更多优质内容
请关注公众号
请关注公众号

·B树和B+树的使用场景
在介绍B树的特征之前,要先了解B树的出现是为了实现数据库高效查找而设计出来的作为数据库索引的数据结构。B树和B+树的适用场景就是作为数据表的索引。
为什么不用平衡二叉树作为数据库索引,难道O(logn)的查询效率还不够高?
其实从算法逻辑分析,平衡二叉树在查找操作上的比较次数是最少的。但现实中我们不得不考虑磁盘和内存读写速度的差距以及磁盘IO次数的问题。磁盘IO指数据从内存拷贝到磁盘或者从磁盘拷贝到内存。
我们知道数据库的索引是存在磁盘中,想利用索引查找数据时必须先将索引加载到内存,但如果索引有几个G我们不可能把整个索引加载到内存,只能把某一个磁盘页加载到内存,而一个树节点对应一个磁盘页,分散的存储在磁盘中,每个节点的磁盘地址是不连续的。
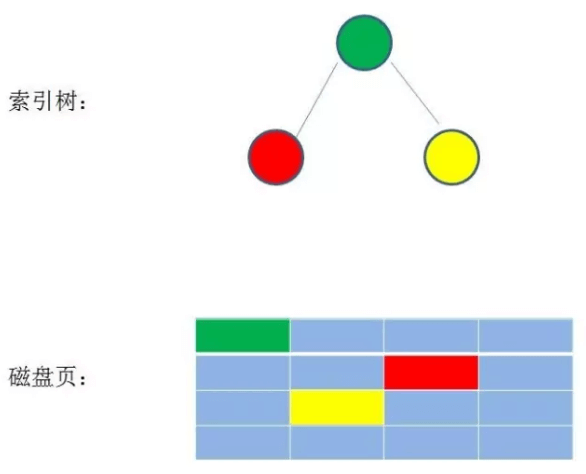
一般来说,索引树的根节点是直接在内存中的。
对于一个高度为4的平衡树,我想查找的某个值刚好位于树的叶子节点10,其过程如下:
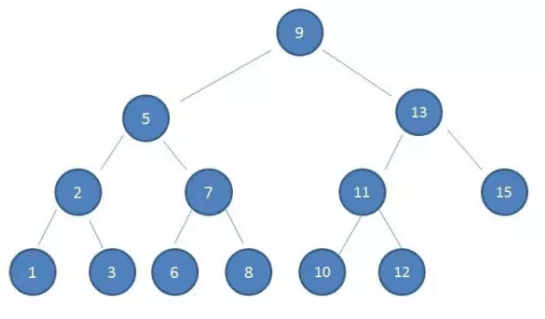
最坏磁盘IO的次数取决于索引树的高度,而磁盘IO的速度远慢于数据在内存中的操作,多次的磁盘IO会影响数据库查询的性能。
为了减少磁盘IO次数,需要将原本瘦高的二叉平衡树变胖矮,于是B树就出现了。B树是一个多叉平衡查找树,每个B树节点k个指向子节点指针和k-1个元素,最大的k是B树的阶,最大k的大小取决于磁盘页的大小,例如一个页(即一个B树节点)大小为4K,如果一个B树存的值类型是整型(64位),指针长度也是64位,则一个树节点可以有 4096 / ((64 + 64) / 2) = 128个元素,k≈128。
树的一个节点能容纳的元素个数越多,树的高度越小,这就是B树比二叉树矮的原因。另外B树又称为B-树(B杠树,不是B减树)。
下面是一个3阶B树:
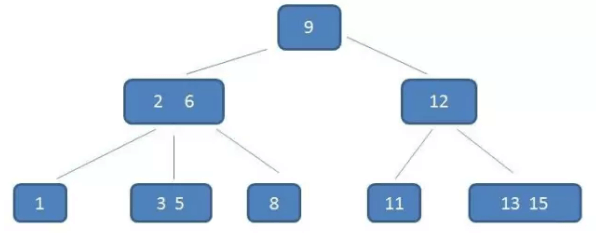
可以看出,这个B树的一个节点最多只有3个子节点,因此它是个3阶B树。
m阶B树有4个特征:
从B树的结构可以看出,B树在查询中的比较次数不必二叉平衡数少,尤其是单一节点中的元素数量很多的时候,但单节点内元素的查找是发生在内存中的,耗时几乎可以忽略,真正耗时的是磁盘IO操作,相同元素个数下,B树的IO次数(高度)比二叉树少,所以性能比二叉树高。
·B树的增删查
B树的增删查复杂度都是O(logn)。
查询
过程和BST类似,不过由于B树的一个节点有多个元素,而子节点指针又在多个元素之间,因此需要拿target值和当前节点的所有元素比较(或者用二分查找)才能找到下一层子节点的指针。
插入
和BST相同的是,B树的插入也要先查询,找到新元素的位置A,这个位置A肯定在叶子节点,再从A插入。BST与B树的插入都是从叶子节点插入的。
可以分成2种情况:
1.插入叶子节点后该叶子节点内元素的数量不超过m-1,此时无需做任何调整
2.插入叶子节点后该叶子节点内元素的数量超过m-1,破坏规则2,此时需要对叶子节点进行分裂,将节点 m/2位置的元素(即节点中间位置的元素)上升到父节点,余下的左右半边元素分成两个独立的叶子节点。如果上升后父节点也超过了m-1个元素则递归操作即可。
如下所示:
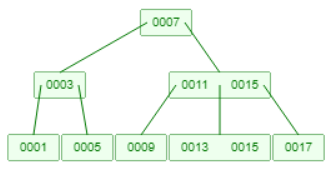
当插入12时,叶子节点的元素个数超过3个,需要分裂上升:
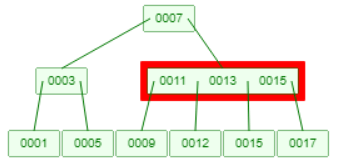
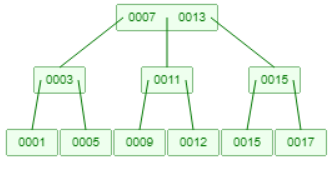
分裂后父节点的元素个数也超过3个,需要再分裂上升:
删除
需要分为4种情况。以下图的B树为例:
1.待删除元素在叶子节点,且删除后叶子节点的元素仍大于0(例如13),此时无需任何调整。
2.待删除节点在叶子节点,且删除后叶子节点的元素等于0,且相邻兄弟节点有多余元素(大于m/2),此时可以向左边或者右边的兄弟节点借调一个元素。
例如删除9,删除后不能把13直接调到9的位置,需要把13上升到父节点当中,再把元素11移到原本9的位置。
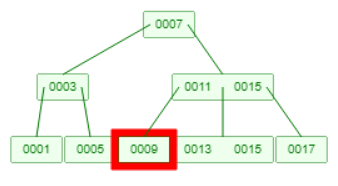
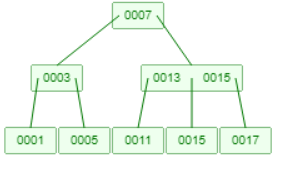
3.待删除节点在叶子节点,且删除后叶子节点的元素等于0,且相邻兄弟节点没有多余元素(元素个数小于m/2),此时可以向父节点借调一个元素下降到被删除节点的相邻叶子节点进行合并。
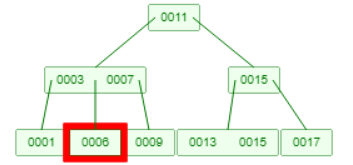
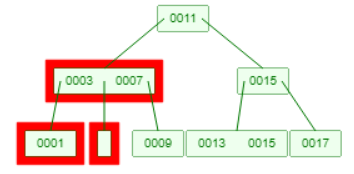
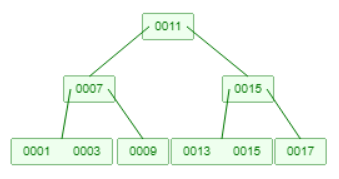
例如下图的B树删除6,此时3会下降到叶子节点1与其合并,或者7会下降到9与其合并:
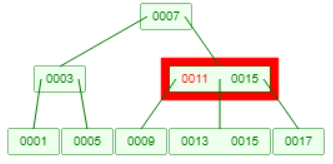
情况4:删除元素在中间节点,此时可以选择该元素的前驱元素(父节点的元素)或后继元素(子节点的元素)来顶替它的位置。
例如删除如下B树的11,此时父节点的元素不够了不能用父节点代替,用子节点的元素13顶替。
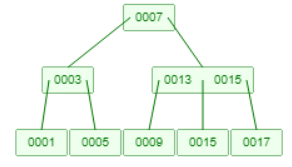
这4种情况只是最基础的情况,实际情况会复杂的多可能是这4种情况的结合,例如下面这个B树,删除元素5。
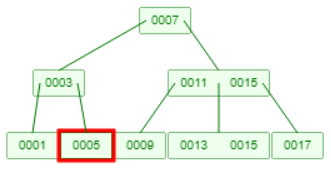
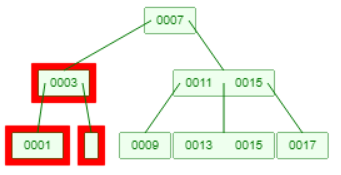
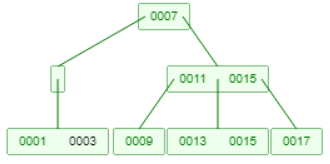
上图0001的父节点也空了,需要向相邻接点借一个元素11(相当于回到了情况2),11上升到父节点,7下降到左节点。
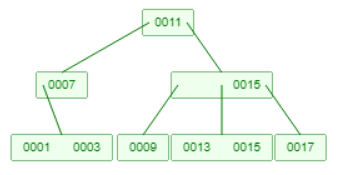
由于7缺少一个子节点,所以让9作为7的右子节点。7- 11 - 9的过程相当于发生了一次左旋。
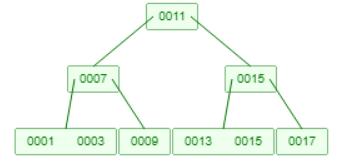
B树虽然可以改善数据库查询的性能,但是却存在一个不足之处:不方便进行范围查询。如果B树要进行范围查询,就需要对其进行中序遍历才可以。例如我要查[3,13]:
要先使用B树的查找找到3,从3开始中序遍历,遍历到13的时侯结束,一共发生了5次磁盘IO。
为了解决这个问题,B+树就出现了,B+树有以下特点:
1.中间节点具有k个元素和k个子节点(B树是k个子节点,k-1个元素)每个元素不保存数据,只保存索引,数据(是指数据库记录或者数据库记录位于磁盘的指针)保存在叶子节点。
2.节点内元素是有序的。
3.所有中间节点的元素也会存在于子节点(因此叶子节点包含所有元素)并且在子节点中是最大的或最小的。
4.同一层节点之间,每个节点带有指向下一个节点的指针(或者是双向指针),形成了一个有序链表。
如下图所示:
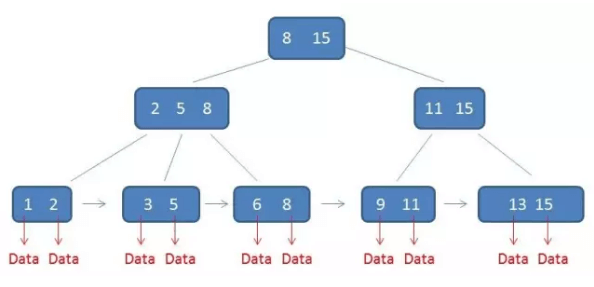
这些Data是卫星数据,卫星数据是指索引元素所指向的数据记录(数据库中的某一行),在B树中,无论是中间节点还是叶子节点都有卫星数据(或者卫星数据的索引),但在B+树中只有叶子节点才有卫星数据(或者卫星数据的索引)。
对于聚集索引,叶子节点直接包含卫星数据,也即是数据记录和索引是连续的存放在一起的,在非聚集索引中叶子节点只是带有指向卫星数据的指针。
·B树和B+树的比对
1.从单点查询来看,由于B树的中间节点除了存索引和子节点指针之外,还存了卫星数据,而B+树的中间节点没有卫星数据,因此一个同样大小的磁盘页(也是树节点),B+树的节点可以容纳更多元素(即索引),数据量相同的情况下,B+树会比B-树的层数更少,IO次数更少。
2. B+树的查询必须到达叶子节点(不到叶子节点拿不到卫星数据),而B树查找无论在中间节点或子节点找到就停下。所以B树的查找性能不稳定,而B+树每次查找都是稳定的。
3.从范围查询来看,B树要通过中序遍历,而B+树只需先找到左边界的节点并在叶子节点沿着邻接指针在链表上做遍历即可,因此范围查询的IO次数也会少于B树。
综合起来,B+树比B树的优势有3点:IO次数更少、查询性能更稳定以及范围查询更方便。
现实中,关系型数据库如MySQL使用B+树作为索引,而非关系型数据库如Mongdb使用B树作为索引。