更多优质内容
请关注公众号
请关注公众号

什么是Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
本节先介绍如何安装Scrapy
一、 在Windows系统安装scrapy
1. pip3 install wheel
2.到下面网址下载Twisted
a. 进入到 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted , 下载:Twisted-17.9.0-cp36-cp36m-win_amd64.whl(请注意,根据你的python版本和Windows系统来选择对应的whl文件;其中cp36表示python 3.6版本,amd64表示64位系统)
b. 进入文件所在目录
c. pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
3.python -m pip install pypiwin32
4.pip3 install scrapy
在windows系统上直接pip install scrapy 是会报错的,报错是和twisted有关,所以在Windows端要手动安装twisted
如何判断scrapy是否安装成功:
只需进入cmd命令行
python #进入python命令行
import scrapy
如果没有报错说明安装成功
二、在Linux系统Ubantu安装scrapy
在Ubantu上也要手动安装Twisted:
# 安装相应的依赖
apt-get install python-dev
apt-get install libevent-dev
apt-get install libssl-dev
apt-get install libpython3.6-dev # 如果你的python是3.6版本的话,其他版本则对应版本安装
# 下载twisted
wget https://files.pythonhosted.org/packages/90/50/4c315ce5d119f67189d1819629cae7908ca0b0a6c572980df5cc6942bc22/Twisted-18.7.0.tar.bz2
tar -xjvf Twisted-18.7.0.tar.bz2
# 安装twisted
cd ./Twisted-18.7.0.tar.bz2
python3.6 setup.py build
python3.6 setup.py install
# 安装scrapy
pip install scrapy
三、在Linux系统Centos安装scrapy
在Centos中(我的是Centos 7),安装scrapy很简单,直接一句
pip install scrapy
即可
四、scrapy架构和核心技术
光是会用还是不够的,我们要了解scrapy的原理和架构,以及为什么我们要用scrapy去做爬虫,它的优势在哪里。下面我借鉴csdn的一张scrapy架构图来展示scrapy各个组件之间
1. scrapy的架构
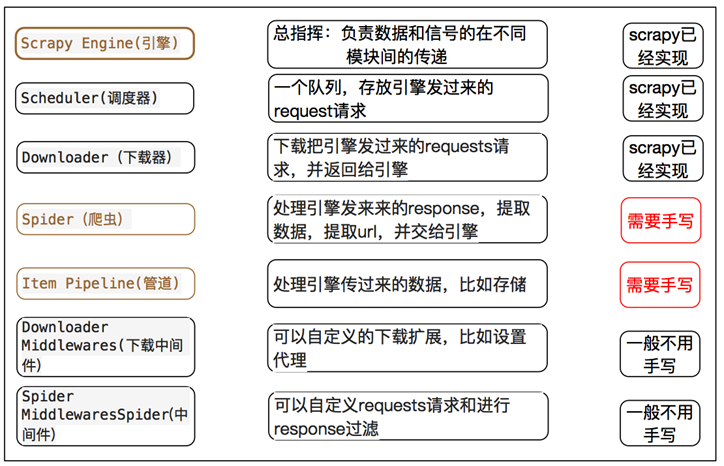
scrapy包含以下组件
Scrapy引擎(Engine):引擎是Scrapy架构的核心,负责数据和信号在组件间的传递。
调度器(Scheduler):存储带爬取的网址,并确定网址的优先级,决定下一次爬取的网址(相当于是一个任务队列,存放着待爬的url)。
下载中间件(Downloader Middlewares):对引擎和下载器之间的通信进行处理(如设置代理、请求头等)。
下载器(Downloader):对相应的网址进行高速下载,将互联网的响应返回给引擎,再由引擎传递给Spider组件处理。
爬虫中间件(Spider Middlewares):对引擎和爬虫之间的通信进行处理。
爬虫(Spider):对响应response进行处理,提取出所需的数据(可以存入items),也可以提取出接下来要爬取的网址并传给调度器。
实体管道(Pipline):接收从爬虫中提取出来的item,并对item进行处理(清洗、验证、存储到数据库等)。
2. scrapy运行流程
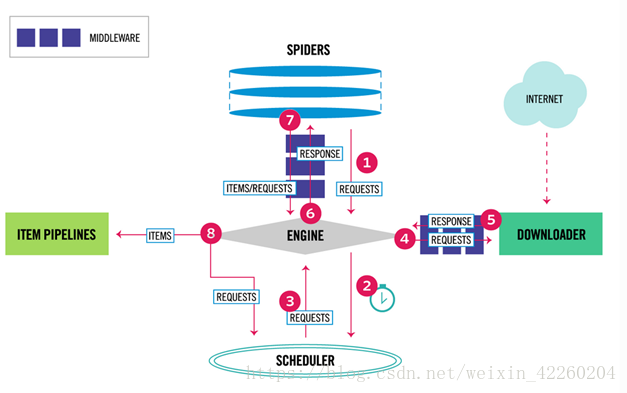
A. 开发者在spider组件的构造方法中定义初始url,在parse方法中将初始url封装为Request对象并将这个Request对象传递(yield)给Engine引擎,中间会途经spider middlewares中间件。(Request对象表示待会儿会发起一个url请求)。
B. Engine引擎将Request对象传递给Scheduler调度器中,所有的Request对象在调度器这个队列中排队,等待被弹出和发起请求(url在调度器中会进行去重)。
C. Request对象从调度器被downloader组件取出,中间会途径下载中间件进行请求的预处理(如添加header头,使用代理等操作),到达下载器的时候,下载器会发起http请求,获取网页响应并封装为一个Response对象。
D.Response对象通过Engine引擎被传递给Spider组件(中间会经过spider middlewares中间件),Spider组件会对返回的Response进行解析,一般会解析出两部分内容。一部分是开发者所需的内容信息和字段,它们会被放入到Item容器并传递给Pipeline处理;另一部分是新的要爬取的url,它们会被封装为Response对象,并再一次被丢给调度器等待被爬取。
E.进入到Pipeline组件的Item对象会及进行一系列的数据校验,清洗和入库的处理。
在这个过程中:
spider组件就是一个生产者,会往Scheduler调度器中注入任务;downloader下载器就是一个消费者,会从调度器中取出任务。这是一个典型的生产者消费者模型。
数据和信号从一个组件到另一个组件都会经过Engine引擎。
3. scrapy的优势和高效的原因
scrapy的优势当然是爬取的速度快啦,为什么scrapy这么快?原因是它的内部使用了twisted框架,twisted框架是基于事件驱动的网络引擎框架。可以用几个词来高度概括twisted的工作机制:事件驱动 + 事件循环 + 协程 + 非阻塞IO的方法,通过这种方式可以做到让单线程进行高并发。
让我们一一说一下这几个词意味着什么(下面说的客户端就是指我们写的爬虫,服务端就是指我们爬取的网站):
非阻塞IO:这个特性使得单线程在发出网络IO请求之后无需等待这个请求在网络传输过程中浪费的时间(包括请求发送到服务端的时间、服务端处理请求的时间和响应返回到客户端的时间),而去发起其他请求或者处理返回的响应(也就是说它虽然是一个单线程,但是这个单线程不会因为IO等待而停止工作,不会空闲下来)。
事件驱动:首先客户端在发请求之前会将发请求的socket套接字传递到内核的多路复用器中,并给这个socket的读事件注册一个回调函数。当服务端将响应返回给客户端的时候,客户端读事件就绪,内核会自动触发之前注册的回调函数,通知单线程去接收这个响应和对响应进行处理。事件驱动这个特性使得内核通过一种通知的机制让单线程处理之前发出去的请求返回的响应。这个特性是单线程能做到并发的一个重要条件。
协程:协程本质上是一个或多个任务函数(协程函数)生成出来的协程对象。单线程通过创建多个协程并且在多个协程间切换执行的方式做到高并发。协程的有点在于:它是轻量级的,创建一个协程远比创建一个线程的资源消耗小;它的切换速度远比线程的切换快。所以使用协程的话我们可以随意创建成千上万个协程进行高并发工作,可是使用多线程,我们只能创建最多几十个,再多反而会将时间浪费在线程的切换上,而且浪费资源。
当然协程的坏处是,协程需要由用户程序进行调度,会造成用户程序的逻辑比较复杂,开发者比较烧脑。线程则是由内核和操作系统进行调度,调度的算法不用我们开发者去设计。
让我们对比一下同步单线程,多线程和协程(异步单线程)的工作方式和效率
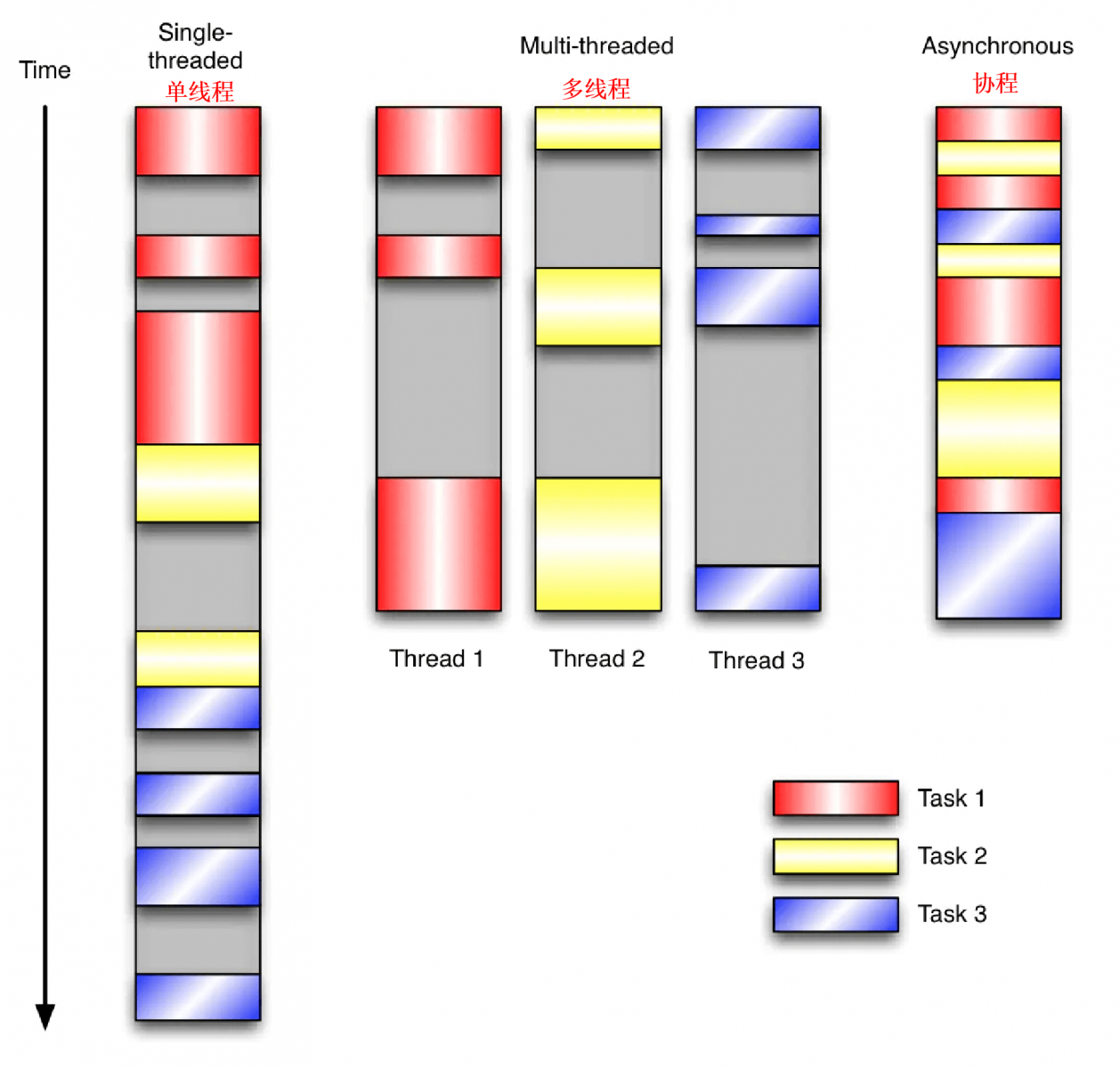
事件循环:事件循环就是用户程序会写一个死循环对所有的协程状态用一个方法(select())进行监控,如果没有协程状态达到就绪(即协程结束了等待状态,可以继续往下执行工作),事件循环就会被select()方法阻塞住。一旦有协程就绪,select()就会返回所有的就绪协程给调用方,让调用方切换到这些协程继续执行这些协程的工作。协程就是由事件循环和调用方进行调度的,协程间的切换依赖于事件循环。(什么是调用方,调用方就是开启事件循环的一方,或者说相当于C语言或Go语言中的main方法)
twisted框架使用的是reactor事件循环。Reactor可以感知网络、文件系统以及定时器事件。它等待然后处理这些事件
基本上reactor完成的任务就是:
while True:
timeout = time_until_next_timed_event()
events = wait_for_events(timeout)
events += timed_events_until(now())
for event in events:
event.process()
Twisted目前在所有平台上的默认reactor都是基于poll多路复用器。此外,Twisted还支持一些特定于平台的高容量多路复用API。这些reactor包括基于FreeBSD中kqueue机制的KQueue reactor、支持epoll接口的系统(目前是Linux 2.6)中的epoll reactor,以及基于Windows下的输入输出完成端口的IOCP reactor。
用一句话概况:scrapy的高效是由于使用了 协程+事件循环 的机制做到了用单线程达到高并发。而这些都归功于twisted框架。
之后我还会专门出一个关于twisted框架的文章。
参考文章:
https://blog.csdn.net/weixin_42260204/article/details/81408960
https://www.jianshu.com/p/ffc90ace9ca9
如果您需要转载,可以点击下方按钮可以进行复制粘贴;本站博客文章为原创,请转载时注明以下信息
张柏沛IT技术博客 > 爬虫进阶之Scrapy(一) scrapy框架安装和架构介绍(Windows端,Centos和Ubantu)