更多优质内容
请关注公众号
请关注公众号

Scrapy分布式爬虫的原理很简单,它依赖于scrapy的一个组件scrapy-redis。大致为:
将scrapy代码部署到多台工作机器(简称为服务器W),将redis服务部署到另一台服务器(简称为服务器R)。多台机器W从服务器R的redis容器中获取要爬取的url进行爬取,并将解析到的新url存到服务器R的redis中。
每个工作服务器W之间通过服务器R的redis中间件进行通信和传递爬取的url。
通过一台中央服务器R对多个W进行调度的好处是,所有机器W获取和储存url都是存到一台数据容器中,这样就保证W之间不会有重复爬取。
需要注意的是,scrapy-redis不是一个框架,而是配合scrapy框架的一个组件。
下面是原scrapy的架构图
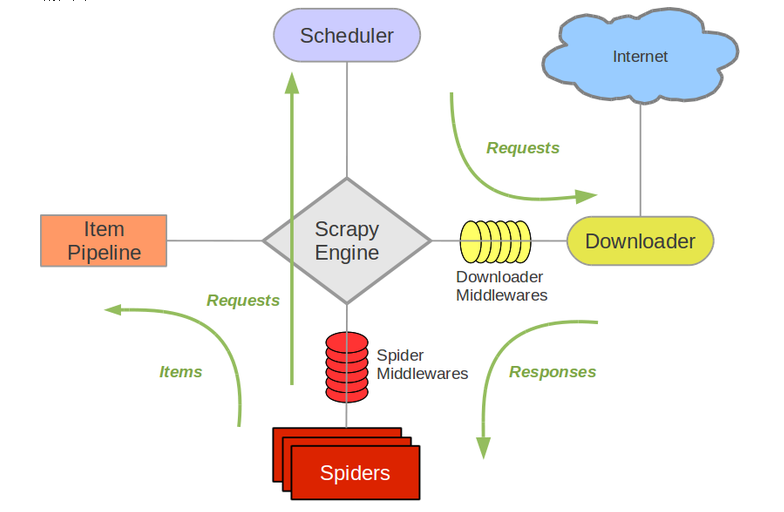
下面是scrapy-redis配合scrapy的架构图
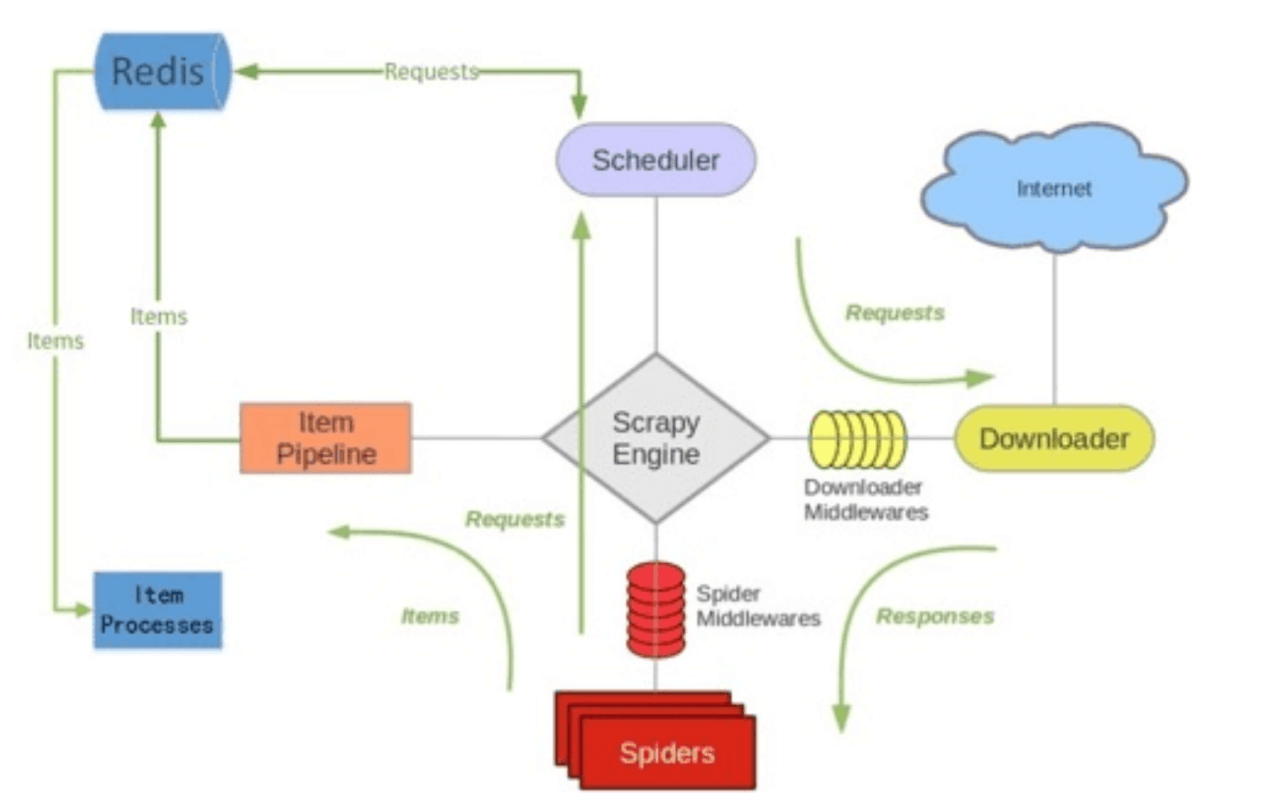
相比于单纯的scrapy框架,它多出来的就是左边和redis服务交互的部分。
为什么scrapy-redis可以实现分布式爬虫?
因为在原有的scrapy框架中,待爬取的请求是存储在scrapy的一个dequeue双向队列中,但是多个scrapy开启的进程,它们各自的请求队列是独立的,也意味着多个scrapy进程的待爬取请求(或者说url)是无法共享和传递的。结果就是,即使将多个scrapy部署在了多台服务器上,它们也只能各自为战,而不能相互协作。
Scrapy-redis则引入了redis中间件作为多台机器上的scrapy产生的请求的存储容器,多台机器上的scrapy进程可以通过redis共享待爬取的url以及通信,从而实现了分布式爬虫。选择redis作为中间件而不是mysql是因为redis是纯内存操作,数据的存取速度极快,不会影响到爬虫的效率。如果使用mysql作为中间件意味着Request请求的存取是IO操作,会严重影响爬虫的效率。
分布式爬虫涉及到的redis的数据结构
包含list结构的队列,zset结构的队列和set集合。
Request queue用于存储待爬取的请求(zset结构,使用zset而不是list是因为每一个Request请求有优先级,可以使用zset中的score标记其优先级或者说权重)
Item queue用于存储spider爬取得到的数据(list结构,可以使用brpop从该队列中消费item)
Start urls queue 用于存储起始url的队列,可以根据自己的需要决定使用队列还是set集合来保存起始url。(list结构)
Duplicate set用于记录爬取过的url(set结构,利用其没有重复值的特性达到去重的目的)。
Scrapy-redis的4个组件
下面这4个组件其实是Scrapy-redis提供的类或者函数。
1. scheduler调度器
Scrapy-redis的scheduler调度器的会将请求(经过序列化后的scrapy封装的Request对象)存到Redis的队列中,也可以从Redis的队列中取出带爬取的请求分配给Spiders组件。
原本的scrapy框架也有scheduler调度器,只是原来的scheduler是让Request对象在scrapy引擎、Pipeline和Spiders之间流转,并且Request的存取是针对本地的deque双向队列中进行的。但是多了redis之后,变为了让Request在redis中存取。
2. Duplication Filter 请求过滤器
请求过滤器的作用是去重。
请求过滤器比较重要的部分是包含了redis的用于存储url指纹的set集合和指纹函数。指纹函数的作用是将一个Request对象编码为一个定长的字符串以便存入redis(redis无法存对象,只能传字符串,而且经过编码之后可以大大压缩request对象的大小,节省内存空间)。
指纹函数需要传入一个Request对象,该指纹函数会根据这个对象的url,参数等等经过sha1编码的方式生成一个指纹。这个指纹之后会看情况被放到redis的Duplicate set集合中:请求过滤器会判断该指纹是否已经存在于Duplicate set集合中,如果存在说明这是爬取过的url,就不会将这个Request再放入到redis的Request queue待爬队列中,就不会重复爬取;如果该指纹不存在于set集合中,说明是没爬取过的url,并且将指纹放入到Duplicate set集合,再将Request对象经过pickle序列化后放入Request queue待爬队列中,将来这个url就会被爬取。
根据Request生成指纹的作用很大,通过将指纹存到set中而不是将Request存到set中可以减小内存的占用。
请求过滤器会在Request写入redis队列前在scheduler中被调用以达到去重的作用。单机的scrapy是使用python中的set集合这个数据结构存储爬取过的url。
4.Item Pipeline 条目管道
以前单机scrapy中也有Item和Pipeline这两个类,Item的功能是作为一个容器字典将爬取到的数据字段封装成Item对象。而Pipeline则是供开发者编写数据处理功能,携带着数据的Item会在Pipeline中进行处理,过滤和持久化(如存入mysql数据库)等行为。
而引入scrapy-redis模块后,scrapy_redis提供了一个RedisPipeline管道,这个管道会将Item存到Redis的Item queue队列中。这个队列用于临时存储爬取到的数据,但是不能长时间存储(因为长时间保存在redis中会导致内存占满),必须要有其他消费者将这些数据消费掉(比如开多个线程从这个列表中取出数据并写入到磁盘中)。
我们可以根据自己的需求选择是否使用这个RedisPipeline管道,或是使用自定义的Pipeline管道,或者是两者都一起使用。
5. Base Spider 爬虫
单机的Scrapy中Spider组件用于封装一个Request对象并交给scheduler调度器进行调度。
而scrapy-redis对Spider进行了扩展(扩展了的Spider是RedisSpider类),RedisSpider在原scrapy的Spider的行为基础上增加了连接redis和从redis读取url的功能。
我们再简单的总结一下
Scrapy-redis根据其引入redis的需求改写了Scrapy的4个组件,这4个组件的功能分别是
调度器:调度Request在redis、Spider和Downloader间流转
请求过滤器:url去重
条目管道:将爬取到的数据存入redis
爬虫:执行爬取任务
粗略的了解了scrapy-redis的原理之后我们就可以开始使用scrapy-redis搭建分布式爬虫了!如果你想了解更多关于scrapy-redis的原理和细节可以查看官方文档,并且阅读scrapy-redis的源码。
下面是官方提供的文档介绍:
===============================================================
接下来我们正式部署一个简单的分布式爬虫爬取网页内容,爬取的网站是本人的it博客的所有文章。
第一步开启redis服务
./redis-server /redis配置文件对应路径/redis.conf
可以通过修改配置文件的方式向所有ip开放redis服务(bind 0.0.0.0),但是必须设置密码(否则很容易被攻击),并以守护进程的方式运行。
第二步创建scrapy项目
# 安装scrapy
pip install scrapy
# 安装scrapy-redis组件
pip install scrapy-redis
# 创建一个scrapy项目
scrapy startproject zbpblog
第三步开始编写代码
1.修改配置文件
由于待会scrapy框架的代码中需要引入scrapy-redis并且与redis服务器通信,因此需要对配置文件进行修改,要修改的内 容就是指定上面的4个组件使用scrapy-redis提供的这4个组件,而不再是scrapy框架本身的这4个组件。
下面是新添加的配置项
# settings.py
# 使用scrapy-redis的调度器,scrapy_redis.scheduler.Scheduler是scrapy-redis模块中的一个类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 使用scrapy-redis的过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 调度器持久化,为True表示保存在redis的request queue和item queue以及其他数据会被持久化保存,不会随着爬虫程序的终止而消逝。如果为False的话,当爬虫被终止时,redis中的爬虫相关的数据会被删除
SCHEDULER_PERSIST = True
# 该配置项可选,表示使用scrapy-redis的Item pipeline条目管道组件RedisPipeline。如果使用了RedisPipeline的话,就会将爬取得到的item数据存到redis的item queue中;如果不使用RedisPipeline的话则可以使用自己编写的管道类对数据进行处理和持久化
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# 配置redis服务的主机名和端口
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
# 设置自定义的redis客户端参数,比如密码
REDIS_PARAMS = {
'password': '123456',
}
# 或者通过这种方式配置,它将覆盖REDIS_HOST和REDIS_PORT设置
# REDIS_URL = 'redis://user:pass@hostname:6379'
更多配置项可以在scrapy_redis官方文档查看。
2. 编写爬虫
# 在cmd运行下面的命令,创建一个spider
scrapy genspider Zbpblog zbpblog.com
然后,修改生成的Spider类,如下所示:
# Zbpblog.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
from zbpblog.items import ZbpblogItem
class ZbpblogSpider(RedisSpider): # 原scrapy继承scrapy.Spider蜘蛛,现在则继承scrapy_redis的RedisSpider蜘蛛
name = 'Zbpblog'
# start_urls = ['http://zbpblog.com/'] # 使用scrapy_redis后不再需要在类中指定start_urls
redis_key = "zbpblog:start_urls" # 声明用于存储起始url的redis列表的key
# allowed_domain = ["zbpblog.com"] # 我没有在类中指定allowed_domain而是在命令行以参数的形式指定允许爬取的域名。
def parse(self, response):
pass
注释了的地方就是scrapy_redis与原scrapy用法不同的地方
和原来的scrapy相比,写分布式爬虫的时候不用再在文件中声明初始url(strat_urls)。
初始url会被存入到redis的一个起始url队列(start_urls队列),而这个队列的key名需要在类中用redis_key声明,key名由开发者自己决定。
当运行爬虫的之后,scrapy会尝试从这个起始url队列取出一个起始url开始爬取,如果不存在这个队列或者这个队列没有起始url,则scrapy进程会被阻塞,直到这个队列被放入起始url。
当scrapy爬取完request queue队列和start_urls queue中所有的请求和url,该scrapy进程不会终止,而是再次进入阻塞(或者说睡眠)状态,直到有人再次往这两个队列中注入新的url或request请求就可以唤醒它开始新一轮的爬取。
注:Zbpblog.py的完整代码我会在文末给出,这里仅仅为了方便描述整个分布式爬虫的启动步骤而省略了逻辑部分。
3. 运行爬虫
首先需要把写好的scrapy项目部署在多台机器上。我将下面这项目代码部署在了我本地电脑和远程服务器,redis服务也部署在远程服务器中。
# 在本地和远程都运行下面的命令以启动爬虫
scrapy crawl Zbpblog -a domain=zbpblog.com
# 此时两台机器上的scrapy进程都被阻塞住,我们需要往 zbpblog:start_urls 这个起始url队列添加一个url
lpush zbpblog:start_urls http://zbpblog.com/
这时,两个 scrapy进程被唤醒并开始爬取。
4. 分析爬取过程中涉及到的redis key
在分布式爬虫运行的过程中,我们查看redis中生成的与此次爬取相关的key有这些:
Zbpblog:start_urls
Zbpblog:requests
Zbpblog:items
Zbpblog:dupefilter
Zbpblog:start_urls 是一个list列表,用于存放起始url。在启动scrapy之后,scrapy_redis内部会执行一个"brpop zbpblog:start_urls" 的命令,阻塞式的从这个列表取出起始url并开始爬取。如果这个列表中没有元素,则brpop会阻塞scrapy进程,直到有起始url被放入列表才被唤醒。
Zbpblog:requests 是一个zset有序集合,用于存放爬取过程中产生的待爬取的request。每一个request都是以序列化之后的形式存在zset中,是一串类似于这样的内容。
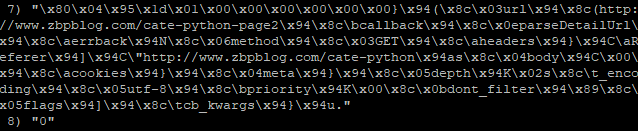
除此之外,zset中还记录了每一个request请求的权重,以决定这个请求的爬取优先级。
scrapy在启动之后除了会监听起始url队列之外,还会监听这个zset优先级队列,只要两个队列中任何一个队列有值可供消费就可以唤醒阻塞的scrapy进程。
Zbpblog:items 是一个list列表,用于存放爬取得到的item数据,里面的每一个元素是一个json字符串(可以用json模块转为字典)。
Zbpblog:dupefilter 是一个set集合,用于存放爬取过的请求的指纹(或者说是url指纹),里面的每一个元素是一个长为40位的字符串。每一次将request请求存放到zset之前,都会先判断这个request请求生成的指纹是否在这个set集合中,如果存在就不会将request请求放入到Zbpblog:requests这个zset。
需要注意的是,在爬虫运行结束时 Zbpblog:requests 和 zbpblog:start_urls这两个key会消失,原因是这两个key中的元素都已经被消费掉了。
Zbpblog:items会被保留,但是我们需要开额外的进程将里面的数据消费掉,进行数据处理和写入磁盘的操作。
Zbpblog:dupefilter会被保留,这样的话在下一轮新的爬取中就可以避免爬取重复的url
Zbpblog:requests 中每个元素的长度虽然有点长,但是在爬取的过程中,里面的元素会被不断的消费掉,又不断的生成,因此其实这个key里面的元素数量会维持在一个比较稳定的值,不会太占空间,除非是生成新请求的速度远远超过消费请求的速度。
Zbpblog:dupefilter 由于会被持久化保存,因此这个key会越来越大。按照每一个url的request指纹为40个字节的长度来算的话,保存2700万个指纹就会占用1G的内存。
PS:如果scrapy运行完毕之后处于阻塞状态,此时重新将一个爬取过的起始url放入起始url队列中,那么scrapy是不会被唤醒的,这个起始url虽然会被消费掉,但是这个起始url的request指纹已经在redis的set集合中存在过了,所以不会被再次爬取。
可以看到,每一个key都是以爬虫项目名称(即spider类中的name属性)作为前缀命名的,在本例中就是Zbpblog。因此分布在多个机器上的scrapy项目如果其项目名称不同的话那么他们的爬取会是相互独立的。
Tip 小贴士:
如果你的python版本低于3.8,那么在将request存入和取出redis的时候可能会出现这个报错
builtins.ValueError: unsupported pickle protocol: 5
这个问题是使用pickle包对request对象进行序列化时出现的。scrapy_redis不支持3.7及以下版本的pickle协议。
5. 将item通过Pipeline进行处理和保存
以上的4个步骤就完成了url的爬取和存储到redis。但如果我们希望将item数据存到其他地方比如csv、xml、MongoDB或者mysql,就可以自定义pipeline。同时scrapy框架的exporters模块也提供了一些数据存储到json、xml和csv的方法。
以存到csv为例,scrapy.exporters模块提供了CsvItemExporter类用于存储csv,下面是一个简单的示例:
class Save2CsvPipeline(object):
def open_spider(self, spider): # open_spider和close_spider方法在爬虫的运行生命周期中只执行一次,一般用于做pipline的初始化操作和创建资源的操作
self.f = open("zbpblog.csv", "wb") # 必须要用b的模式,写入字节流
self.csv_helper = CsvItemExporter(self.f)
self.csv_helper.start_exporting() # 启动数据导出
# PS: 如果在process_item方法return一个item,那么这个item会被传递给下一个pipeline
# 如果不返回任何东西,那么就不会运行之后的pipeline,即pipeline的流程就到此结束
def process_item(self, item, spider):
self.csv_helper.export_item(item) # 将item写入到csv
def close_spider(self, spider): # 关闭蜘蛛的时候要记得释放资源
self.f.close()
self.csv_helper.finish_exporting()
6. 将redis中的item数据消费掉
最后我们需要另外开一个和scrapy无关的外部进程用于将redis中的item队列中的item消费掉并保存到mysql的方法。
需要注意的是,我们爬取的数据可能需要进行数据清洗,过滤等操作,这个操作应该放在存入redis之前做这件事(也就是在RedisPipeline之前的其他pipeline中完成数据过滤),而不应该在外部进程中做。假如负责做数据处理的pipeline叫做DataHandlePipeline,我们可以将DataHandlePipeline的优先级设置的比RedisPipeline高(在settings.py的ITEM_PIPELINES配置项中设置),这样DataHandlePipeline就可以在RedisPipeline之前执行。
下面是消费redis中的item并存入到mysql的代码,为了能够提高写入到mysql的效率,我使用了协程异步并发的写入到mysql中:
# coding=utf-8
# save_data.py
import asyncio, aiomysql, aioredis, json, signal
# # 文章表
# create table zbpblog_arts(
# id int unsigned not null primary key auto_increment,
# category varchar(40) not null default '',
# title varchar(255) not null default '',
# create_time int,
# url varchar(100) unique
# )engine=innodb default charset=utf8mb4;
# # 文章详情表
# create table zbpblog_arts_content(
# aid int unsigned not null unique,
# content mediumtext
# )engine=innodb default charset=utf8mb4;
DB_CONF = {
'host':'127.0.0.1',
'port':3306,
'user':'root',
'password':'123456',
'db':'test',
'charset':'utf8mb4',
'cursorclass':aiomysql.DictCursor,
'autocommit':False,
}
REDIS_CONF = {
"host":'127.0.0.1',
"port":'6379',
"password":"123456",
'db':0
}
class DataSaveHelper:
stop = False # 用于停止savw2Db协程
def __init__(self, key):
self.key = key # redis中item queue队列的key
# 初始化mysql连接池和redis连接
# aioredis的使用可以参考官方文档 https://aioredis.readthedocs.io/en/v1.3.1/api_reference.html
async def initConnection(self):
self.dbpool = await aiomysql.create_pool(**DB_CONF) # 创建一个mysql连接池, 默认的最大连接数为10
# self.redis = await aioredis.create_connection((REDIS_CONF['host'], REDIS_CONF['port']), password=REDIS_CONF['password'], db=REDIS_CONF['db'])
self.redis = await aioredis.create_redis((REDIS_CONF['host'], REDIS_CONF['port']),
password=REDIS_CONF['password'], db=REDIS_CONF['db'])
async def save2Db(self):
# 将数据存入mysql
async with self.dbpool.acquire() as conn:
cursor = await conn.cursor()
sql1 = "insert ignore into zbpblog_arts values (%s, %s, %s, %s, %s)"
sql2 = "insert ignore into zbpblog_arts_content values (%s, %s)"
# 从redis中取出item数据
while not self.stop:
try:
item = await self.redis.brpop(self.key) # 可能会阻塞
data = json.loads(item[1])
except BaseException as e:
print("get zbpblog data failed on line %s: %s" % (e.__traceback__.tb_lineno, e))
continue
art_info = (None, data.get('category', ''), data.get('title', ''), data.get('create_time', ''), data.get('url', ''))
# 开启事务
await conn.begin()
try:
await cursor.execute(sql1, art_info)
await cursor.execute(sql2, (cursor.lastrowid, data.get('content', '')))
await conn.commit()
except BaseException as e:
await conn.rollback()
print("Save zbpblog data failed on line %s: %s" % (e.__traceback__.tb_lineno, e))
# 当接收到终止进程的信号量时(如 Ctrl+C)会触发closeConnection方法
def closeConnection(self):
print("Close all the connections")
self.stop = True # 用于停止save2Db中的无限循环
self.redis.close()
self.dbpool.close()
# 请不要在这里关闭事件循环,否则会报错,因为此时事件循环中的协程可能还没全部结束
# loop = asyncio.get_event_loop()
# loop.close()
# exit()
# 主协程
async def main(data_save_helper, coro_num = 10):
# 连接mysql和redis
await data_save_helper.initConnection()
# 创建多个协程来做数据入库的操作
tasks = [asyncio.ensure_future(data_save_helper.save2Db()) for i in range(coro_num)]
await asyncio.gather(*tasks) # 并发运行10个协程,并等待它们运行完
if __name__ == "__main__":
coro_num = 10 # 开启10个协程执行数据入mysql库的工作
key = 'Zbpblog:items'
data_save_helper = DataSaveHelper(key) # 创建入库工作的实例
loop = asyncio.get_event_loop() # 创建一个事件循环对象
# 异步的监听结束进程的信号量
# add_signal_handler方法内部会创建一个协程用于异步接收操作系统向本进程发送的指定信号量
# 当有任意一个指定信号量被事件循环捕获就会执行closeConnection方法
for sig in [signal.SIGINT, signal.SIGTERM]:
print(sig)
loop.add_signal_handler(sig, data_save_helper.closeConnection)
loop.run_until_complete(main(data_save_helper)) # 开启事件循环,这里会阻塞调用方(但不会真正阻塞线程)并切换到协程进行工作
# 关闭事件循环
loop.close()
在代码中,我开了10个save2Db协程循环取出redis的item队列的数据并写入数据库,由于数据要写入到2张表里面,而且两张表的id是关联的,因此要使用事务将2条insert操作变为一个原子操作,这样2个表里面的关联id才是一一对应的。
该程序会在item队列被清空后进入到阻塞状态,直到item队列被填充了数据才被唤醒。
当我们想手动结束这个进程的时候,为了让程序可以优雅的退出,我设置了异步监听信号量,使得手动结束程序的话可以显式的关闭redis和mysql连接,并且退出save2Db协程。当main协程结束的时候,run_until_complete方法会被唤醒,之后显式的关闭事件循环。
需要注意的是,必须要在所有协程都运行完毕后(也就是run_until_complete被唤醒之后)才能关闭事件循环否则会报错。
Tips:
1. 这个进程应该作为一个守护进程一直运行:
nohup python3.8 save_data.py &
2. 如果单条item数据很大,不建议写入到redis,而是直接写入到scrapy本机的Db中。因为redis命令的执行是单线程操作(至少在redis 6.0版本之前是),这意味着如果单个写入redis的数据太大会使得这个写入命令执行的时间会比较长,从而阻塞其他redis命令的执行(如request队列和duplication集合的读取和写入)从而拖慢爬虫的速度。最关键的是如果redis不是部署在局域网内的话,item数据写入到redis需要经过外网,数据在网络中的传输消耗的时长也会因为数据量过大而变长。
而且item写入到redis在从redis写入到Db,意味着多了2次内存拷贝的过程,这也会影响到效率。
如果你的redis是部署在scrapy所在服务器的局域网内,而且使用了不只一台redis服务而是分布式redis服务的话,那么也可以考虑将较大的item写入redis暂存。
最后,贴出这个爬虫小项目的spider.py部分以及为大家提供完整源码zip:
# spider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
from zbpblog.items import ZbpblogItem
from time import time
class ZbpblogSpider(RedisSpider): # 原scrapy继承scrapy.Spider蜘蛛,现在则继承scrapy_redis的RedisSpider蜘蛛
name = 'Zbpblog'
redis_key = "zbpblog:start_urls" # 声明用于存储起始url的redis列表的key
def __init__(self, *args, **kwargs):
# 动态定义 allowed_domains 成员
domains = kwargs.pop('domain', '')
self.allowed_domains = list(map(lambda x: x.strip(" "), domains.split(",")))
# 别忘了调用父类的构造函数
super(ZbpblogSpider, self).__init__(*args, **kwargs)
def parse(self, response):
# 先解析首页中的栏目页url
cate_url_path = "//ul[@id='header-cate-ul']/a/@href"
yield from self.__yieldRequestByXpath(response=response, xpath=cate_url_path, callback=self.parseDetailUrl)
# 再解析首页的详情页url
yield from self.parseDetailUrl(response) # 将parseDetailUrl产出的Request产出给parse的调用方(yield from相当于是一个通道,将子生成器parseDetailUrl的产出内容发送给parse的调用方)
# 解析详情页内容
def parseDetail(self, response):
item = ZbpblogItem()
item["title"] = response.xpath("//div[@id='blog-art-head']/h1/text()").extract_first()
item["category"] = response.xpath("//div[@id='blog-art-info']/span[1]/a/text()").extract_first()
item["url"] = response.url
item["create_time"] = int(time())
item["content"] = response.xpath("//div[@class='blog-art-cont']/div[@class='cont']").extract_first()
yield dict(item)
# 解析详情页url
def parseDetailUrl(self, response):
# 请求栏目页的分页
page_url_xpath = "//div[@id='page']//a/@href"
yield from self.__yieldRequestByXpath(response=response, xpath=page_url_xpath, callback=self.parseDetailUrl)
# 请求栏目页中的详情页
detail_url_xpath = "//div[contains(@class,'blog-info')]//h2[@class='blog-h2']/a/@href"
yield from self.__yieldRequestByXpath(response=response, xpath=detail_url_xpath, callback=self.parseDetail)
def __yieldRequestByXpath(self, response, xpath, callback):
urls = response.xpath(xpath).extract()
for url in urls:
complete_url = response.urljoin(url)
yield scrapy.Request(complete_url, callback=callback)
完整源码zip: