更多优质内容
请关注公众号
请关注公众号

前文阅读:Python多线程和多进程(五) 多线程管理——线程池
前面我们说了python多线程和线程池的优势和使用方法,并通过爬虫实例做演示。那么本篇文章再说说线程池可能会有什么样的坑和问题。
一、无限制往线程池放任务导致内存溢出
考虑一个场景,有一个线程池的主线程从远程队列不断接收任务,然后再把任务丢到线程池处理。我们写出来的代码可能是这样的:
# coding=utf-8
from concurrent.futures import ThreadPoolExecutor, as_completed
import jieba,sys,psutil,os,time,gc
class Test:
def __init__(self, file):
with open(file, 'rt', encoding='utf-8') as f:
self.cont = f.read()
def run(self):
res = list(jieba.cut(self.cont))
return res
maxConcurrent = 20
pool = ThreadPoolExecutor(max_workers=maxConcurrent)
tasks = []
for i in range(100000): #for循环模拟从队列中获取任务
tester = Test('../1.txt')
tasks.append(pool.submit(tester.run))
print("appending:" + str(pros.memory_info().rss)) # 打印当前进程占用的内存大小
for task in as_completed(tasks):
print(pros.memory_info().rss)
在上述代码中,我们要完成10万个任务,任务的具体内容是给文本文件中的文章进行分词。
虽然我们在代码中指定了并发执行的任务数只有20个,但是这不意味这线程池中只能容纳20个任务,python线程池中包含一个无界限的排队队列,所以在前面20个线程池执行的过程中,后面的任务会源源不断的往线程池里面塞,瞬间就会生成10万个tester对象,导致内存溢出。
通过 psutil 库打印进程内存使用情况得知,随着循环次数越多,进程占用的内存也越多,并且没有释放。
如何解决:限制往线程池放任务的数量。
既然能并发处理的任务数只有20个,为什么一定要一瞬间往线程池里放10万个呢?我可以先往里面放100个,等着100个任务执行完之后,我再从远程队列接收100个任务往线程池里放不就行了么。实现代码如下:
# coding=utf-8
# 检验线程池内存释放情况
from concurrent.futures import ThreadPoolExecutor, as_completed
import jieba,sys,psutil,os,time,gc
class Test:
def __init__(self, file):
with open(file, 'rt', encoding='utf-8') as f:
self.cont = f.read()
def run(self):
res = list(jieba.cut(self.cont))
return res
maxConcurrent = 20
pool = ThreadPoolExecutor(max_workers=maxConcurrent)
pros = psutil.Process(os.getpid())
print("start: " + str(pros.memory_info().rss))
for i in range(2500): # 将10万个任务分成2500批,每批40个
print("before empty tasks list:" + str(pros.memory_info().rss))
tasks = []
print("after empty tasks list:" + str(pros.memory_info().rss)) # 执行到这里的时候,上一批线程池里的任务所占的内存会被释放
for i in range(maxConcurrent*2): # 同时塞到pool中的任务最多只有 40 个,同时在执行的任务最多只有20个
tester = Test('../1.txt')
tasks.append(pool.submit(tester.run))
print("appending:" + str(pros.memory_info().rss))
print("running:"+str(pros.memory_info().rss))
if len(tasks) > 0:
for task in as_completed(tasks):
print(pros.memory_info().rss)
print("task finish!")
for i in range(5):
time.sleep(1)
print(pros.memory_info().rss)
pool.shutdown() # 保险起见,最后要关闭线程池
pool = None
tasks = None
gc.collect() # 马上释放内存
print(pros.memory_info().rss)
上述代码每次往线程池放40个任务,等40个任务执行完之后才开始下一批任务。通过 psutil 库打印进程内存使用情况得知,当执行到下一次循环的 tasks = [] 时,上一批线程池内任务所占的内存会被释放。
当所有任务结束后,代码中开始每隔1秒打印一次内存使用情况,发现所有任务结束后,占用的内存大小没有减少。因此我们得到结论:线程池中的线程执行完任务后并没有马上被释放内存和线程中的变量等资源。因此我们执行 shutdown方法 和 gc.collect() 马上释放内存,这么一来多线程占用的资源和内存才被彻底释放掉。
二、多个独立任务共享线程池导致饥饿(次要任务拖垮主要任务)
假设有这么一个场景,有一个并发量为20的 线程池P 负责处理 业务A 和 业务B 的任务(业务A会产生很多任务A,业务B会产生很多任务B)。而且业务A和业务B是独立的,不存在依赖或者先后关系。1个任务A要执行很久(假设要3分钟),1个任务B则很快就可以执行完了(假设要3秒)。当持续的有任务A和任务B塞入到线程池P中执行,会发生什么事情?
答案是:由于任务A要执行很久才执行完,因此线程池P中大部分时间都被任务A占满了使用权,而任务B要等前面的任务A执行完了之后才能开始执行,这就相当于绝大部分 线程池P 这个资源被任务A给占用了,任务B产生了饥饿,明明任务B几十秒可以执行完一批,但是因为任务A也在线程池中,导致任务B要等几十分钟。
如果任务A和任务B中,任务B是重要业务逻辑,而业务A是边缘的业务逻辑,那么次要任务就会拖垮主要任务。
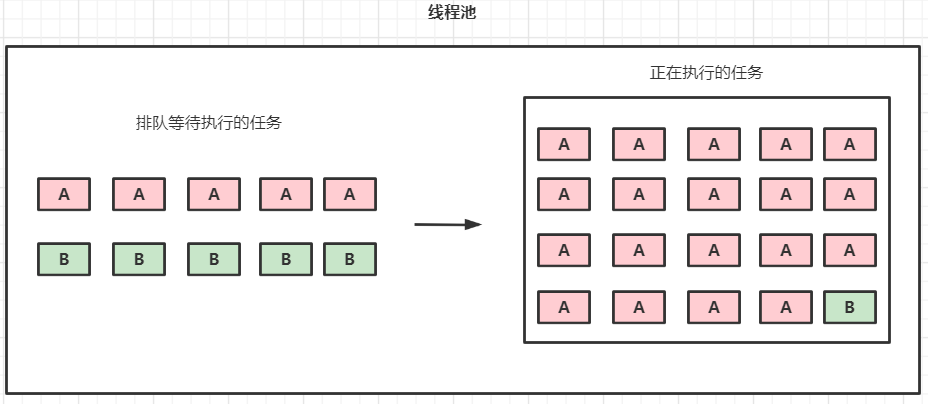
不仅是执行时长会导致这种情况,还有其他占用的资源竞争(例如内存,比如任务A占用的内存很多)也会导致这种任务倾斜的情况。
如何解决:线程池隔离。
我们可以将互相独立的任务放到不同的线程池执行,既增加了并发度,也可以避免因为在同一个线程池竞争资源而导致的任务倾斜和次要任务拖垮主要任务的情况。
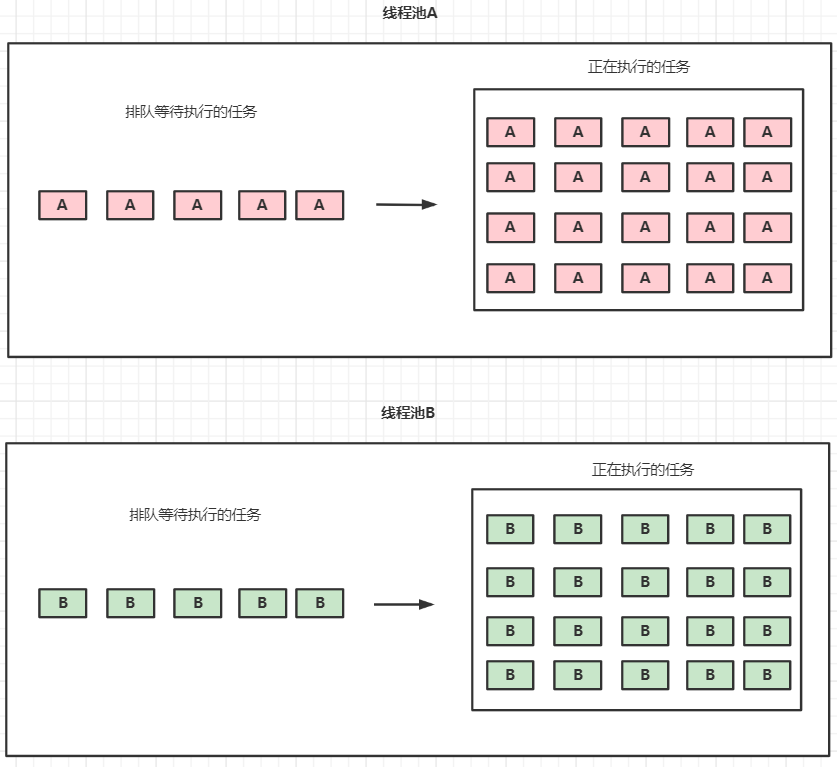
什么情况下我们不能这么做?
如果任务A和任务B之间有相互依赖或者先后顺序的关系,例如任务A内部调用任务B 和 任务A先执行完然后任务B要拿任务A的执行结果作为参数执行。此时我们无法将A和B放到两个线程池执行(因为并发是无序的)。而且此时任务A和任务B本身就是一个在业务上具有原子性的个体,不存在什么竞争关系。
三、相互依赖的任务共享线程池导致死锁(阻塞住整个线程池)
假设有这么一个场景,有一个并发量为5的 线程池P 负责处理 任务A,任务A内部会调用任务B,而且任务A会将任务B也塞到线程池P中执行,并且等待B执行完之后A才往下执行 。伪代码类似于:
from concurrent.futures import ThreadPoolExecutor, as_completed
pool = ThreadPoolExecutor(max_workers=5)
def A():
# ... A do something before B
taskB = pool.submit(B)
taskB.wait()
# ... A do something after B finish
def B():
# ... B do something
return
def main():
tasks = []
for i in range(5): # 并发执行5个任务A
tasks.append(pool.submit(A))
for task in as_completed(tasks):
print(task.get_result())
考虑一种比较很可能的情况,第一个for循环执行完之后,5个任务A都进入到线程池同时执行,但是由于pool的最大并发任务数是5,所以任务B无法被线程池执行,但是任务A又要等待任务B执行完之后才能继续之后 “# ... A do something after B finish” 的逻辑。
于是就发生了死锁,任务A等待任务B,任务B也在等待任务A释放线程池中的线程。而且之后如果有别的新任务C进入线程池后也无法得到执行。
解决方法:不要将子任务(任务B)放到父任务(任务A)同一个线程池中执行,而是让子任务串行执行。
解决方法的伪代码如下:
pool = ThreadPoolExecutor(max_workers=5)
def A():
# ... A do something before B
B()
# ... A do something after B finish
def B():
...
def main():
tasks = []
for i in range(5): # 并发执行5个任务A
tasks.append(pool.submit(A))
...
或者将任务A和任务B放到不同的线程池执行,不要共享线程池。
四、拒绝策略不当导致阻塞
这里我是参考的java的线程池。Java线程池主要有四种拒绝策略(是指线程内的任务遇到错误时的做法),如下:
1、丢弃任务并抛出异常;
2、丢弃任务,但是不抛出异常;
3、丢弃队列最前面的任务,然后重新尝试执行任务;
4、由调用方线程处理该任务;
在java的线程池中,这四种策略是内置在线程池的类库中的,而且如果拒绝策略设置不当会导致线程池永久阻塞。对于python线程池而言,程序没有内置这些拒绝策略,而是需要开发者手动处理错误。
个人建议是无论出现错误时,在线程池内部是否抛出异常,都应该记录错误日志方便查阅。并且并不建议重试,因为正常情况下任务的执行不会出错,如果出错了基本都是因为逻辑有问题,即使重试也会失败。不如记录下日志,并且根据日志给出的信息作出修正。
如果您需要转载,可以点击下方按钮可以进行复制粘贴;本站博客文章为原创,请转载时注明以下信息
张柏沛IT技术博客 > Python多线程和多进程(六) 线程池的坑和问题——内存溢出、任务共享线程池导致饥饿或死锁和拒绝策略不当阻塞