更多优质内容
请关注公众号
请关注公众号

本文内容参考《redis设计与实现》一书总结归纳而得。
字典dict和哈希表hashMap
字典是redis数据库存储键值对的数据结构(redis字典的本质是hashMap),我们可以将整个redis数据库看成是一个庞大的字典结构,无论是字符串、列表、集合、哈希等类型他们的键都会作为字典的键,他们的值会作为字典的值。
例如
set name zbp
那么name和zbp的底层结构都是SDS,这两个SDS分别会作为键和值存在redis数据库字典中。
字典除了用来表示数据库之外,还是redis哈希类型的底层实现。当一个哈希键内包含的元素比较多或者里面的元素都是比较长的字符串的时候,redis就会用字典作为哈希键的底层实现。
redis字典的包含(2个)hashMap
下面我们看看redis是如何实现自己的hashMap的,其使用一个dictht结构体定义:
typedef struct dictht{ // hashMap
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 哈希表大小掩码,总是等于size-1
unsigned long used; // 哈希表已有(已使用)节点数,由于哈希表的table数组的每个元素可以有多个哈希节点,因此used属性可以大于size属性
}dictht;其中table数组中的每个元素是一个指向dictEntry结构的指针,dictEntry结构是一个哈希表节点,每个哈希表节点都包含一个键值对。如图所示为一个大小为4的空哈希表:
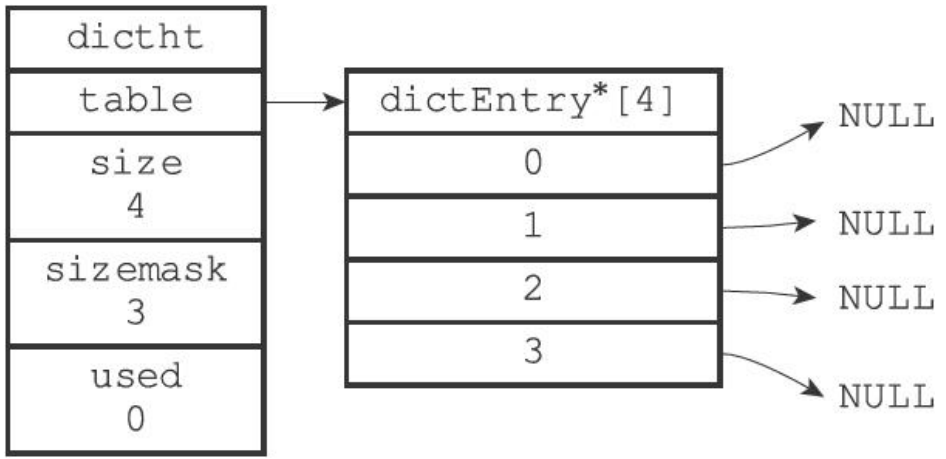
哈希表节点dictEntry结构,其本质是一个单向链表节点
typedef struct dictEntry{
void *key; // 键,可为任意类型
union{ // 值,是一个联合体
void *val; //
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next; // 指向下一个哈希表节点的指针
}键值对的值可以是一个指针,或者是一个uint64_t整数,又或者是一个int64_t整数。
next属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一次,以此来解决键冲突的问题。
字典dict结构
typedef struct dic{
dictType *type; // 保存着多个函数的结构体指针
void *privdata; // 私有数据
dictht ht[2]; // 一个数组,保存着2个哈希表结构
int rehashidx; // rehash索引,当没有在进行rehash时,为-1
}dict;字典有多种类型,不同的字典类型都有自己的方法实现,type就是保存这些方法协议的结构体,不同类型字典都要实现type中指定的方法。
我们重点关注ht属性,他是个保存着2个哈希表的数组,为什么一个字典会用到2个hashMap表呢?这是考虑到rehash,一般情况下字典只会用到ht[0]这个哈希表,ht[1]会在对ht[0]进行rehash时使用。
rehashidx记录了rehash的进度。当没有在进行rehash时,为-1。
下图为一个没有在rehash的字典
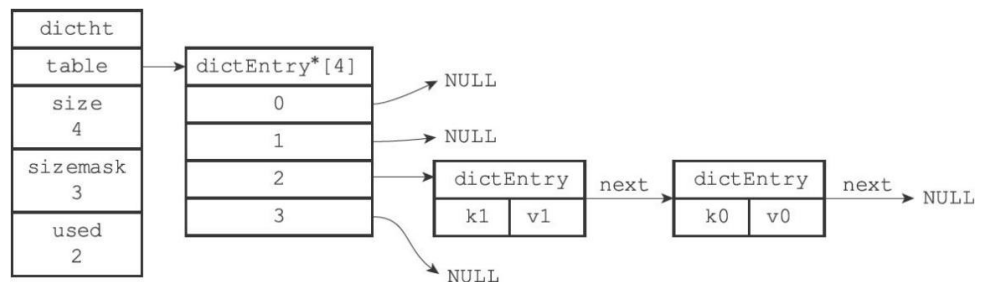
这样看的话,haspMap本质上是一个数组+单向链表组合而成的数据结构。而字典本质是两个hashMap。
哈希算法和解决键冲突
下面我们看看redis是如何根据一个redis的key和value放到hashMap中的。例如我们在执行一个命令
set name zbp
redis会对"name"这个redis键调用hash函数计算hash值,这个hash函数就包含在 dict->type 中。
// 计算hash值
hash = dict->type->hashFunction(key); // key为"name"
// 根据hash值计算索引值,计算的方式是用hash值对哈希表数组的长度掩码做&运算;ht[x]可以是ht[0]或者h[1],视情况而定。
index = hash & dict->ht[x].sizemask;假设计算出来的hash是10,sizemask是3, 那么 10 & 3 = 1010 & 0011 = 0010 = 2,所以index=2。
那么这个redis键值对会被封装为哈希表节点(dictEntry结构体的对象),并存到哈希表数组(dictht结构的table数组)的第3个槽点。
假如有另一个键值对 set sex male,而且sex计算出来的index也是2,那么他被封装为哈希表节点后也会放到第3个槽点,此时该槽点或者说该下标的元素就包含2个hashMap节点,前一个节点的next指针指向下一个节点。
通过在一个下标中存放多个index相同的哈希表节点,并且哈希表结点之间用指针相连来做到解决键冲突的问题。
需要注意的是,table属性这个数组中每个元素存储的是dictEntry节点链表中的第一个dictEntry节点的指针。当发生键冲突的时候,程序总是将新节点添加到链表的表头(复杂度O(1)),这是为了速度考虑。该单向链表没有指向链表尾部的指针,因此如果添加到表尾的话需要遍历整条链表(O(n))。
rehash
rehash是指当哈希表保存的key发生增多和减少时程序对哈希表分配空间的扩展和收缩过程(这里说的扩展和收缩具体是对table数组的收缩和扩展),这个过程涉及到对哈希表数组的所有节点的key重新进行hash函数计算,即rehash。
什么时候扩展和收缩取决于哈希表的负载因子:
负载因子 = 哈希表已有节点数 / 哈希表数组的大小 = ht[0].used / ht[0].size
扩展条件:
1. 服务器没执行 bgsave 或 bgrewriteof 命令时,哈希表负载因子大于等于1。
2. 服务器执行 bgsave 或 bgrewriteof 命令时,哈希表负载因子大于等于5。
说简单点就是就是每个数组元素中的平均节点数>=1和>=5。也就是说,当数组的单个槽点中包含太多节点就会进行对数组的扩展从而将同一槽点的多个节点分散到多个槽点。
收缩条件:
负载因子 < 0.1时。
扩展的具体过程:
1. 对于某个字典,redis使用其ht[0]存储节点。当触发哈希表扩展时,会为ht[1]分配一个长度为n的数组,n是 ht[0]的节点数的2倍(ht[0].used * 2)。
2. 将ht[0]中所有键值对rehash到h[1],即重新计算键的hash值和索引值并放到ht[1]的指定位置上。
3. 释放ht[0],并将ht[1]置为ht[0],ht[0]置为ht[1]。
如下图所示,redis要对下图中的字典rehash:
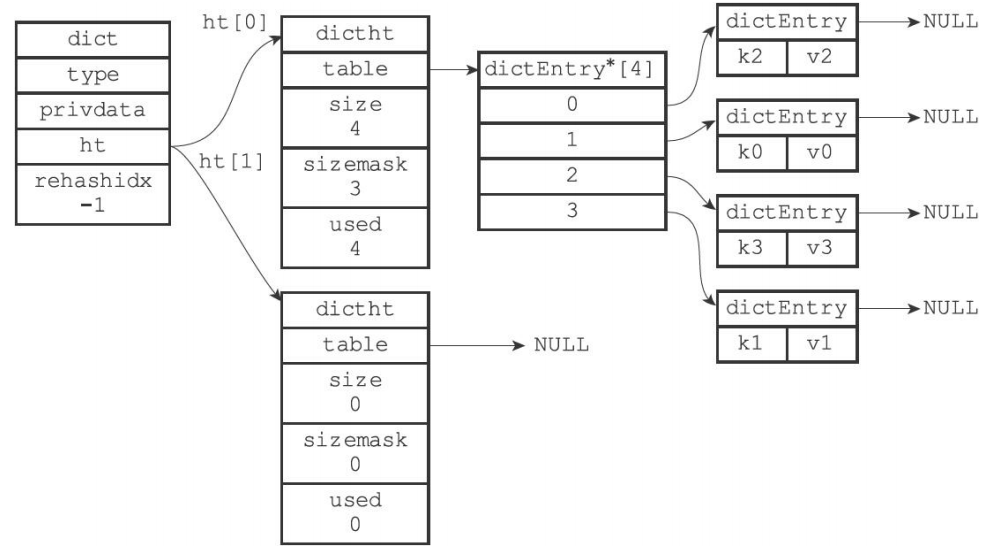
rehash后的字典为
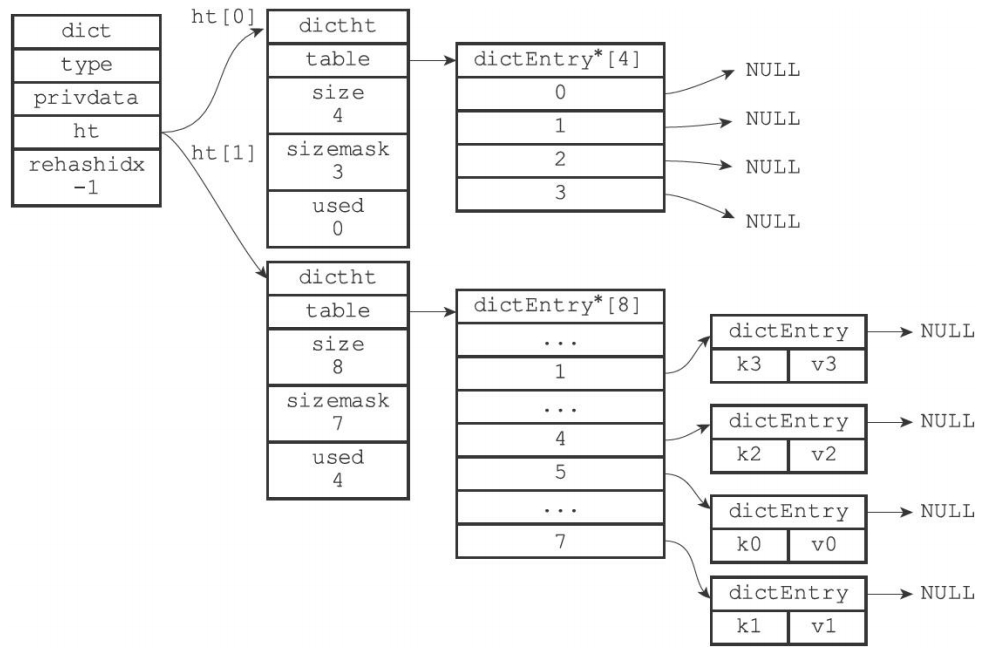
Q1: rehash扩展是如何做到分散节点到不同索引位置的
举个例子,有2个key计算得到的hash值分别是 3 和 8,数组长度是4,计算索引值为5 & (4 - 1) = 0101 & 0011 = 0001 = 1, 9 & (4 - 1) = 1001 & 0011 = 0001 = 1,所以这2个key都放在索引为0的位置。
扩展数组的长度为8后,5 & (8 - 1) = 0101 & 0111 = 0101 = 5, 9 & (8 - 1) = 1001 & 0111 = 0001 = 1,这2个key索引变成5和1,就有一个key被分到了索引为5的元素中了。
Q2: 为什么执行bgsave 或 bgrewriteof时扩展操作的触发条件要达到负载因子>=5呢
因为执行这两个操作的时候redis需要fork出一个子进程来操作以避免阻塞客户端请求的命令执行,操作系统会采用copy-on-write来节省内存,使得父子进程在读时使用同一份内存数据。
一旦发生写操作时,其对应的写操作相关的分页数据就会发生复制。字典的扩展操作会导致复制消耗多余内存。因此redis会尽量避免在bgsave 或 bgrewriteof时进行哈希表扩展。
渐进式rehash
当触发rehash的字典很大的话,比如里面有几千万个key,redis进程不可能一直进行rehash,因为redis是单进程,长时间处理rehash会阻塞客户端命令的执行。因此rehash实际上是分多次渐进式的完成的而非一次性直接完成的,redis会在执行客户端命令的间隔进行rehash。
在rehash开始后,字典的rehashidx会记录当前正在rehash的数组下标,例如正在rehash数组中下标为5的10个节点,那么rehashidx为5。执行期间每次对字典执行删除、查找和更新会在ht[0]和ht[1]两个哈希表数组中都进行一次删除、查找和更新,因为这个key可能在ht[0]中也可能在ht[1]中。添加操作只会在ht[1]操作,保证ht[0]的元素是在不断减少的,随着rehash的执行最终变为空表。
字典操作的复杂度
新增一个键值对是O(1),新增要执行的操作主要是计算hash值和index值,计算出index值后直接把key和value插到数组的index位置(即可以直接获取到ht数组index位置的内存地址)的链表开头即可,无需遍历ht数组。
查询和删除一个键也是O(1), 查询的具体操作也是计算计算hash值和index值,计算出index值后直接定位到ht数组index位置的链表,再对链表进行遍历查询即可。redis是通过在某个下标的空间内存放链表(其实是链表指针)的方式解决index冲突,除了redis外,其他应用对于哈希表的构建中,可能是使用平衡树来解决index冲突,这样好处是平衡树的查询复杂度为O(logn),相比于链表的O(n)效率更高。
释放整个字典复杂度为O(n)。