更多优质内容
请关注公众号
请关注公众号

· 分段存储管理
通常用户程序由若干个逻辑模块(功能模块、数据模块等)组成(例如一个C程序中有一个主函数main,它调用子函数f1~f3,又调用标准函数库的printf和scanf,每一个函数都是一个独立的逻辑结构,都应该有自己独立的内存空间,每个内存空间的地址从0开始)。
分段存储是指将进程按独立的逻辑结构划分为若干个段,每个段都被分配连续的内存空间,段与段之间离散存储。
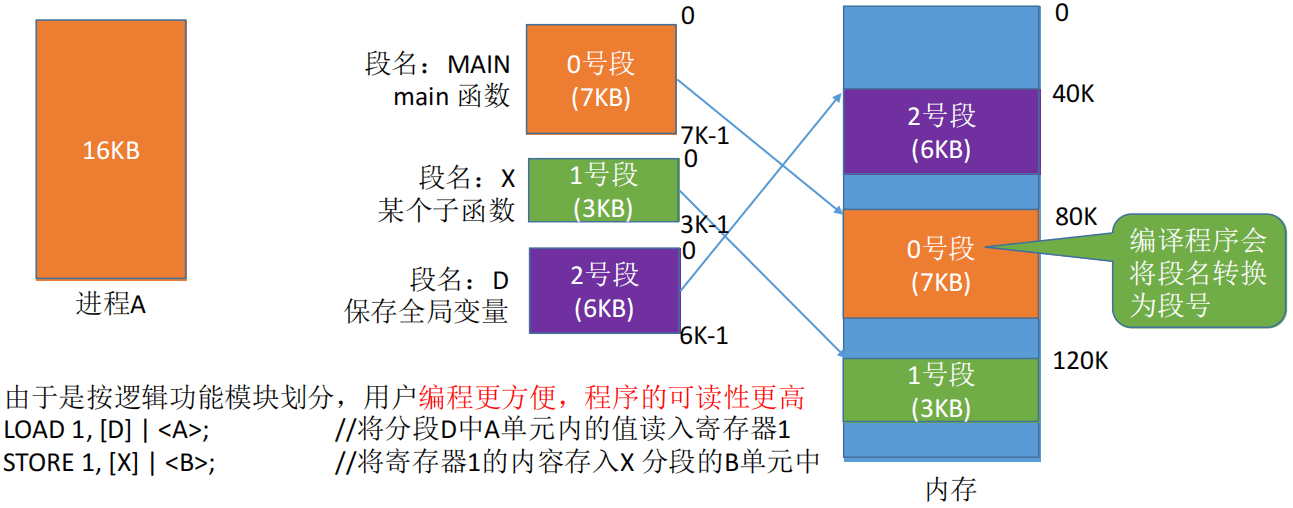
用户程序进行编译时,编译程序会为该程序的各个逻辑结构构建段,例如在编译程序中会为下面内容建立单独的段:
1.全局变量(即介绍进程时说的数据段)
2.过程调用栈,用来放参数和返回地址
3.每个过程或函数的代码部分(即介绍进程时说的程序段或代码段)
4.每个过程和函数的局部变量(即介绍进程时说的数据段)
一个进程的程序段和数据段不止一个,而是程序中有多少个独立的逻辑模块就会产生多少个段。例如进程A包含 main()、f()和g()这3个函数,其中 main()调用了f()和g(),此时进程A会产生3个程序段存放 main()/f()/g() 对应的机器指令,产生3个数据段存放 main()/f()/g() 生成的临时数据。而且这些段相互独立,相互离散。
如果main()先调用 f() 后调用 g() ,那么f() 和 g()的数据段可能不会同时出现在内存中,而是f()的数据段先被回收再创建g()的数据段,但 main()的数据段和f()的数据段肯定是同时在内存中的。
注意:
段内地址是连续的,段与段之间是离散的。
分段存储中,每个段都有一个段名和段号。
和分页存储不同的是,每个页的长度是相同的,由操作系统决定;而每个段的长度是不同的,由开发者编程实现的模块的复杂度和工作量决定。
分段系统的逻辑地址结构由段号(段名)和段内地址(段内偏移量)所组成。段号的位数决定了每个进程最多可以分几个段,段内地址位数决定了每个段的最大长度是多少。
分段的用户进程地址空间是二维的,程序员在标识一个地址时,既要给出段名,也要给出段内地址。

· 段表
和页表类似,为了方便系统找到进程的某个段在物理内存中的起始地址,系统为分段存储管理下的每个进程建立了一个段表。如下所示:
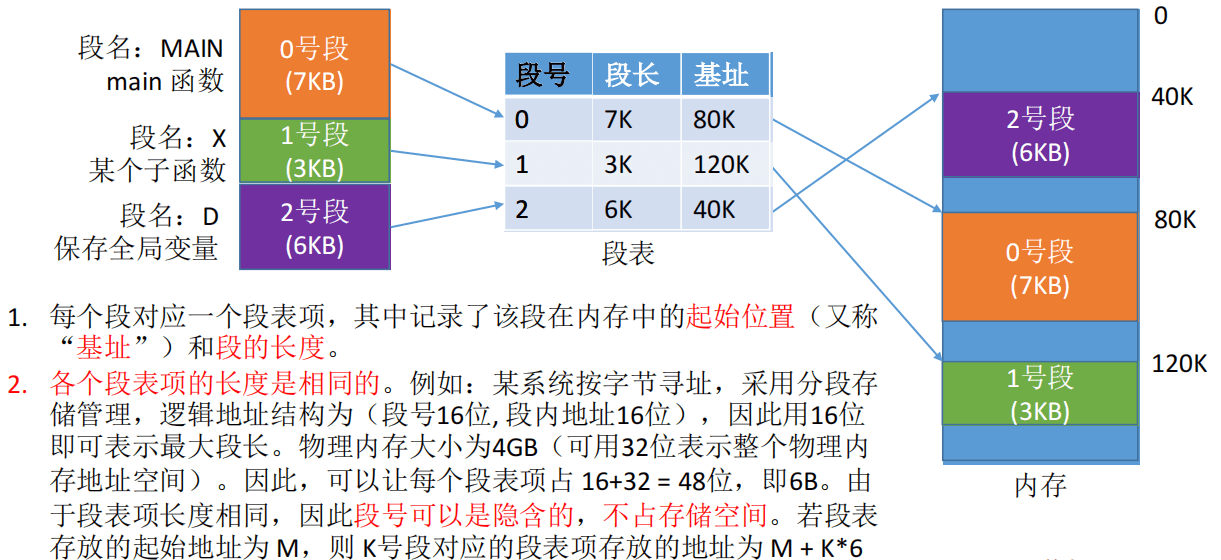
1、每个段对应一个段表项,其中记录了该段在内存中的起始位置(又称 “基址”)和段的长度(要记录长度是因为每个段的长度不同,而页的长度都相同)。
2、各个段表项的长度是相同的。段表项长度取决于段长的位数和段基址的位数(即操作系统位数)。
例如:某系统按字节寻址,采用分段存 储管理,逻辑地址结构为(段号16位, 段内地址16位),因此用16位 即可表示最大段长。物理内存大小为4GB(可用32位表示整个物理内 存地址空间)。因此,可以让每个段表项占 16+32 = 48位,即6B。
由 于段表项长度相同,因此段号可以是隐含的,不占存储空间。若段表 存放的起始地址为 M,则 K号段对应的段表项存放的地址为 M + K*6
· 分段存储的地址变换
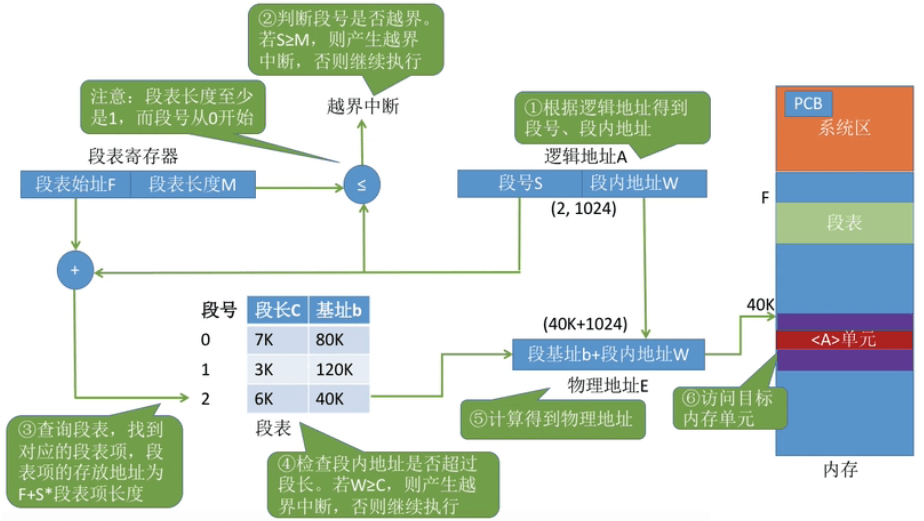
①根据逻辑地址得到 段号、段内地址。
②判断段号是否越界。 若S≥M,说明CPU正访问一个不存在于该进程的段,产生越界 中断,否则继续执行。
③根据段表基址和段号查询段表,找到 对应的段表项,段 表项的存放地址为 F+S*段表项长度。得到段基址b
④检查段内地址是否超过 段长。若W≥C,说明CPU正访问一个该段不存在的地址,产生越 界中断,否则继续执行。
⑤根据段基址b和段内偏移W计算得到物理地址。
⑥访问目标 内存单元。
分段系统中也可以引入快表机构,将近期访问过的段表项放到快表中,这样可以 少一次访问,加快地址变换速度。
· 分段和分页管理对比
1、从页和段的含义
页是进程存储的物理单位。分页的主要目的是为了实现进程在内存的离散分配,提高内存利用率。分页仅仅是系统管 理上的需要,完全是系统行为,对用户是不可见的。
段是进程存储的逻辑单位。分段的主要目的是更好地满足用户需求。一个段通常包含着一个逻 辑模块的信息。分段对用户是可见的,用户编程时需要显式地给出段名。
2、从页和段的长度
页的大小固定且由系统决定。段的长度却不固定,决定于用户编写的程序。
3、分段比分页更容易实现程序的共享和保护。
因为我们共享程序具体是共享一个独立的逻辑模块,而分段存储管理是对独立的逻辑模块分配连续内存空间,系统只需将需要共享的这段代码在内存的(基址,长度)添加到要使用这段代码的进程的段表中即可。
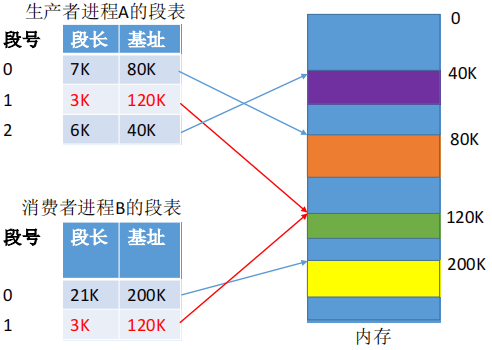
而如果在分页存储管理中共享,一个逻辑模块的内容可能分在在不同的页面中(假如该逻辑模块横跨11个页),就需要将这些页面的页号块号映射都添加到共享进程们的页表中。而且一个页可能既有共享模块的内容也有非共享模块的内容,如果让共享进程们的页表指向这个页,就可能访问到不可共享的代码和数据。
简单来说:在分页系统中实现页的共享较为困难,因为分页是对连续的进程逻辑空间的等分,被共享的程序不一定刚好分在一个或多个完整的页面。此时就会出现一个页面既有共享程序又有不能共享的该进程自己的私有数据,因此页式存储不利于共享。
PS:关于共享程序
不能被修改的代码称为纯代码或可重入代码,这样的代码是可以安全的被并行执行的,只有这样的代码可以被多进程或多线程共享,而可修改的代码是不能共享的。
以函数为例,如果一个函数是可重入的,则该函数:
不能含有全局变量(只能包含调用者提供的参数,和函数自己产生的局部变量);
不能调用其他不可重入的函数;
如下所示:
int g_var = 1;
int f()
{
g_var = g_var + 2;
return g_var;
}
int g()
{
return f() + 2;
}
f() 和 g() 都是不可重入函数,因为他们包含了一个全局变量 g_var,如果多进程共享f()和g()会导致g_var变量因为多进程并发的异步性而被改乱。
int f(int i)
{
return i + 2;
}
int g(int i)
{
return f(i) + 2;
}这两个函数才是可重入函数。多进程只能共享f() 和 g() 的代码段,但是不会共享f()和g()的数据段。f() 和 g()运行过程中产生的数据分别保存在各自进程自己在运行f()/g()时创建的数据段中。例如 进程A和进程B共享 f() ,进程A运行f()时系统会为其创建一个数据段A1用来保存f()产生的临时变量i,而且数据段A1和进程A运行自身其他逻辑模块产生的数据段是相互独立的,离散的。
优缺点:

·段页式管理
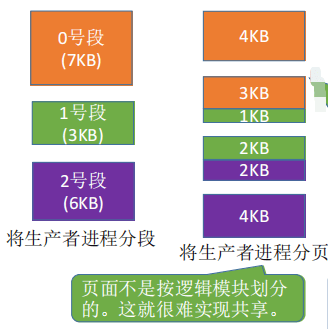
段页式管理将进程按逻辑模块分段,再将各段分页(如每个页面4KB) ,再将内存空间分为大小相同的内存块 ,把进程各页面分别装入各内存块中。
段页式存储同时继承了分页管理和分段管理的优点,分段方便用户进程按以逻辑模块为单位规划和运行,段内分页使一个段可以离散存储,提高了内存利用率,避免外部碎片。
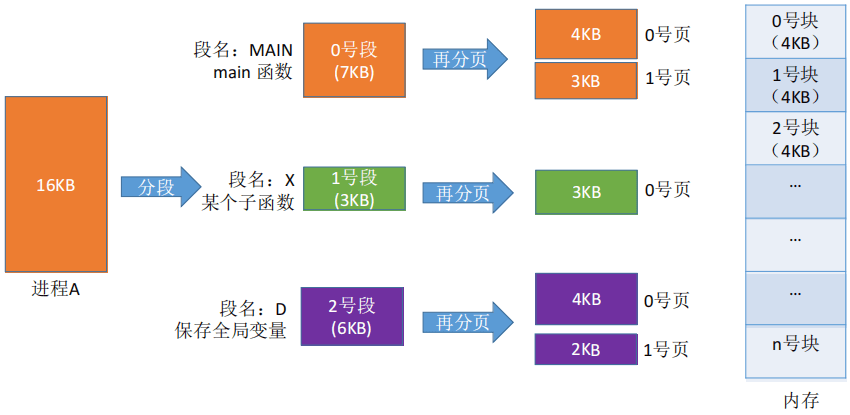
段页式系统的逻辑地址结构由段号、页号、页内地址(页内偏移量)组成。

段号的位数决定了每个进程(或者说整个系统内存)最多可以分几个段;
页号位数决定了每个段最大有多少页;
页内偏移量决定了页面大小、内存块大小是多少;
段号、页号和段内偏移的位数由系统决定。
“分段”对用户是可见的,程序员知道程序中有多少个段,因为它亲手实现了这些逻辑模块。而将各段“分页”对用户是不可见的。系统 会根据段内地址自动划分页号 和页内偏移量。
段页式管理的地址结构是二维的。
段页式管理中,一个进程对应一个段表和多个页表,一个段对应一个页表。
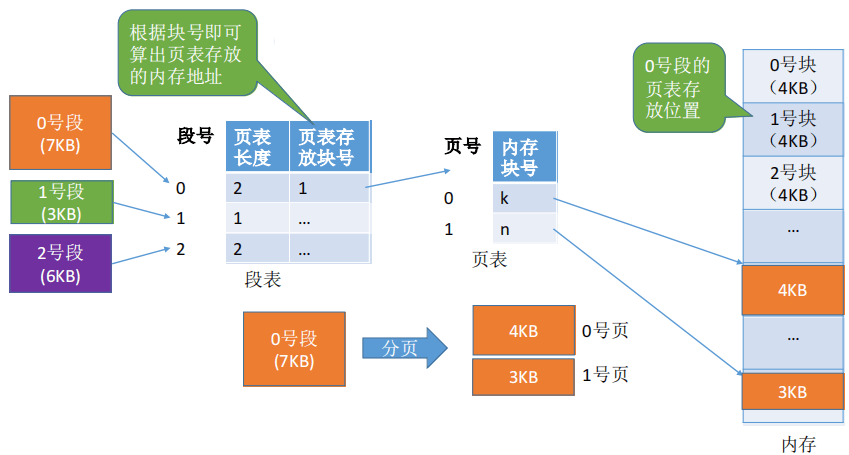
每个段对应一个段表项,每个段表项由段号、该段对应的页表有多少个页表项、该页表存放的块号(页表起始 地址)组成。每个段表项长度相等,段号是隐含的。
每个页面对应一个页表项,每个页表项由页号、程序页面对应的内存块号组成。每个页 表项长度相等,页号是隐含的。
注意:
如果段页式管理采用单级页表,则一个页表会被分配一个连续的存储空间存它所有的页表项。此时段表的“页表存放块号”字段是该页表的起始块号。如果采用多级页表,则顶级页表的存储只占1个页,段表的“页表存放块号”字段是该顶级页表的所存放的块号。
段页式存储地址变换的过程
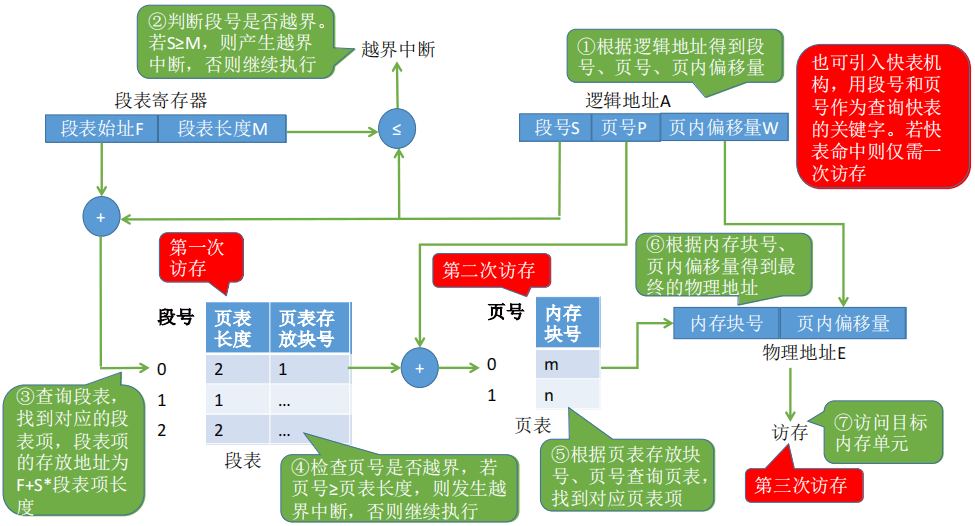
使用快表的话,会以段号+页号作为key,该段该页对应的块号作为value。
如果不使用快表,则段页式存储管理的一次根据逻辑地址访问目标值会发生3次内存IO。
PS:无论是段式、页式还是段页式存储的地址变换,他们都发生在进程运行时,即CPU执行指令或按PC的值读取指令时发生的