更多优质内容
请关注公众号
请关注公众号

本文内容参考《redis设计与实现》一书总结归纳而得。
跳跃链表skipList
跳跃链表是一种有层级且有序(排好序)的链表,链表的每个节点维持多个指向其他节点的指针以快速访问节点。
下面我们看看跳跃表具体是如何实现的,这就是一个跳跃链表的样子,每一列就是一个链表节点,每个链表节点有多层,每层有一个单向指针指向后面的节点。每个节点的节点值是有小到大有序排的。最后一个节点的指针指向null。节点存储的值从左到右是递增的,即有序的。
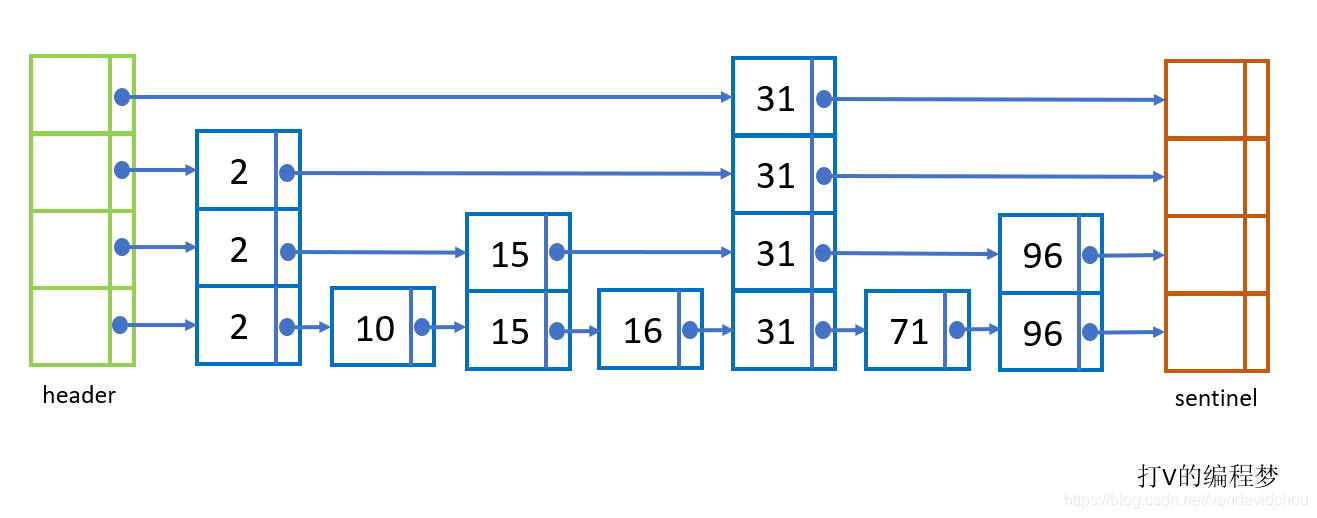
每一个节点的层数是由这个节点被创建的时候根据概率决定的。假设这概率为x,某个节点新建的时候,先为它创建第一层(因为所有节点都至少要有1层),之后循环获取概率,落在0到x的概率就为其多创建一层,落在x到1的概率就停止。当x=0.5时跳跃表的查询效率最高,因此我们可以用抛硬币来模拟。因此节点的层数越高的概率是越小的,例如某个节点它是4层的概率是1/2^3,它是5层的概率是1/2^4。
这个过程如下动图:
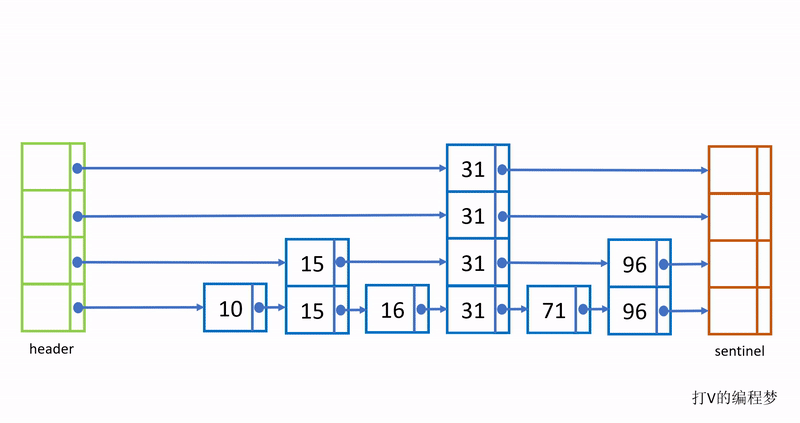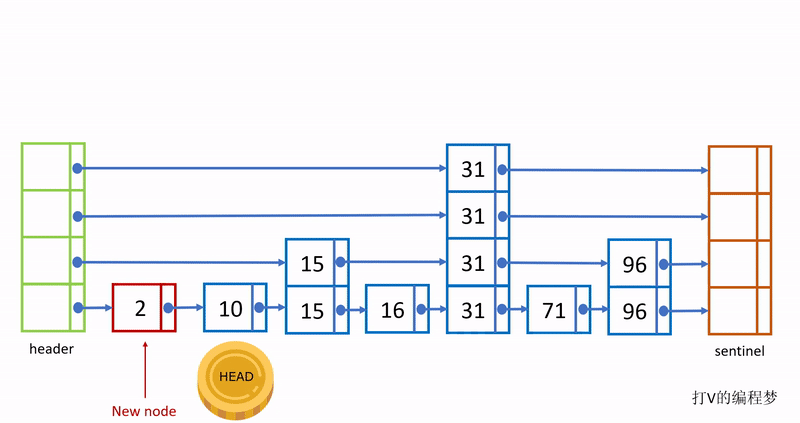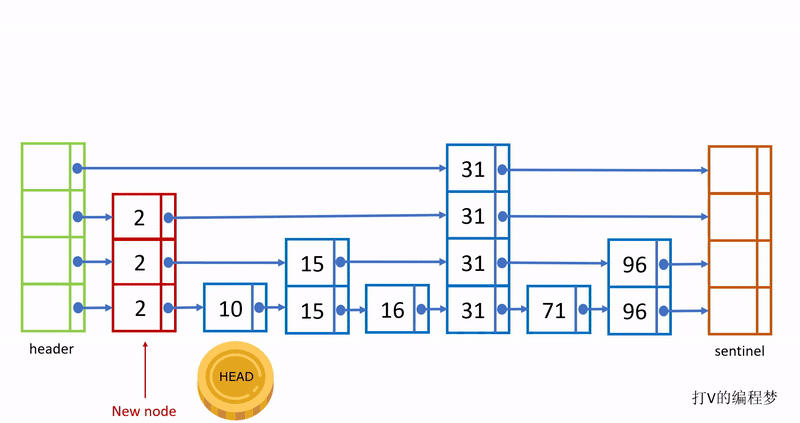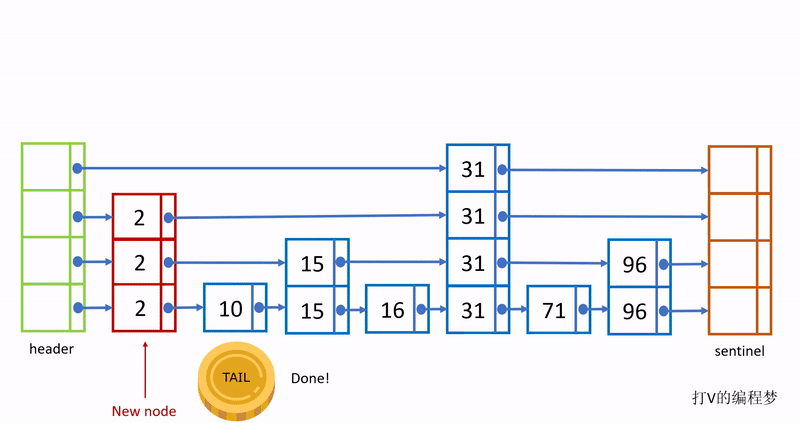
需要注意的是,这样创建出来的节点,最底层包含所有节点的值;越往上一层就只有下一层节点的约1/2的值,例如最底层有100个元素值,第二层就只有约50个元素值,第三层只有约25个元素值,假如最高层为5,那么最高层只包含100 / 2^4 = 6个元素值。
一个节点的第k层指向的肯定也是下一个节点的第k层。
每次查询是从头部节点的最高层开始,沿着最高层的指针往下一个节点找,直到找到下一个节点值大于目标值就开始往下一层开始找。如下动图所示:
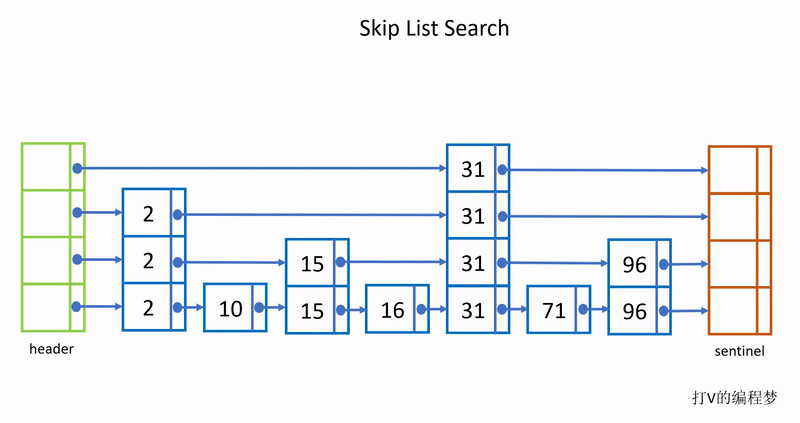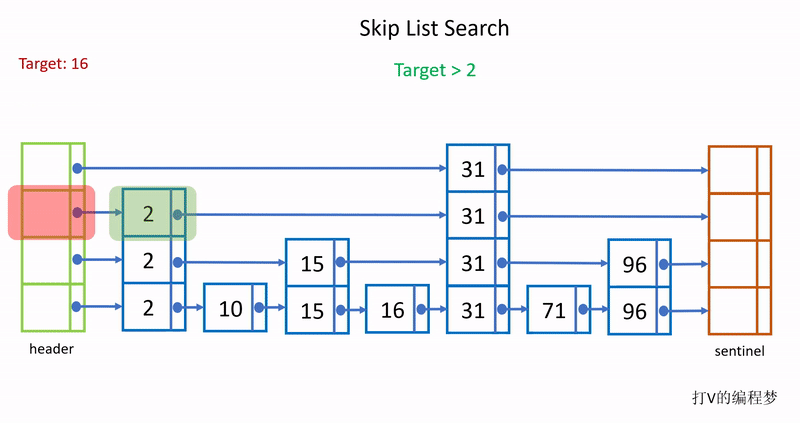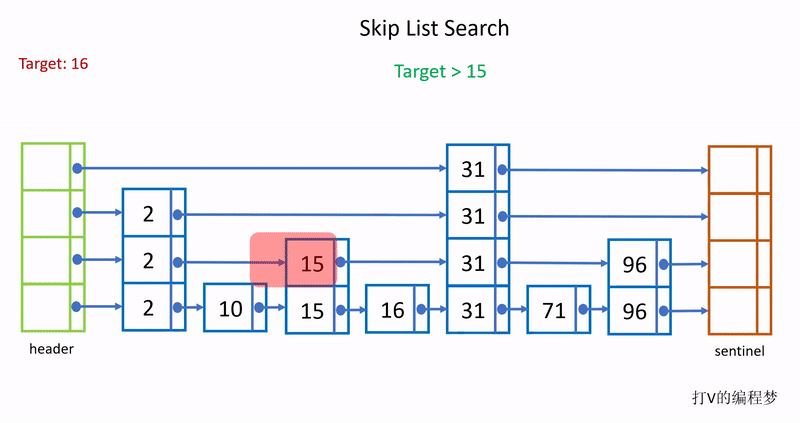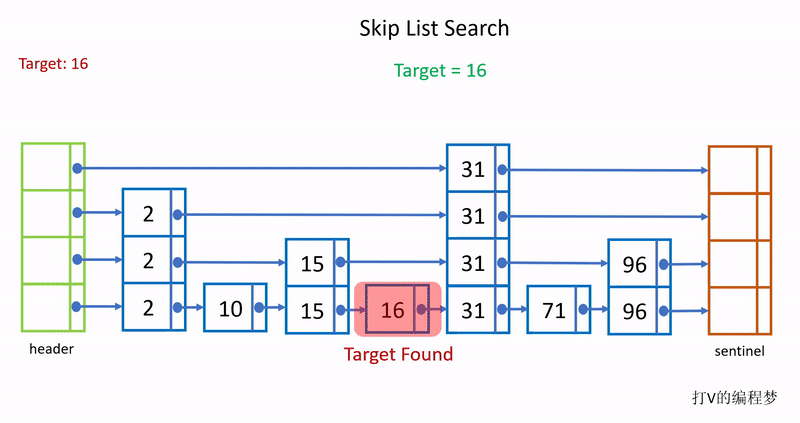
由于每往上移动一层,层级的节点数都会少一半,所以在层数越高的层通过指针跳往下一个节点过程中能跳过的节点数就越多,查询效率越高,例如我要查询96,查询时直接从头部跳到31,中间省略了对2、10、15和16这4个节点的查询比对。
跳跃链表的查询复杂度为 O(log n)。查询效率取决于我们如何插入新节点(如何决定该节点的层数)。
每次新增和删除节点的时候,因为需要将节点插入到合适的位置以满足有序性,所以新增和删除时都要先查后增(删),因此跳跃链表的新增和删除的复杂度也是O(log n)。
下面是删除的过程:
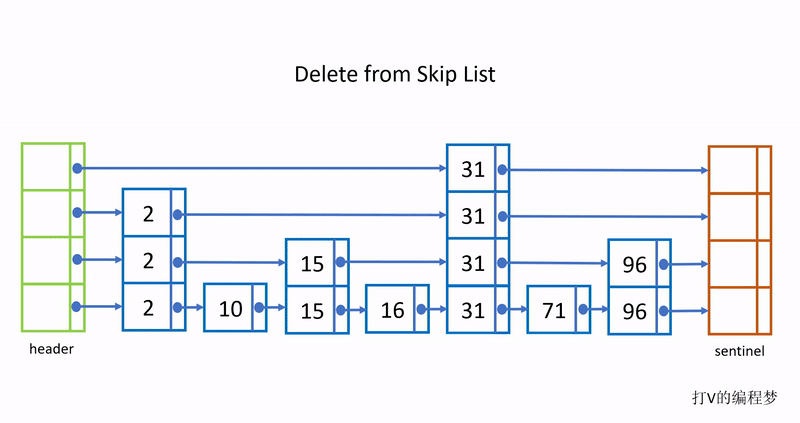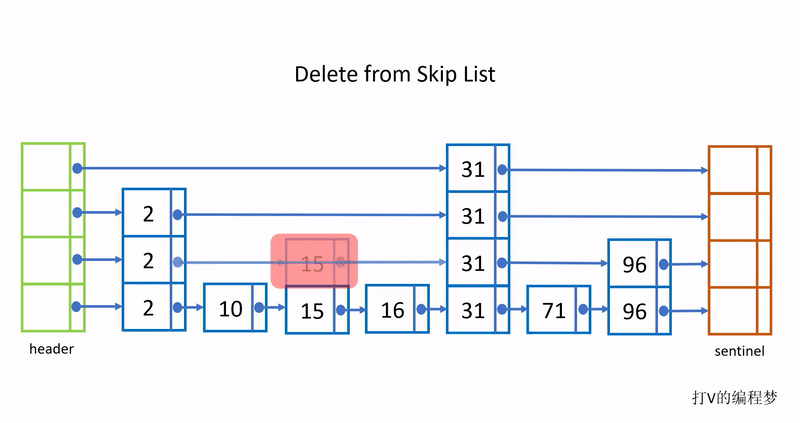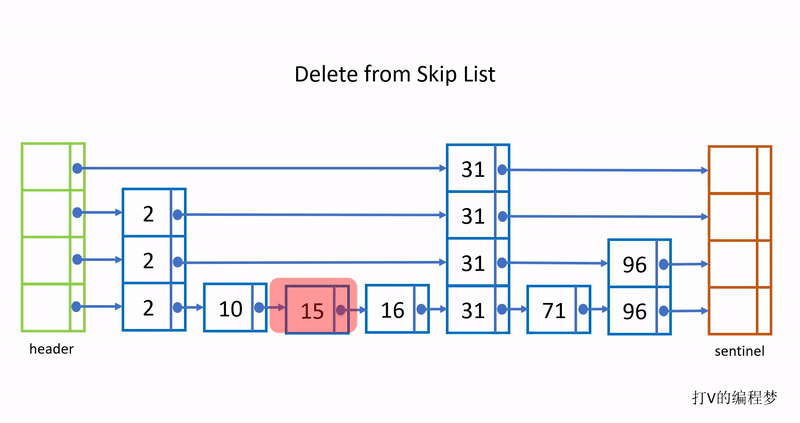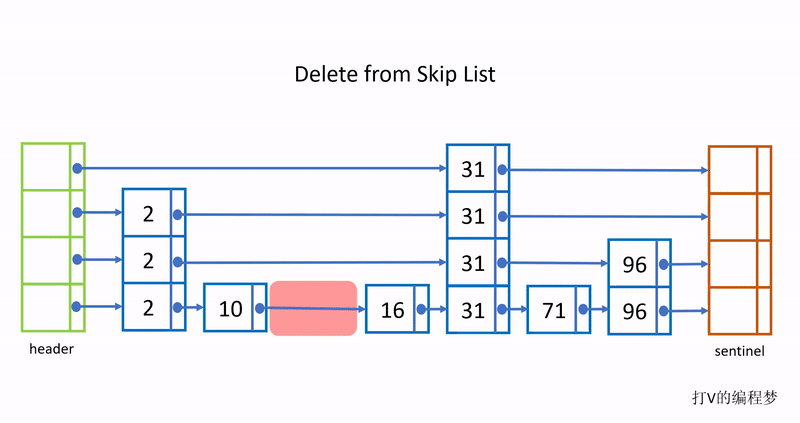
跳跃链表的优点是搜索效率提升到 平均O (log n) 最坏O(n),跟数组与二叉树的二分搜索法一样高效。
缺点是需要耗费更多的空间来储存各个节点和指针,并且插入与删除的复杂度为O(log n)。
redis使用跳跃表作为有序集合(zset)的底层实现。
下面我们看看redis中的跳跃链表:
// zskipNode
typedef struct zskiplistNode{ // 跳跃表节点对象
struct zskiplistLevel { // 层对象
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度
} level[];
struct zskiplistNode *backward; // 后退指针
double score; // 分值
robj *obj; // 成员对象
} zskiplistNode;
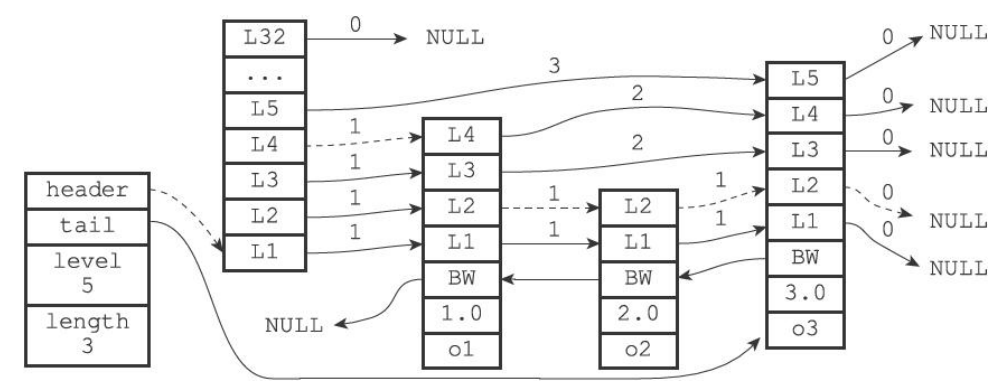
zskiplistLevel 层对象
每一个节点对象包含多个层对象(数组中多个层对象),每一个层有一个向前指针,以及这个指针指向下一个层的跨度。
层数越高,那么该层的指针的跨度越大,跳过的节点也越多(跳过的节点越多意味着查询到目标节点所需的查询次数越少),访问其他节点的速度越快。
层的最大高度为32,每个节点的层数是随机决定的,每一个层对象会作为数组元素放在zskiplistNode的level数组中。
backward 向后指针
每一层都有一个向前指针,但是向后指针只有节点才拥有,层是没有向后指针,后退指针(即图中的BW)只能跳到上一个节点,不能跨多个节点跳跃。
score 分值
节点的分值就是节点的值,也是节点查询的内容。
robj 成员
成员对象是一个指向字符串对象(包含SDS的对象)的指针。
节点在跳跃表中的排序就是先由分值决定,分值相同的情况下再由robj中的字符串排序。
zskiplist跳跃表对象
typedef struct zskiplist {
structz skiplistNode *header, *tail; // 表头节点和表尾节点
unsigned long length; // 表中节点的数量
int level; // 表中层数最大的节点的层数
} zskiplist;redis通过zskiplist对象管理跳跃表。