差且无法满足多数搜索场景和容错性。
全文检索、倒排索引和Lucene
倒排索引是指将数据表某一列或某几列的文本进行分词,建立分词与拥有该分词的行的主键之间的映射关系(一个分词可对应多个行id)。这样的映射关系表就是倒排索引。
全文检索指的是检索一个关键词的过程:
1、对表数据建立倒排索引;
2、对关键词分词;
3、根据关键词的分词(可能有多个)到倒排索引检索得到数据行id;
4、根据id回数据表搜索完整行数据。
优点:
1、倒排索引中的每次检索不是字符串查找,而是精准匹配。
2、由于是精准匹配,可以按一定结构组织倒排索引,检索关键词的分词时不再是全表扫描。
3、由于对要搜索的关键词进行分词后再对每个分词检索,容错性提高。
Lucene是一个封装了建立各种结构倒排索引和全文检索算法的jar包。
什么是Elastisearch
Elastisearch是基于Lucene开发的分布式、高性能、高可用、可伸缩的搜索和分析系统。
如果我们直接基于Lucene在项目中构建一个具有搜索功能的模块,假设建立的倒排索引大小超过单机磁盘容量,就需要在另一个机器上放新的倒排索引数据,变为一个分布式系统,开发者不得不关心更多分布式带来的问题,如一台机器宕机导致该机器的数据不可用,如客户端请求需要广播所有机器,如新索引应该放到哪一台机器上。
但使用ES,我们可以无需考虑这些问题,把全文检索的任务交给ES,开发者只关注业务即可。
ES的优点:
1、自带分布式节点集群,自动维护数据在多个节点的分布和搜索请求路由到多个节点的执行。
2、自动维护数据的冗余副本,实现高可用,一台机器挂掉,数据的完整副本依旧存在。
3、ES封装了更多高级搜索功能,开发者无需重复造轮子。
ES的功能:
1、分布式的搜索和数据分析服务
数据分析例如查最近7天毛巾这个产品的销量排名前10的商家有哪些,每个商品分类下有多少商品等。
2、对海量数据进行近实时的处理
分布式以后,可以采用大量服务器进行检索和数据处理,自然就能做到高效的海量数据处理。
所谓的近实时是指数据搜索和分析是秒级别的,此外数据从写入到下次能读取有一个小延迟(大概需要相隔约1s)。
ES的使用场景:搜索和数据分析的场景。
1、电商商品检索、百度全文检索、站内搜索等。
2、日志数据分析:logstash采集日志,ES进行复杂的数据分析(ELK技术)。
3、GitHub,上亿行代码搜索。
ES本身不是什么新技术,而是将全文检索、数据分析和分布式技术合并在一起形成独一无二的服务。
数据库的优势在于提供事务操作,而ES的优势在于分布式服务、全文检索、数据分析和数据实时处理。
ES核心概念
1、Document:文档是ES中的最小数据单元。它可以是一条客户数据,一条商品数据,一条订单数据,通常用JSON表示,每个index的type中可以存储多个document。一个document中包含多个field(字段)。
如下所示是一个文档:
{ "product_id":1, "product_name":"xxxx", "product_desc":"xxxx", "category_id":10, "category_name":"xxxx", }
2、Index:索引,包含一堆具有相似结构的文档数据,比如一个商品索引用来存放所有商品文档。
3、Type:类型,每个Index可以包含一个或多个type,type是Index的一个逻辑分类,一个type下的document具有相同的field,不同type的field不同。
例如一个博客系统拥有一个索引,这个索引可以分为用户数据的type,文章数据的type以及评论数据的type。
又例如,一个电商系统的客户模块是一个索引,订单是一个索引,商品是一个索引,库存也是一个索引。而订单索引根据不同的商品又可以分为不同的type,每个type的document的field如下所示:
普通商品的type:包含product_id、product_name、product_desc、category_id、category_name这5个字段。
电子商品的type:包含product_id、product_name、product_desc、category_id、category_name、service_period(保修期)这6个字段。
食用商品的type:... ... 略;
4、节点和集群:ES默认初始只有一个名为elasticsearch的集群,该集群里只有一个节点,如果新增节点也会默认加入到名为elasticsearch的集群。
5、Shard:分片,单机无法存储所有数据,ES可以将一个索引的数据分为多份数据,每份数据就是一个shard,这些shard分布到多台服务器存储。shard的好处有2点:便于数据横向扩展;分布到多台服务器,相当于多台服务器并发响应请求(多台机器的cpu一起在运算,多台机器的磁盘并发读写),提高吞吐。
一个ES节点可以包含一个或多个shard分片。
6、Replica:副本,副本是一种副本分片,其本质也是分片。shard其实叫做primary shard,简称为shard,replica其实叫做replica shard,简称为replica。一般而言,每一个shard都需要冗余一份replica。副本的好处有2点:部分节点宕机时高可用;replica所在的节点也可以提供读服务,提高吞吐。
我们来看一个简单的示例:
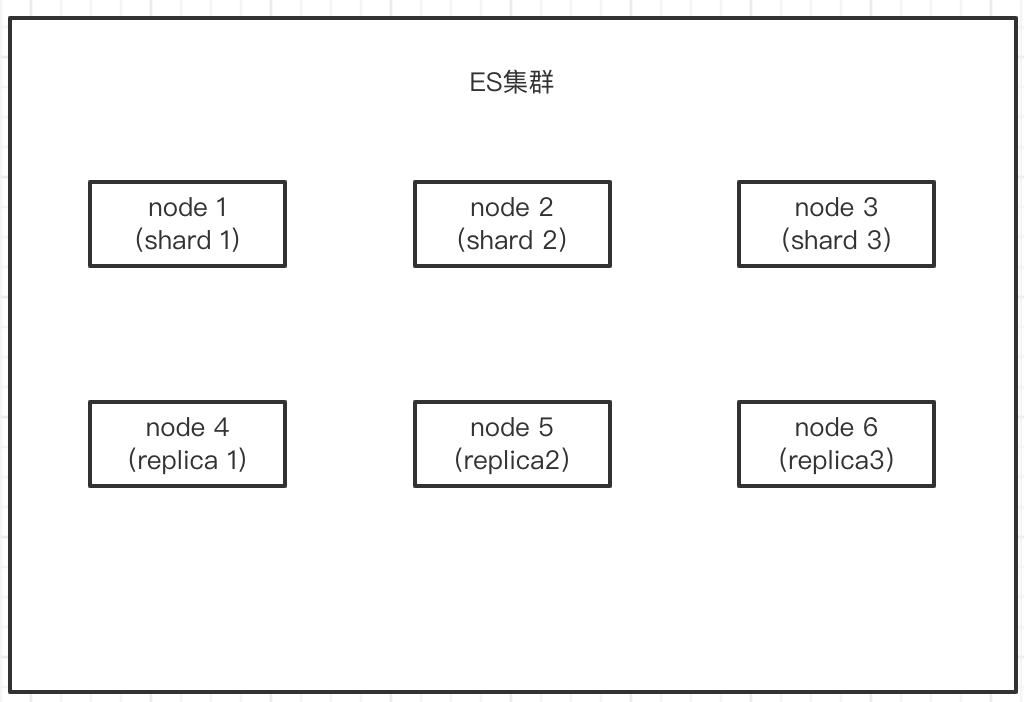
ES默认一个Index初始会分为5个primary shard,每个primary shard都要冗余1份replica shard。因此,创建一个Index就会创建10个shard,而且primary shard 和 replica shard不应该都放在1台机器,最小的高可用配置需要2台服务器,每台服务器都包含一部分primary shard 和一部分replica shard。
一个node是指一个ES进程。
Index相当于数据库的库,type相当于数据库的表,document相当于数据库的行。
最后ES是面向文档的,或者说面向对象的,而关系型数据库则是面向行的,不同对象必须存在数据库的不同表,而ES的一个文档则可以保存多个有关系的对象。
ES服务端的安装和启动
docker安装ES官方文档:https://hub.docker.com/_/elasticsearch
使用docker安装和启动ES:https://www.jianshu.com/p/8abecc27848e
docker ES外网访问:https://blog.csdn.net/pyon_/article/details/122485435
docker ES设置密码:https://www.codenong.com/cs106096987/
es客户端 elasticsearch-head安装和启动:https://blog.csdn.net/weixin_42871989/article/details/123899321
我自己的做法:
# 启动docker ES,这里没有绑定容器卷,之后再绑定
docker run -d -p 9200:9200 --name='es'
-e discovery.type=single-node # ES单节点模式
-e ES_JAVA_OPTS="-Xms128m -Xmx128m" # 限制分配内存128,不设置这个的话,默认会向系统申请4G内存,如果机器没那么大内存则会启动失败
elasticsearch:7.4.2
# 拷贝ES的配置文件目录到本地
docker cp es:/usr/share/elasticsearch/config /tmp/es
# 移除ES容器
docker rm -f es
# 重新启动ES容器,并绑定容器卷
docker run -d -p 9200:9200 --name='es' -e discovery.type=single-node -e ES_JAVA_OPTS="-Xms128m -Xmx128m" -v /tmp/es/config:/usr/share/elasticsearch/config -v /tmp/es/data:/usr/share/elasticsearch/data --privileged=true elasticsearch:7.4.2
# 更改ES配置文件
docker exec -it es /bin/bash
vi config/elasticsearch.yml
# ES配置文件内容如下
cluster.name: docker-cluster
network.host: 0.0.0.0
xpack.security.enabled: true # 这只xpack才能生成和使用密码
xpack.security.transport.ssl.enabled: true
http.cors.enabled: true # 这3条允许跨域,这样elasticsearch head才能访问ES服务
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
# 重启ES容器
docker restart es
# 设置密码(自动生成密码)并记录到文本文件中,该命令会生成多个ES服务的用户和每个用户对应的密码
docker exec -it es /bin/bash
./bin/elasticsearch-setup-passwords auto
注意点:
1、之所以要先以不绑定容器卷的形式启动一次,在手动将容器内config拷贝到本地,然后再重新run一个新ES容器绑定容器卷,是因为不这样做就会报如下错误。
NoSuchFileException: /usr/share/elasticsearch/config/jvm.options
原因很简单,我们本地的config目录是空的,而以bind方式挂载容器卷,会使得宿主机目录覆盖容器目录,因此容器内config目录被清空,因此无法启动ES服务。
2、自动生成密码后,密码配置已经被写入到data目录中,因此密码会永久有效
3、如需修改密码可以做如下操作:
# 创建一个临时超级用户
./bin/elasticsearch-users useradd zbp -r superuser
# 用这个用户去修改elastic用户的密码
curl -XPUT -u zbp:zbp的密码 http://localhost:9200/_xpack/security/user/elastic/_password -H "Content-Type: application/json" -d '{"password": "自定义密码"}'
ES客户端 elasticsearch-head 安装和启动
可参考:https://blog.csdn.net/weixin_42871989/article/details/123899321
需要注意的是,使用 elasticsearch-head 连接一个有密码的ES服务时,需要访问这个链接去连:
http://ES服务的IP地址:9200/?auth_user=ES用户名&auth_password=密码
ES简单命令
ES提供了一套cat api能查看ES中的元数据。
- 查看集群健康状况(v参数表示显示表头)
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1653135582 12:19:42 docker-cluster green 1 1 1 1 0 0 0 0 - 100.0%
分别展示了节点个数,primary shard总数(pri),未分配的shard数量(unassign),活跃状态的分片和总分片占比(active_shards_percent)。
- 查看集群中有哪些索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .security-7 C-62KLzFR0qKqljcVJHkbw 1 0 6 0 19.8kb 19.8kb
分别展示了索引名,该索引的状态(health),索引的主分片个数(pri),索引的副本分片个数(rep),文档个数(docs.count),索引占的大小。
关于集群的健康状态:
green:每个索引的primary shard 和replica shard都是active状态的。
yellow:每个索引的primary shard 都是active状态的,但部分replica shard是不可用状态的。
red:不是所有索引的primary shard都是active状态的,即当前主数据有部分不可访问。
一般我们在开发环境启动一个ES服务会发现其处于黄色状态,原因是我们创建一个index时,ES会为其创建5个primary shard 和 5个 replica shard,而且primary shard 和 replica shard不能同时放在一个node中。因此实际上,我们开发环境可能只启动了一个ES node,因此5个primary shard都在这1个node中处于活跃状态,而其他5个replica shard无法分配到其他node而处于不可用状态。
如果启动ES集群时指明以单节点模式启动,那么ES就不会创建和分配replica shard,集群状态也会是绿色的。
- 查看索引的文档个数
GET /_cat/count/index_name?v
- 简单索引操作
# 创建索引
PUT /zbp_index?pretty
# 删除索引(慎用,相当于删除数据库)
DELETE /zbp_index?pretty
- 文档CURD操作之新增一个文档
PUT /索引名/type名/文档id
PUT /zbp_index/product/1
{ # 插入的文档数据
"name":"gaolujie yagao",
"desc":"youxiao fangzhu",
"price":25,
"producer":"zhonghua producer",
"tags":["fangzhu"]
}
# 返回结果
{
"_index": "zbp_index", # 插入文档所在的index
"_type": "product", # 插入文档所在的type
"_id": "1", # 文档id
"_version": 1, # 版本号,与乐观锁的并发控制有关
"result": "created",
"_shards": { # 该文档涉及的分片信息
"total": 2, # 一个文档只能分别保存在一个primary shard和一个replica shard中,因此涉及的分配数量为2
"successful": 1, # 成功写入到1个分片中,因为此时只有1个node,replica shard根本没分配
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
插入文档时,ES会自动创建index和type,无需提前创建,而且ES默认会对document中每个field都建立倒排索引,使其可以被搜索。
- 文档CURD操作之查询一个文档
GET /索引名/type名/文档id
GET /zbp_index/product/1
# 返回结果
{
"_index": "zbp_index",
"_type": "product",
"_id": "1",
"_version": 2,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": { # _source是查询出来的原文档内容
"name": "gaolujie yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "zhonghua producer",
"tags": [
"fangzhu"
]
}
}
- 文档CURD操作之修改一个文档
# 以覆盖的方式修改一个文档,用PUT和POST都可以
PUT /zbp_index/product/1
{ # 我要修改name字段,但是其他字段也要带上,这是覆盖方式的一个坏处
"name":"better gaolujie yagao",
"desc":"youxiao fangzhu",
"price":25,
"producer":"zhonghua producer",
"tags":["fangzhu"]
}
# 返回结果
{
"_index": "zbp_index",
"_type": "product",
"_id": "1",
"_version": 2, # 版本号发生更新
"result": "updated", # 操作结果是"更新"而非"新增"
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
# 使用_update这个api以部分更新的方式修改一个文档,只能使用POST请求
POST /zbp_index/product/1/_update
{
"doc":{
"name":"gaolujie yagao!", # 要更改的字段
"price": 30,
"more_info":"no more" # 新增一个之前不存在的字段也行
}
}
# 返回结果
{
"_index": "zbp_index",
"_type": "product",
"_id": "1",
"_version": 11,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 10,
"_primary_term": 1
}
覆盖一个id=1的文档时,其实并非对id=1的文档的每个字段都进行修改。而是将原文档标记为deleted,并创建一个新的id=1的文档。
当ES的数据逐渐变多时,会自动删除标记为deleted的文档。
如果用户希望明确一个 PUT|POST /索引/类型/id号 是一个创建文档操作而非覆盖操作(也就是说你不知道当前这个文档是否存在),则可以使用_create API。如果文档已存在,则该操作会报错。
PUT|POST /zbp_index/product/6/_create
- 文档CURD操作之删除一个文档
DELETE /索引名/type名/文档id
删除操作也是将文档标记为deleted,而非真的删除文档。
如果需要根据条件删除可以使用_delete_by_query API。
# /索引名/_delete_by_query
/outbound_invoice/_delete_by_query
{
"query": {
"bool": {
"filter": [
{
"term": {
"client_id": 14119 # 删除client_id为14119的文档
}
}
]
}
}
}
- 文档查询方式之query string search
GET /索引名/type名/_search
# 直接查询该index/type的所有文档(不加任何参数即可)
GET /zbp_index/product/_search
# 查询name字段包含yagao的文档,并按price字段降序排序
GET /zbp_index/product/_search?q=name:yagao&sort=price:desc
# 返回结果
{
"took": 294, # 耗费多少毫秒
"timed_out": false, # 是否超时
"_shards": {
"total": 1, # 请求发向了多少个分片,对于搜索请求,会发送到所有的primary shard(如果有某个primary shard down掉,则发送到顶替的replica shard上)
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": { # 查询结果数量(document的数量)
"value": 1,
"relation": "eq"
},
"max_score": null, # 最高匹配相关度,最高是1
"hits": [{ # 包含匹配的document的详细数据
"_index": "zbp_index",
"_type": "product",
"_id": "1",
"_score": null, 本文档的匹配相关度,越匹配,分数越高。如果要求按某字段排序,则分数为null
"_source": {
"name": "better gaolujie yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "zhonghua producer",
"tags": [
"fangzhu"
]
},
"sort": [ # 本文档的排序值
25
]
}]
}
}
query string search方式适用于临时的、在命令行中查询的简单场景,如果查询请求复杂是很难构建的,因此在生产环境中很少用query string search查询。
顺便再介绍一下query的+ 和 - 语法。
GET /zbp_index/product/_search?q=+name:yagao // 查询name字段包含yagao的文档
GET /zbp_index/product/_search?q=-name:yagao // 查询name字段不包含yagao的文档
_all metadata
GET /index/type/_search?q=test
搜索所有的field,任一个field包含指定关键字的文档都能搜索出来。
实际上,在创建文档时,ES会默认将所有字段作为字符串拼接起来作为一个 _all 字段,并对其建立倒排索引。如果遇到上面这样的不指定field的关键词搜索,就会可以用到_all字段的倒排索引进行检索。
- 文档查询方式之query DSL
DSL方式可以在请求的body体中构建json格式的搜索信息,相比于query search方式可以支持更复杂的搜索需求。
例1:查询所有文档
GET|POST /zbp_index/product/_search
# 请求body
{
"query":{ # 表示这是一个DSL查询
"match_all":{} # 查询所有文档
}
}
例2:查询name字段包含yagao的所有文档,并按价格降序排序
GET|POST /zbp_index/product/_search
# 请求body
{
"query":{ # 表示这是一个DSL查询
"match":{
"name": "yagao"
}
},
"sort":{
"price":"desc"
}
}
例子3:查询所有文档并分页
GET|POST /zbp_index/product/_search
# 请求body
{
"query":{ # 表示这是一个DSL查询
"match_all":{} # 查询所有文档
},
"from":1, # 偏移量
"size":2 # 每页大小
}
例子4:查询所有文档,只显示name和price字段
GET|POST /zbp_index/product/_search
# 请求body
{
"query":{
"match_all":{}
},
"_source":["name","price"]
}
- 文档查询方式之query filter
查询商品名中包含yagao,且售价大于25元的商品
GET|POST /zbp_index/product/_search
{
"query": {
"bool": { # 可以组合多个条件
"must": {
"match": {
"name": "yagao"
}
},
"filter": {
"range": {
"price": {"gt": 20}
}
}
}
}
}
如果需要多个条件组合可以使用must
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "wali"
}
},
{
"term": {
"country": "chinas"
}
}
]
}
},
"from": 0,
"size": 10
}
term是精确查询,上面的语句相当于where name="wali" and country="chinas"。
- 文档查询方式之全文检索 full-text search
查询包含 yagao producer 关键字相关的文档。
GET|POST /zbp_index/product/_search
{
"query":{
"match":{
"producer":"yagao producer"
}
}
}
全文检索的语法和前面的例2没有任何区别。唯一区别在于例2的搜索值只有1个单词,而本例有2个单词。此时ES就会将用户提供的检索值进行分词,并对每个分词从倒排索引进行检索。只要有任何1个单词能从倒排索引中找到,都会出现在返回结果中,某一个文档涵盖的搜索值分词越多,该搜索值在倒排索引命中该文档的次数越多,该文档的分数也越高。
- 文档查询方式之全文检索 phrase search(短语搜索)
GET|POST /zbp_index/product/_search
{
"query":{
"match_phrase":{
"producer":"yagao producer"
}
}
}
短语搜索要求某个字段必须完全包含检索值才能匹配成功,这和全文搜索相反。
- 文档查询方式之全文检索 highlight search(高亮搜索)
GET|POST /zbp_index/product/_search
{
"query":{
"match":{
"producer":"yagao"
}
},
"highlight":{
"fields":{
"producer" : {} # 只对producer中命中的关键字进行高亮显示
}
}
}
高亮搜索和普通的DSL搜索什么区别,但是会在返回结果中多返回一个hightlights属性,里面包含了producer字段中的“yagao”字样会被添加一个高亮的html标签。
再看一个高亮显示的例子:
GET|POST /zbp_index/product/_search
{
"query":{
"bool":{
"must":[
{
"match_phrase":{
"producer": "yagao producer"
}
},
{
"match_phrase":{
"name": "yagao"
}
}
]
}
},
"_source":["name","producer"],
"highlight":{
"fields":{
"producer":{},
"name":{}
}
}
}
# 查询结果
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0078249,
"hits": [
{
"_index": "zbp_index",
"_type": "product",
"_id": "2",
"_score": 1.0078249,
"_source": {
"name": "special yagao",
"producer": "special yagao producer"
},
"highlight": {
"name": [
"special <em>yagao</em>"
],
"producer": [
"special <em>yagao</em> <em>producer</em>"
]
}
}
]
}
}
注意:
上述6中查询方式可以组合使用,不是独立的。
对于ES 7以上的版本,DSL等带body的请求方式只能用post请求,而不能用get请求,否则会忽略body的内容直接返回所有文档。
聚合分析实例(聚合可用于数据分析)
开始之前先插入如下数据:
PUT /zbp_index/product/1
{
"name": "better gaolujie yagao",
"desc": "youxiao fangzhu",
"price": 20,
"producer": "gaolujie producer",
"tags": [
"fangzhu",
"meibai"
]
}
PUT /zbp_index/product/2
{
"name": "zhonghua yagao",
"desc": "guochan product",
"price": 25,
"producer": "zhonghua producer",
"tags": [
"xiahuo"
]
}
PUT /zbp_index/product/3
{
"name": "heiren yagao",
"desc": "dajia douyong",
"price": 35,
"producer": "heiren producer",
"tags": [
"meibai",
"qingxin"
]
}
PUT /zbp_index/product/4
{
"name": "yunnan baiyao yagao",
"desc": "yunnan baiyao",
"price": 50,
"producer": "yunnan baiyao producer",
"tags": [
"xiahuo",
"meibai",
"changqi youxiao"
]
}
PUT /zbp_index/product/5
{
"name": "special yagao",
"desc": "zhizao xuannian",
"price": 55,
"producer": "special yagao producer",
"tags": [
"special",
"xiahuo",
"meibai",
"fangzhu"
]
}
我们要根据tags字段进行聚合,此时需要将该字段的fielddata属性置为true。
PUT /zbp_index/_mapping/product?include_type_name=true # 更改product这个type的字段属性,可以理解为和mysql中更改字段信息是一样的
{
"properties":{
"tags":{
"type":"text",
"fielddata":true
}
}
}
需求1:对商品按tags(中的每个元素)分组
POST /zbp_index/product/_search
{
"size":0, // 如果加上size=0,表示不显示查找出来的文档的结果,只显示aggs聚合的结果
"aggs":{
"group_by_tags":{ // 自定义的聚合任务名
"terms":{ // 以terms方式聚合,可以简单理解为“分组”
"field":"tags"
}
}
}
}
# 结果
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ // buckets的一个元素表示一类分组
{
"key": "meibai",
"doc_count": 4 // tags为美白的文档有4条
},
{
"key": "xiahuo",
"doc_count": 3
},
{
"key": "fangzhu",
"doc_count": 2
},
{
"key": "changqi",
"doc_count": 1
},
{
"key": "qingxin",
"doc_count": 1
},
{
"key": "special",
"doc_count": 1
},
{
"key": "youxiao",
"doc_count": 1
}
]
}
}
}
需求2:对名称中包含yagao的商品,对每个tag的商品分组。很简单,只需加上query属性表示筛选条件即可。
POST /zbp_index/product/_search
{
"size":0,
"query":{
"match":{
"name":"yagao"
}
},
"aggs":{
"group_by_tags":{
"terms":{
"field":"tags"
}
}
}
}
需求3:对每个tag的商品分组,计算每个tag的商品平均价格。
{
"size":0,
"aggs":{
"group_by_tags":{ // 自定义的聚合任务名
"terms":{ // 以terms方式聚合,可以简单理解为“分组”
"field":"tags"
},
"aggs":{ // 在group_by_tags聚合下计算平均价格
"avg_price":{ // 聚合任务名
"avg":{ // 聚合方式:计算平均值
"field":"price"
}
}
}
}
}
}
# 结果
{
"took": 21,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "meibai",
"doc_count": 4,
"avg_price": {
"value": 40.0
}
},
{
"key": "xiahuo",
"doc_count": 3,
"avg_price": {
"value": 43.333333333333336
}
},
{
"key": "fangzhu",
"doc_count": 2,
"avg_price": {
"value": 37.5
}
},
{
"key": "changqi",
"doc_count": 1,
"avg_price": {
"value": 50.0
}
},
{
"key": "qingxin",
"doc_count": 1,
"avg_price": {
"value": 35.0
}
},
{
"key": "special",
"doc_count": 1,
"avg_price": {
"value": 55.0
}
},
{
"key": "youxiao",
"doc_count": 1,
"avg_price": {
"value": 50.0
}
}
]
}
}
}
需求4:在需求3的基础上,按平均价格降序排序
{
"size":0,
"aggs":{
"group_by_tags":{
"terms":{
"field":"tags",
"order":{"avg_price":"desc"}
},
"aggs":{
"avg_price":{
"avg":{
"field":"price"
}
}
}
}
}
}
需求5:先按价格范围区间分组,再在每组内按照tag分组,计算价格分组每组平均价格和tag分组的魅族平均价格。
{
"size":0,
"aggs":{
"group_by_price":{
"range":{
"field":"price",
"ranges":[
{
"from":20,
"to":25
},
{
"from":25,
"to":40
},
{
"from":40,
"to":60
}
]
},
"aggs":{ // 在上一维度聚合的基础上再对另一个维度(或者说字段)聚合,这种嵌套聚合分组称为“下钻分析”
"group_by_tags":{
"terms":{"field":"tags"},
"aggs":{
"avg_price":{
"avg":{
"field":"price"
}
}
}
},
"avg_price":{
"avg":{
"field":"price"
}
}
}
}
}
}
# 结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"group_by_price": {
"buckets": [
{
"key": "20.0-25.0",
"from": 20.0,
"to": 25.0,
"doc_count": 1,
"avg_price": {
"value": 20.0
},
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 1,
"avg_price": {
"value": 20.0
}
},
{
"key": "meibai",
"doc_count": 1,
"avg_price": {
"value": 20.0
}
}
]
}
},
{
"key": "25.0-40.0",
"from": 25.0,
"to": 40.0,
"doc_count": 2,
"avg_price": {
"value": 30.0
},
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "meibai",
"doc_count": 1,
"avg_price": {
"value": 35.0
}
},
{
"key": "qingxin",
"doc_count": 1,
"avg_price": {
"value": 35.0
}
},
{
"key": "xiahuo",
"doc_count": 1,
"avg_price": {
"value": 25.0
}
}
]
}
},
{
"key": "40.0-60.0",
"from": 40.0,
"to": 60.0,
"doc_count": 2,
"avg_price": {
"value": 52.5
},
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "meibai",
"doc_count": 2,
"avg_price": {
"value": 52.5
}
},
{
"key": "xiahuo",
"doc_count": 2,
"avg_price": {
"value": 52.5
}
},
{
"key": "changqi",
"doc_count": 1,
"avg_price": {
"value": 50.0
}
},
{
"key": "fangzhu",
"doc_count": 1,
"avg_price": {
"value": 55.0
}
},
{
"key": "special",
"doc_count": 1,
"avg_price": {
"value": 55.0
}
},
{
"key": "youxiao",
"doc_count": 1,
"avg_price": {
"value": 50.0
}
}
]
}
}
]
}
}
}