更多优质内容
请关注公众号
请关注公众号

递归就是在函数中调用自身函数
递归的精髓在于:将问题分解为规模更小的相同问题
一个简单的递归应用:数列求和
用循环解决
def listsum(numList):
res = 0
for i in numList:
res += i
return res
假如没有循环这种语句,我们可以用递归解决
递归需要满足3个条件:
1. 必须要有一个结束条件
2. 递归要使整个过程向结束条件演进(减小规模)
3. 递归要调用自身
这三个条件的具体体现
条件1具体体现为使用一个if判断
条件2具体体现为 例如 add(n-1) 往add这个函数中传入的值是一个比原参数n小的值,这就叫做减小规模,每递归一次就会减小1次规模
条件3体现为就是 def add(n): ... add(n-1) ... 在函数add中调用add
递归的原理:
当一个函数被调用的时候,系统会将调用时的现场数据压入到系统“调用栈”里面。现场数据又叫做栈桢。
现场数据具体是:函数名,函数参数,函数内的局部变量等记录着当时函数的执行状况和进度。
当函数返回时,会从“调用栈”的栈顶会弹出栈桢,恢复现场,按地址返回
调用时入栈,返回时出栈
由于栈是后进先出的特性,所以递归函数的返回顺序和调用顺序是相反的。
递归应用1 : 任意进制转换(10转2,8,16)
问题分析:
进制转换的方法就是不断除法运算并取余数。
结束条件:除法运算的结果为0
def baseConverter(num,base=2):
convert_string = "0123456789ABCDEF"
res = num // base
yu = convert_string[num % base]
if res == 0:
return yu
else:
return baseConverter(res,base)+yu # 字符串连接,不是加法运算
# 或者可以写成
# def baseConverter(num,base=2):
# convert_string = "0123456789ABCDEF"
# if n < base:
# return convert_string[n]
# else:
# return baseConverter(n//base,base) + convert_string[n%base]
========================================
递归应用2:递归可视化 之 分形树
分形树是用递归绘制的多层二叉树
在绘制之前介绍一个python的库,turtle,其意向为模拟海龟在沙滩上爬行留下的足迹,用于绘制简单图形
爬行(绘制直线): forward(n); backward(n) n为长度
转向: left(a); right(a) a为角度
抬笔和落笔: penup(); pendown() 抬笔后执行forward和backward只能移动海龟位置,不能绘制图像。落笔后才能绘制图像。
笔属性: pensize(s); pencolor(c)
开始绘图: turtle.done()
下面是实现分形树的代码
def tree(t,length): # t为turtle对象,length为主干的长度
if length >= 5: # 绘制的分支最小长度为5
t.forward(length)
t.right(20)
tree(t,length - 5) # 绘制右分支
t.left(40)
tree(t,length - 5) # 绘制左分支
t.right(20) # 角度调回来
t.backward(length) # 退回起点
if __name__ == "__main__":
t = turtle.Turtle()
t.left(90)
t.penup()
t.backward(100)
t.pendown()
tree(t,45)
turtle.done()
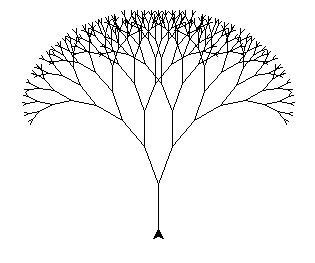
像这种整体图形和整体中的部分图形有相似特征的情况就叫做自相似
不仅是分形树,所有分形图都具有这个特性,都可以用递归来实现
===============================================
递归应用3: 复杂递归之汉诺塔
汉诺塔是一个复杂递归的问题,是一堆甜甜圈和3根柱子的故事。
故事是这样的:在一个印度寺庙中,有3根柱子,其中一根套着64个有小到大的像甜甜圈一样的黄金盘片,另外两根柱子没有套盘片。
僧人们要将这堆甜甜圈从一根柱子移到另一根上。
规则是:一次只能搬一个甜甜圈;大甜甜圈不能叠在小甜甜圈之上。

以3个甜甜圈为例:
三个甜甜圈从小到大分别为ABC,三个柱子是#1 #2 #3,三个甜甜圈一开始都在#1 ,标记位 #1 A;#1 B ;#1 C
移动过程如下:
#2 A (把A移动到第二根柱子)
#3 B
#3 A
#2 C
#1 A
#2 B
#2 A
最终结果为 #2 ABC
假如现在有5个甜甜圈ABCDE,如果用递归的思路,我们就不能按照上面的过程去想因为会很复杂,我们要简化成一个更简单的整体化的想法。
这个想法就是3句话:“我要将ABCD先移到#2。再将E移到#3。再将ABCD移到#3”
其中,第1,第3句话里面又包含了很多很多的过程。但这些过程都是重复的。
.png)
实现如下:
def moveTower(height,fromPole,withPole,toPole): # 移动最底部的那个甜甜圈之上的甜甜圈塔
if height >= 1:
moveTower(height - 1, fromPole,toPole,withPole)
moveDisk(height, fromPole, toPole)
moveTower(height - 1, withPole,fromPole,toPole)
def moveDisk(disk,fromPole,toPole): # 移动最底部的甜甜圈
print("Moving disk[%s] from {%s} to {%s}" % (str(disk),fromPole,toPole))
if __name__ == "__main__":
moveTower(3,"#1","#2","#3")
这个例子告诉我们,用递归解决问题的时候,思路绝对不复杂,相反思路应该很简单。我们只需想到第一步,就可以写出来,因为后面的很多步都是仿照的第一步完成的,要运用整体的思想。
=====================================
递归之优化问题和贪心策略
优化问题就是最优解,比如两点之间的最短路径。
一个经典案例:兑换最少个数硬币的问题。
例如买一个37块的东西,给了100,老板要找钱,我希望找给我的钞票数量最少(50+10+2+1)
贪心策略就可以解决这个优化问题。
贪心策略的核心就是从大到小,每次都试图解决问题尽量大的一部分。
例如这里的硬币问题,可以先用最大面值50元开始找钱,然后再往下,最后才是用1块去找钱。这就是贪心策略
下面我们结合贪心算法和递归解决这个问题
结束条件是: 要找的钱刚好是某一货币面值。
例如 找6块不满足结束条件,但是最后是找5块那么刚好有5块的面值的货币,就满足结束条件
算法1:贪心算法 + 遍历
def returnCoins(amount,coinList=[50,20,10,5,2,1]):
if amount >= 100:
return False
coinChange = {}
for coin in coinList:
coinNum = amount // coin
if coinNum:
amount = amount % coin
coinChange[coin] = coinNum
return coinChange
算法2:贪心算法 + 递归
def returnCoins(amount,coinList=[1,2,5,10,20,50]):
if amount >= 100:
return False
coinChange = {}
coin = coinList.pop()
res = amount % coin
coinNum = amount // coin
coinChange[coin] = coinNum
if res == 0:
return coinChange
else:
coinChange.update(returnCoins(res))
return coinChange
print(returnCoins(68))
上面的贪心算法其实思路很简单,先从面额最大的纸币开始找,然后再往小的找零。充分体现贪心策略从大到小的核心思想,每次都试图解决问题尽量大的一部分。
算法3:纯递归算法
def returnCoins2(change,coinList=[1,2,5,10,20,50],knownResult=[]):
minCount = change # 记录所有面值中,找回的最少的张数,一开始minCount要设的最大,所以最少的张数就是要找回的金额
rightCoin = 1 # 记录所有面值中,找回的最少张数的那个面值
for coin in coinList:
if coin in knownResult or change < coin: # 如果要找的钱比某币面值小或者这个面值之前已经找过了则肯定不会找这个面值的钱可以跳过
continue
count = change // coin
nextChange = change % coin
if count < minCount:
minCount = count # 记录minCount的目的是为了找到对应的rightCoin
rightCoin = coin
# 此时已经筛选出张数最少的那种币值
if nextChange: # 如果还没找完则递归
knownResult.append(rightCoin)
return [rightCoin] * count + returnCoins2(nextChange,coinList,knownResult)
else:
return [rightCoin] * count
它的思路就是先记录每种币值第一次找回的张数,取最少的那一种币值进行记录,然后对剩下要找的金额递归调用找零函数。但是为了在递归过程中不会重复计算,所以使用一个knowResult记录上一次调用函数时使用过的币值,在本次递归调用中就不用该币值去找零。这样可以大大提高递归过程中的效率。
算法4:动态规划算法
这个算法可以说使用了递归的思想,但是代码的实现没有用到递归。
具体的思路是这样的。
假如我要找 11 块,计算最少需要找几张人民币。假设要找的人民币数量有n张。我第一张要从 1 2 5 10 这4种币值里面去找。
假设 第一张是 10 ,那么剩下要找的就是1块,而1块钱刚好对应一个币值,所以1块钱要找1张,共2张。
假设 第一张是 5, ,那么剩下要找的就是6块,而6块钱要找的话就要1和5两张,此时共3张。
依次类推,我们可以得到,如果找回的第一张分别是1,2,5,10情况下还要找的钱数张数的解分别是 1,2,3,1
我们可以得到11块找的最少的集合是 [1,10] 和 [10,1]
当然上面 6块钱要找的最少张数是事先计算好了的,存放在一个表中,可以直接拿来用的。
所以假设要找的钱是x元,要求x的张数的最优解我们要做两件事:
1. 计算1~x-1这些钱的要找的最少张数并记录在一个表中
2. 查表得到x的张数最优解
怎么查表?
例如,65块,我要找的第一张有1,2,5,10,20,50 6种选法。6中选法都要算。
第一种 选50 ,剩下15,15这个数的解已经记录在表中是2(10+5)。那么65的解就是15的解+1 = 2+1 =3
第二种 选20,剩下45,45这个数的解已经记录在表中是3(20+20+5),那么65的解就是45的解+1 = 3+1 =4
第三种 选10,剩下55,55这个数的解已经记录在表中是2(50+5),那么65的解就是55的解+1 = 2+1 =3
第四种 选5,剩下60,60这个数的解已经记录在表中是2(50+10),那么65的解就是60的解+1 = 2+1 =3
第五种 选2,剩下63,63这个数的解已经记录在表中是4(50+10+2+1),那么65的解就是63的解+1 = 4+1 =5
第六种 选1,剩下64,64这个数的解已经记录在表中是4(50+10+2+2),那么65的解就是64的解+1 = 4+1 =5
动态规划算法的核心是,要创建一个表记录之前问题的最优解,本最优解依赖于之前最优解。这个存储表是关键。
下面正式实现一下这个算法:
def dfReturnCoins(change,coinList=[1,2,5,10,20,50]):
storeList = [0] * (change+1) # 存放最优解的容器,其中找的钱为x的最优解放在storeList[x]中,storeList[0]不存放任何钱的最优解而用于计算1块钱的最优解而设置的
# 计算change的最优解就要先计算1~change-1这些找钱的最优解,最后也将change的最优解放在表中
for money in range(1,change+1):
minCount = money # 设定初始最优解,初始最优解是全部用1块的解
for coin in [c for c in coinList if c<=money]:
if storeList[money-coin] + 1 <= minCount: # 如果money对某一币值的最优解(即money-某一币值的钱的最优解+1,这个1是指coin这张纸币)小于当前最优解,则更新当前最优解
minCount = storeList[money-coin] + 1
# 记录下money的最优解
storeList[money] = minCount
print(storeList) # 顺便打印出容器中所有货币的最优解
return storeList[change]
if __name__ == "__main__":
print(dfReturnCoins(22))
# 结果如下:
[0, 1, 1, 2, 2, 1, 2, 2, 3, 3, 1, 2, 2, 3, 3, 2, 3, 3, 4, 4, 1, 2, 2]
2
所以22块的最优解是2张。
上面如果想返回最少张是哪几种币值可以变一变,很简单:
# coding=utf-8
def returnCoins(change,coinList=[1,2,5,10,20,50]):
changeMap = {0:[]} # 保存change为1~99块的最优解
for c in range(1,change+1):
minCoinNum = c
bestCoin = 1
bestCoinIndex = 0
for coin in coinList:
if c >= coin:
mapIndex = c - coin
coinNum = len(changeMap[mapIndex])
if coinNum + 1 < minCoinNum:
minCoinNum = coinNum + 1
bestCoin = coin
bestCoinIndex = mapIndex
temp = changeMap[bestCoinIndex].copy() # 例如我要找75块,最后一张想找的钱是5,而且5是最后一张的最优解,那么temp就是70块的纸币组合
temp.append(bestCoin)
changeMap[c] = temp
return changeMap[change]
print(returnCoins(94)) # [50, 20, 20, 2, 2]
这种算法的正确用法应该是先将1~99块的所有最优解计算出来存到一个全局变量中,下次无论查多少钱的找零直接从表中查询即可,这样只用创建1次这个表,而不是每次查询找零的时候都创建一次这样的一个表。
==========================================
接下来我们用 动态规划算法 解决一个问题:
大盗潜入博物馆,面前有5件宝物(每件宝物可以重复拿),分别有重量和价值,大盗的背包仅能负重20公斤,请问如何选择宝物,总价值最高?
item weight value
1 2 3
2 3 4
3 4 8
4 5 8
5 9 10
首先,这个问题不能用贪心算法解决,因为重量和价值完全不成比例的时候用贪心算法收益会很低。
比如一个价值为10的东西重量有100,那肯定不会去偷它,但是贪心算法却会优先考虑这个价值为10的东西,因为他的价值最高。
用 动态规划算法 的思路解决博物馆大盗问题和找零的思路一模一样
# 博物馆大盗问题
# 该函数返回最优解的宝藏item
def stealTreasure(capacity,treasureDict): # 小偷背包的容量和宝物清单
storeList = [{"value":0,"item":[]}]
for c in range(1,capacity+1):
maxValue = 0
maxValueItems = []
limitDict = {item:info for item,info in treasureDict.items() if info["weight"] <= c}
for item,treasure in limitDict.items():
nowMaxValue = storeList[c - treasure["weight"]]["value"] + treasure["value"]
if nowMaxValue >= maxValue:
maxValue = nowMaxValue
maxValueItems = storeList[c - treasure["weight"]]["item"] + [item]
c_dict = {"value":maxValue,"item":maxValueItems}
storeList.append(c_dict)
return storeList[capacity]
if __name__ == "__main__":
capacity = 20
treasureDict = {
"1":{"weight":2,"value":3},
"2":{"weight":3,"value":4},
"3":{"weight":4,"value":8},
"4":{"weight":5,"value":8},
"5":{"weight":9,"value":10},
}
print(stealTreasure(20,treasureDict))
请注意,一开始 storeList 不能写为
storeList = [{"value":0,"item":[]}] * (capacity+1)
否则 storeList中的所有元素由于是dict类型所以都指向一个引用,一个元素边其他元素也会一起变。
=========================================
最后我们用递归的思路去解决博物馆大盗问题:
结束条件:背包容量小于重量最小的宝物
最小问题:背包随机装下一个宝物
# 博物馆大盗问题的递归解法(该算法的性能远远低于动态规划算法)
# 该函数返回最优解的宝藏item
def stealTreasure2(capacity,treasureDict,zeroDict): # 小偷背包的容量和宝物清单
maxValueDict = zeroDict
treasureDict = {item:info for item,info in treasureDict.items() if info["weight"] <= capacity} # 只挑选重量小于背包剩余容量的宝物
if not len(treasureDict.keys()): # 递归结束条件
return zeroDict
for item,info in treasureDict.items():
resDict1 = {'value':0,"items":[]}
resDict1['items'].append(item)
resDict1['value'] += info["value"]
leftCapacity = capacity - info["weight"]
resDict1 = combineDict(resDict1,stealTreasure2(leftCapacity,treasureDict,zeroDict))
if resDict1['value'] > maxValueDict['value']:
maxValueDict = resDict1
return maxValueDict
def combineDict(dict1,dict2):
final_resDict = {"value":0,"items":[]}
final_resDict['value'] = dict1['value']+dict2['value']
final_resDict['items'] = dict1['items']+dict2['items']
return final_resDict
if __name__ == "__main__":
capacity = 20
treasureDict = {
"1":{"weight":2,"value":3},
"2":{"weight":3,"value":4},
"3":{"weight":4,"value":8},
"4":{"weight":5,"value":8},
"5":{"weight":9,"value":10},
}
print(stealTreasure2(26,treasureDict,{'value':0,"items":[]}))
# 使用递归来解决这个问题,其实本质上是使用了排列组合,他的复杂度远比动态规划算法大。
# 下面这个是作者给出来的递归算法的代码,这个代码的前提条件是每个宝物不能重复
tr = {(2,3),(3,4),(4,8),(5,8),(9,10)}
max_w = 20
m = {}
def thief(tr,w):
if tr == set() or w == 0:
m[(tuple(tr),w)] = 0
return 0
elif (tuple(tr),w) in m:
return m[(tuple(tr),w)]
else:
vmax = 0
for t in tr:
if t[0] <= w:
v = thief(tr-{t},w-t[0]) + t[1]
vmax = max(vmax,v)
m[tuple(tr),w] = vmax
return vmax
print(thief(tr,max_w))
其实,我的建议是,除非特定用法,不然能不用递归就不用递归,因为难想,而且性能比较低,时间复杂度大。